

One day, you may be tempted to build and maintain an on-premises Kubernetes cluster. Don’t do it. That's my best advice. Instead, take a look at the managed cloud provider options like GKE, AKS, and EKS , which take away a lot of the pain and expense involved in maintaining and updating Kubernetes clusters. However, sometimes legal or business requirements mean that it's essential that your cluster runs on prem.
This blog post series takes a look at running an on-prem cluster and in particular how to configure networking. It will hopefully help you to answer some questions around prototyping and building on-premises network with minimal investment in physical infrastructure. I assumed the reader has some previous networking experience but all readers should come away with a greater understanding of how to effectively configure networking for k8s.
At some point, the networking industry started to release virtual versions of their appliances, including switches. This opened the door to spinning up virtual prototypes of physical network infrastructure that can be used for experiments and testing. In this blog, we’ll see how we can extend this to testing k8s networking, using Vagrant with Virtualbox, Cumulus VX as an IP Fabric building block, and a Kubernetes cluster running Calico networking.
The first post from this four-part series walks you through a bit of history of data centre networking and introduces the Calico networking plugin for Kubernetes. The next blog post will explain how to deploy a sample IP Fabric network for Kubernetes clusters with Cumulus VX and get it ready to deploy Calico for Kubernetes. Posts three and four will cover two scenarios for Kubernetes and Calico networking with IP Fabric.
All scripts and playbooks used in this blog post can be found in this repository, if you want to bring the whole environment up on your own workstation.
Data Centre Networking
In this past decade, data centre networking transitioned from a hierarchical to the fabric model. The fabric model supports a flattened system of switches and compute nodes, which allow any-to-any connectivity. This design addresses some of the inefficiencies and limited scalability found in the hierarchical model.
Hierarchical Data Centre Networks
In hierarchical data centre networks, each of the layers typically reflects the function of the network. The core layer is responsible for providing access to the outside world, while the aggregation layer provides IP routing functionality between the networks attached to the access layer. The access layer is the point of attachment for the servers to data centre network.
Here’s a model of what a hierarchical, legacy data centre network looks like:
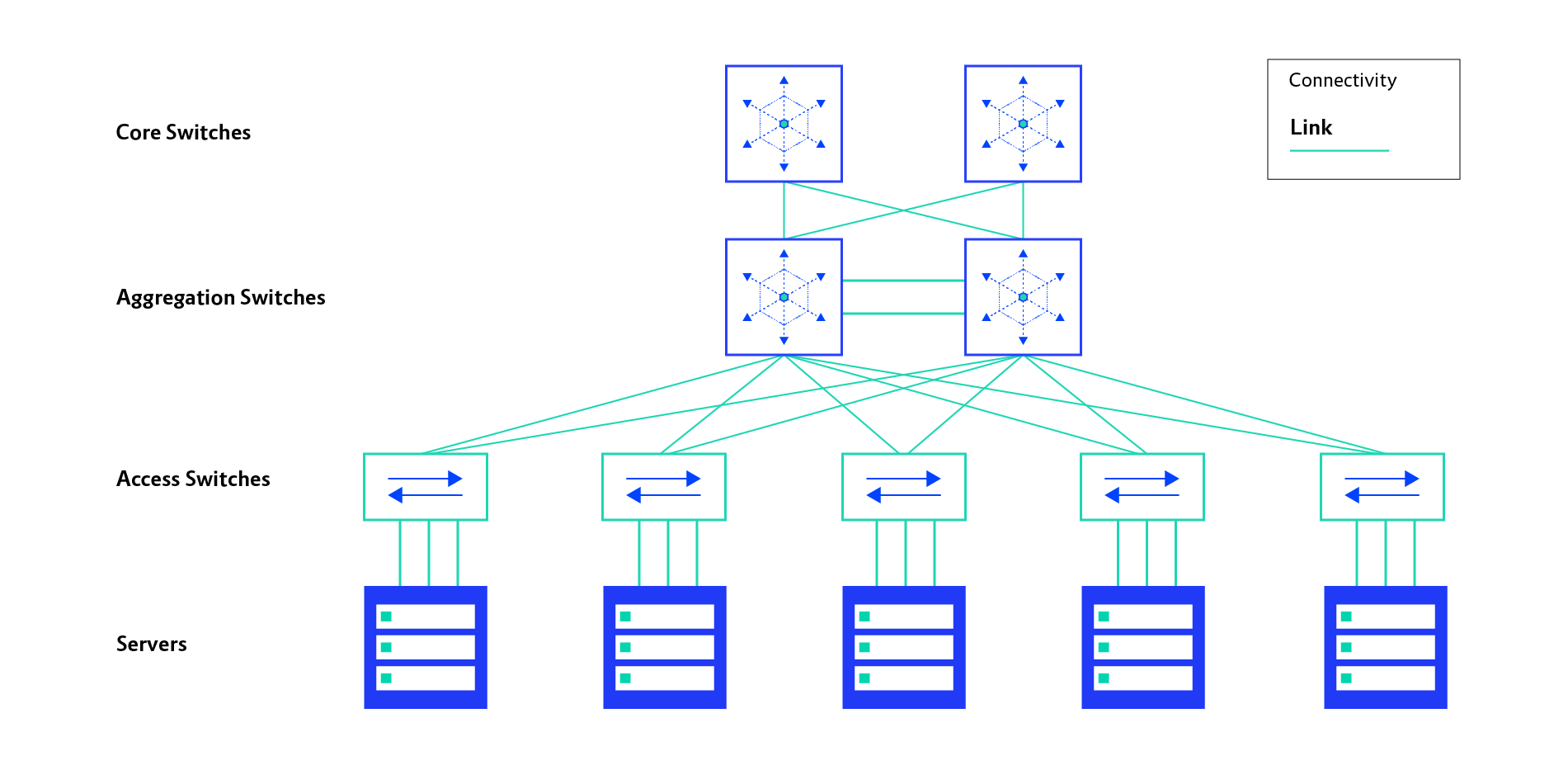
Inefficiencies in the hierarchical model are mainly related to limited scalability or suboptimal resource usage. Due to the need for loop prevention mechanisms, many links are not used, which means a waste of the potential bandwidth available.
IP Fabric as Data Centre Network
To address challenges found in the hierarchical data centre network model, the Clos network concept was applied, which resulted in the development of the IP Fabric model. Clos networks are an old concept that originated in the telecommunications industry and they have been around for a bit. In a nutshell, Clos networks have three stages named: ingres, middle, and egress. Each stage is built with crossbar switches.
Since IP Fabric is based on the Clos network, it also has three stages, as this illustration shows:
- Ingress and egress crossbar switches: called leaf switches
- Middle crossbar switches: called spine switches
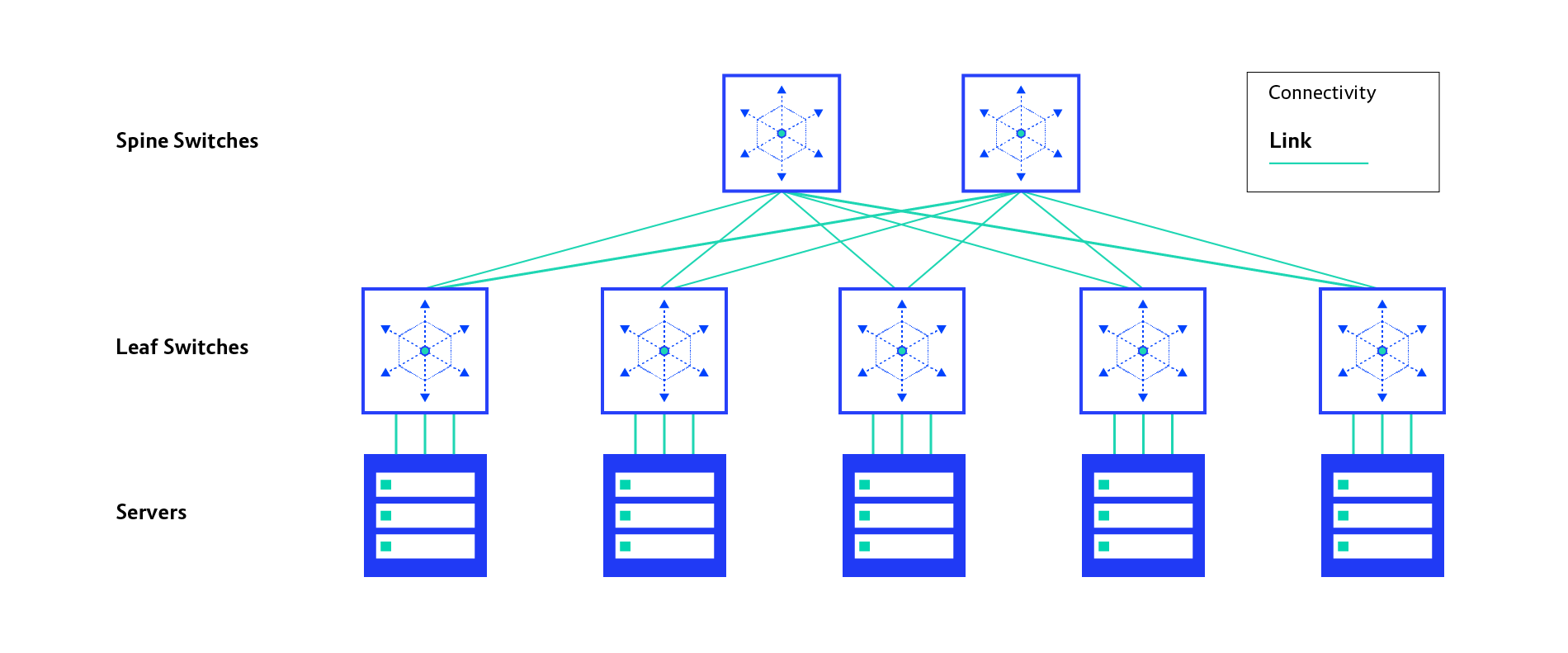
In its foundation, IP Fabric runs a standard IP routing protocol so it can benefit from equal-cost multipath (ECMP) routing. This creates multiple equal-cost paths between any two endpoints or servers. Scaling IP fabric bandwidth can be achieved by increasing the number of spine switches that adds more bandwidth available between spines and leafs.
IP Fabric has been proven to be a versatile building block for modern data-centre networks, as it is solid ground for network virtualisation or any type of overlay networks.
Kubernetes Networking with Calico
One of the most complete and mature network implementations for Kubernetes is Calico. Calico offers a complete solution, as it not only enables basic inter-workload traffic networking but also allows us to apply granular network policies. It can be run on various on-premises environments and public clouds.
Calico supports two main deployment models. The first one heavily relies on a Border Gateway Protocol (BGP) and doesn’t require any data encapsulation for Kubernetes inter-workload traffic. The big benefit of this approach is making your underlying network IP workload aware. This, however, implies a need for a routing information exchange between nodes and network with BGP.
For the readers that are new to BGP: It is a standardised exterior gateway protocol designed to store and exchange huge portions of IP routing information among autonomous systems (AS). It is a core protocol of the Internet and it is being widely adopted in data centre world. There is a great video by Jeremy Cioara explaining the BGP basics.
In order to achieve the highest performance, it is recommended to run the Calico network without overlays and encapsulation.
Overlay Network and Encapsulation
The second deployment model for Calico leverages data encapsulation and overlay network. BGP is not mandated to run it. A typical use case for overlay networks is when the underlying physical network is managed by a third party or it doesn’t support dynamic IP routing between Kubernetes nodes and network devices.
Calico is able to dynamically build overlay networks with VXLAN and IP-in-IP encapsulations on top of existing physical networks. Any inter-workload traffic must be first encapsulated into VXLAN or IP-in-IP and then put on the wire, so network devices can pick it and route to target the Kubernetes nodes.
Next in this series, we’ll deep dive into setting up IP Fabric on Cumulus VX and spinning up a Kubernetes cluster on top of it.
We have our first-ever book coming: 'Cloud Native Transformation: Practical Patterns for Innovation'. Click below to pre-order now!
