

Working as a consultant in the IT industry, sometimes you get a project that you get very excited about. I recently had this opportunity. At first glance, this company might appear to be a very difficult place for a modern developer/DevOps engineer to work. It’s a large corporation, subject to a lot of regulation and bureaucracy. But it has something special going for it: Its leaders are open to change.
Now, this blog post is not about that particular company, but more on the approach our Container Solutions team took to deliver its new Cloud Native platform.
To understand the task in front of us, you need to understand the scale. We would be creating a system that would be receiving millions of requests a day, and had to be operated by a very small team—only two or three people.
As is common nowadays, the client had opted for a microservices architecture, and the applications were already built and running in a test Kubernetes environment. The requirements for us were to create a system that allowed for quick rollbacks, audit logs of changes to the system, and a review system for any potential changes. All while still allowing for team collaboration.
The small team also meant that doing anything manually was just not an option. After a couple of discussions (and there were a lot) we finally decided to attempt to use a Git-based workflow to handle these needs— in short, GitOps.
Why GitOps?
GitOps is the automated operations of your infrastructure through your git workflows, it allows for making changes to your infrastructure/applications through Pull requests and tags. GitOps gives us a lot of power when it comes to automation. Some of the upsides that we leveraged in this project are:
- Audit log of changes: All changes go through a pull request that has to be approved before being deployed. Every change is tied to a commit that is done by a specific person.
- Rollback: The rollback strategy becomes super simple. You can revert the breaking commit/pull request, which in turn should run the pipeline to fulfil the current state.
- Access management: Your access is determined by Git repo access, which in most development teams is already pretty well defined.
- Collaboration: You can allow anyone within the organisation to read the current state and open a pull request against the infrastructure, This allows teams to propose changes that the infrastructure team can then just review, essentially turning any person in the organisation into someone who can help with operations.
- Source of truth: You have a single source of truth of the state of your infrastructure in a declarative way, which means at any point in time you can refer to your repo to see what is running.
- Stability: Changes to the infrastructure are made in the same way, through automation.
In our planning, we decided the best way to handle this would be to split the functionality into two separate Git repos: one to handle the changes of the infrastructure (called the ‘infrastructure repo’) and one to handle the application-level deployments (called the ‘11th Repo’—more on the name later).

The Infrastructure Repo
The idea behind this repo was to handle all the infrastructure components, including everything that applications needed to run (Kubernetes, databases, networking, etc.). Choosing which components are handled within this repo entirely depends on the overall setup of the application and the environments that it needs.
One thing that we at Container Solutions feel is super important is the ability to experiment. Any changes in configurations should have an environment that engineers can break. The downside of this is, if you manage your infrastructure in the same environments that you manage your applications, then every time you break the infrastructure’s ‘staging’ environment, then you could potentially be blocking entire teams of developers. Hence, this is why we decided to go for a Ops/Apps model.
The Ops/Apps model is not something new, it's just a new name for an older idea. It is the same as Staging/Production. However, we name it Ops/Apps so that we separate the concept from the applications that will be running. Quite simply, the idea is that for every component you run, you also run a shadow component that is as similar as possible, to test changes against.
If you apply this to Kubernetes, you would have your cluster that runs all applications, then a second cluster that is identical—except it has no applications. In the cluster that runs all the applications (the ‘Apps’ cluster), you could segregate the application environments via namespaces and, if you were required, you could segregate the workloads even further by nodepools, network policies etc.
The Ops cluster will probably have fewer nodes but will still run essential components, such as an Ingress and your monitoring stack, as these are the things that, if changed, have the potential to break applications.
Now taking this concept to the other components is difficult. Inside a Kubernetes cluster, for instance, you can separate the environments, but with components such as databases, you would need a separate instance per application environment (staging, prod, and preprod). What we ended up doing is creating a Ops/Apps pair per application environment (staging-ops/staging-apps, preprod-ops/preprod-apps, and prod-ops/prod-apps).
This eventually looked something like this:
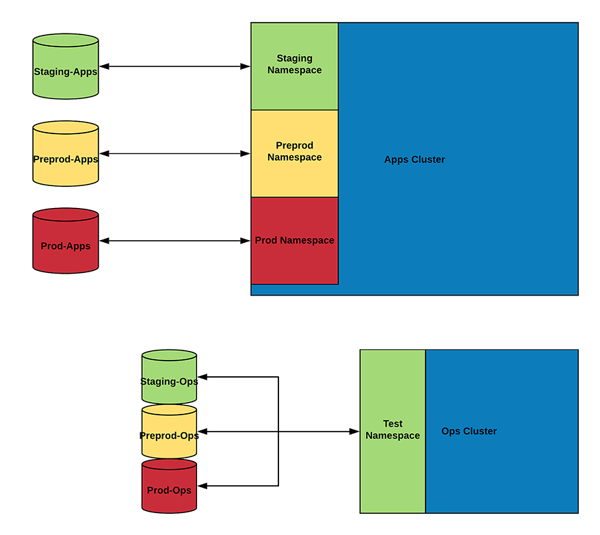
(If viewing on mobile device, you can download a PDF of this diagram here.)
The reason we decided to go this route was that, in this setup, the production components were vastly different to the staging components. For instance, your production might have high availability, or different backup features, whereas the staging/preprod might be simpler.
Now, for the platform team, the staging application environment uptime was just as important as the production uptime, as any downtime at the staging application environment meant blocking a large number of engineers. Therefore, by creating these Ops environments for each Apps environment component, the operations team had a testing environment for every component before promoting the change to the component that was actually in use
The immediate downside of this is cost. Running this model for every component means you could be potentially doubling your infrastructure costs. But at the same time, you would be saving costs on application developers having everything they need to keep releasing those features. The argument here (not that I'm going to go deep into it) is the cost of reputation damage that downtime due to a breaking change could cause.
Back at the client, as we were running on one of the big cloud providers, almost everything was available as a Terraform provider. This allowed us to build a very simple pipeline along with using Terraform workspaces to split the Ops and Apps environments. Essentially the Git strategy look as follows:
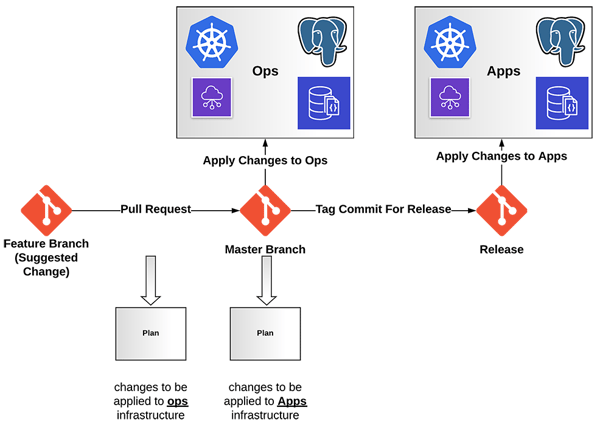
(If viewing on mobile device, you can download a PDF of this diagram here.)
This allowed anybody that wanted to make potential changes to see the effect on the larger scale of things, using Terraform’s planning functionality via a pull request. And then, once merged, it would automatically be applied to the Ops environment of the component. Once the changes had been made and tested then creating a tag would deploy the changes to the applications environment.
The ‘11th Repo’
Earlier, we introduced this repo as a deployment repo. This is generally something that has become commonplace in most GitOps setups and introduced early on by WeaveWorks. However, it was a new concept for the clients team.
So we ended up describing it as an additional repo that pulls all the versions of your microservices together. The name ‘11th Repo’ simply comes from the fact that the current app had 10 services. (This logic quickly fell apart when the clients team added another service, but by then the name had stuck.)
There was a lot of pushback on this setup, the client's team had a variety of misconceptions about what microservices are and ideas about how they should operate. Our idea was to put the manifests (Kubernetes configurations) for every microservice in this one repo. These manifests mirrored what was in the services, and any update to the services manifests would be pushed to this repo as well.
The upside to this is that you have a Git-versioned state of your infrastructure every time you update (Service A works with Service B in commit Z). Yes, the clients first comment was that microservices should not have dependencies on one another, so versioning them together was a bad idea. However, in reality, though we often strive to minimise dependencies between microservices, fully achieving this is extremely difficult and, in the long run, one or two will sneak in.
The main reasoning behind this approach is this allows for promoting all the services into production that have been tested together in staging, knowing exactly what recipe of services worked together at a point in time. This also allowed for the promotion of images which (in my opinion) is a cornerstone of GitOps—because if you rebuild an image, you would then need to test if that specific version of the image worked. We used the Commit SHA to tag the image, which means that every commit that makes it to master will have a corresponding image that can be released, and you can pinpoint which commit it references by looking at the manifests in the deployment repo.
Some feedback that we got from the developers was that they felt that their microservices were no longer independently deployable, as they depended on this secondary repo to deploy, even if this was all automated.
When we did a proof of concept of this setup, we had multiple microservices deploying. The only downside was that each deployment went in a queue-type system, so each previous deployment had to finish before the next one could deploy (mainly because the CI/CD system had a single worker). You could still see your service being deployed within five to 10 minutes of your changes being pushed. The pace of deployment was not really an issue at this point in time, as it was largely determined by the team sizes, and there were review processes in place before promoting the recipe of services to the next environment.
As the applications had three environments, the branching strategy for this was slightly different. We had all feature branches on a service deploying to the staging environment, this was a test environment and we did not promote images from this environment. The master branch deployed to the pre-prod and a tag deployed to production, the main idea being that you deployed the exact same image that you tested in staging into production.
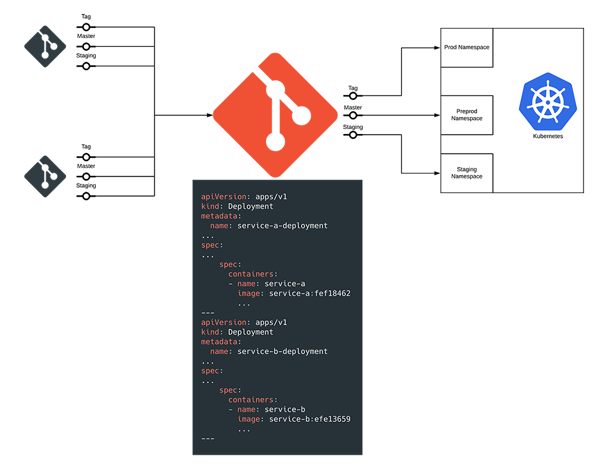
(If viewing on mobile device, you can download a PDF of this diagram here.)
The one large downside to this pipeline is that, to add a service, you just need to add the same CI/CD script to a new service and put the manifests in a directory. Currently, however, removing the service is an entirely manual process, by making a commit to the 11th repo to remove those manifests.
Conclusion
This setup has proven to be quite robust in terms of finding bugs before they affect any development process. This is not to say we did not hit some road blocks along the way. Oftentimes, when we go into an organisation, it’s more about changing how the organisation works, which is a task within itself, than just setting up awesome new automation pipelines.
In this case ,we had to do some navigating of the process and procedures in order to get the most benefit out of this way of working, In the end, for what we wanted to achieve, which was mainly automating the entire system so two to three people could manage it, I would say it was a success
Resources
Photo by Marcello Gennari on Unsplash

Enjoy our content so far? Please make sure to subscribe to our WTF is Cloud Native newsletter:
