

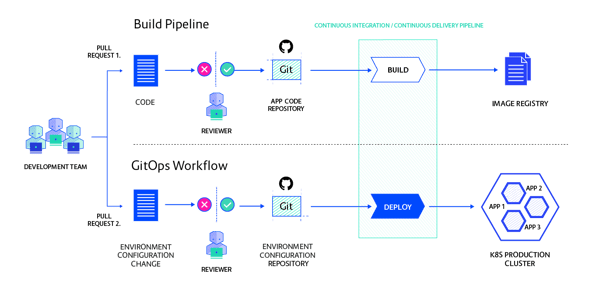
Kubernetes allows us to manage our application deployments and other infrastructure components purely using declarative configuration files (e.g. we’re all YAML developers now). This enables us to put all these files into a Git repository, hook it up to a pipeline (Jenkins, GitLab, etc), which will apply those changes to a cluster—and voilà, we have GitOps.
(You can download this graphic here.)
To make this work, we have to make sure that the only way to change the cluster is with a commit on the Git repository. GitOps is not Kubernetes specific; the same principle can be applied to environments managed by Terraform and CloudFormation or any other declarative configuration management.
Arguably, a lot of people are already doing GitOps, but now is the time when the industry is starting to fully realise the potential. So let’s dive into the reasons why it’s so great!
1. Stored history of environment changes
An application environment can only be changed by updating the configuration in the corresponding Git repository. This creates a full history of desired state changes, including a record of who did the change and why. Reading the history is done using the Git user interface you already use and love.
2. Easy rollback to a previous state
Once all our changes are stored as Git history, it becomes easy to roll an environment back to any previous state. By reverting some commits, we can step back to a state that used to work previously.
3. Secure deployments
Once all changes to the cluster go through the GitOps repo, users and the Continuous Integration (CI) process don’t need access to the cluster anymore. This reduces the attack surface greatly, especially if it also allows reducing network access to the Kubernetes API.
The deployment process, regardless of how it is implemented, can run inside the cluster and pull the configuration from Git. Its access to the API is limited using Role-Based Access Control, or RBAC. This greatly increases the security of the cluster by preventing any malicious remote changes over the all-powerful API server.
4. Lightweight approval process
In many companies, developers are not trusted to modify production environments. Whatever the reason behind the requirement to have four-eyes approval processes in place, GitOps offers an easy way to implement them.
The exact implementation depends on the Git server you use, but the point is to give the developers the rights to create pull requests on the Git repo while giving another group the right to review and merge. Most Git servers have an excellent UI to inspect changes and approve pull requests—so not only is this solution cheap, but it’s also quite user-friendly.
5. Modular architecture
GitOps has three parts: the Git repo, the deployment process, and possibly a process that automates version updates in the Git repo. All three of these can evolve or be replaced independently of each other.
On one side a component is writing to the Git repo and on the other side, a component is reading it. The structure of the Git repo becomes the contract between these components. As this is a pretty loose coupling, both sides can be implemented in different ways, with different technology stacks.
6. Tool-independent architecture
The modularity mentioned in point No. 5 directly leads to the fact that a GitOps architecture is one where you can assemble the best tools in a flexible way. Any popular Git server will do the Git part of course, and Flux or ArgoCD can take care of syncing the repo to the cluster. JenkinsX is a tool which handles all parts of this process, including creating the Git repos and updating them with new version updates when a new Docker image is built.
7. Reuse existing knowledge
By putting Git at the heart of your deployment process, you can capitalise on the knowledge most developers and operations people already have about Git. No need for new tools to browse deployment history or implement an approval process. Everything happens using tools everyone knows and loves.
8. Compare different environments
When you have a chain of environments from development through User Acceptance Testing (UAT) to production, it can be a hassle to keep track of the differences between these environments. Thanks to declarative configuration stored in Git repos, it’s as easy as comparing a set of YAML files to each other.
We have very good tooling to do this, so it won’t be an issue any more. What’s more, creating a new environment from scratch is as easy as copy-and-pasting those files into a new repo!

9. Backups come out of the box
As the state of your environment is stored in Git, you will never lose it if something happens to etcd on Kubernetes. It’s a natural backup of your cluster state.
10. Testing your changes like app code
You can test possibly breaking changes to your environment the same way you test application code. Put the changes on a branch and run a CI pipeline on it. Your CI tool will be able to run tests and set the pull-request status in Git to green or red, depending on the test results. Once everything is tested and reviewed, you can merge to master.
This sounds very straightforward but automated testing is an often-neglected task in infrastructure management. GitOps doesn’t make it easier, but at least it gives you the same familiar workflow you use in other places.
11. Highly available deployment infrastructure
Deployment infrastructure is important to keep up. Git repository servers are usually already set up in a replicated, highly available way. Source code is something all developers need access to most of the time, so using Git as the source for deployments doesn’t add an additional burden on Git itself.

Further reading:
Enterprise-Grade CI/CD with GitOps
Building a Large-Scale, Continuous Delivery Platform: a Case Study
