

I recently spoke with the developers of Humanitec, a Continuous Delivery platform for Kubernetes. Humanitec is interesting because, contrary to recent trends, it’s not based on a GitOps deployment workflow.
I’m a big proponent of GitOps— it is an approach that sidesteps complex tooling in favour of building CI/CD using a combination of Git and declarative configurations. I recently wrote an article about ‘11 Reasons for Adopting GitOps,’ but I also experienced the approach’s limitations on different client projects. Talking to the Humanitec folks prompted me to write about my negative experiences to help paint a more objective picture of GitOps and highlight another possible approach.
What’s Not So Great About GitOps?
Not designed for programmatic updates
Applications in a Continuous Delivery process get updated frequently and you have to automate the updates. When the Continuous Integration process ends with requesting a release to the test environment, the CI process has to create the pull request.
Git, however, is designed for manual editing and conflict resolution. Multiple CI processes can end up writing to the same GitOps repo, causing conflicts.
These conflicts are not conflicts on individual files, but rather two processes cloning the repo and one pushing changes sooner than the other. When the other process tries to push, its local copy will be outdated, so it has to pull, and try the push again. At this point, it might conflict with yet another process if the system is sufficiently busy. This is caused by how Git works and you can mitigate it by using more repositories (e.g., one repository per namespace).
On a real-world project, my team ended up building a sophisticated retry mechanism in Jenkins Groovy script to solve this problem,at significant cost.
The proliferation of Git repositories
Depending on how you map GitOps repositories to application environments (see the previous section) the number of Git repositories increases with every new application or environment. You have to create all these repositories with the right access rights, connected to the sync agents on different clusters. (A sync agent is the agent process or pipeline, which monitors the GitOps repository and syncs its content to the right application environment.)
In a complex enterprise environment, a team I worked with spent more than 30% of the development time building automation for provisioning GitOps repositories. You can mitigate this problem by using fewer GitOps repositories—such as, one repository per cluster. This increases the pressure on what a single repository has to do in terms of access control and pull-request management. Most importantly it exacerbates the programmatic update problem from the previous point.
Lack of visibility
GitOps promises visibility into what’s going on in your environments because all the intended state is stored in Git, where you can see it in plain text. This only works for relatively simple setups where a few GitOps repositories contain a manageable number of configuration files.
In an enterprise environment, the number of GitOps repositories and/or configuration files will grow enormously. As a result, combing through text files is not a viable option for answering important questions. For example, even the question of how often certain applications are deployed is hard to answer in GitOps as Git repositories changes are difficult to map to application deployments. Some changes might result in the deployment of multiple applications, while some only change a minor configuration value.
Doesn’t solve centralised secret management
Complex enterprise environments need a solution for managing secrets outside of the normal CI/CD process. Secret values such as private keys or passwords for accessing databases need to be thoroughly audited, so keeping them in a centralised secure storage like Hashicorp Vault makes a lot of sense.
GitOps doesn’t stand in the way of this approach, but it doesn’t help much either. Git repositories are not great places to store secrets, as you have to encrypt and decrypt them. Secrets are also remembered forever in Git history. Once the number of Git repositories expands, secrets are spread out over a large number of repositories, making it difficult to track down where you need to update a certain secret if it changes.
Auditing isn’t as great as it sounds
GitOps repositories are great tools for audit processes, as they store the full history of all changes. So answering the question ‘What happened to this environment’” is easier.
However, because a GitOps repository is a versioned store of text files, other questions are harder to answer. For example, ‘What were all the times application X has been deployed’? would require a walkthrough of Git history and a full-text search in text files, which is difficult to implement and error prone.
Lack of input validation
If a Git repository is the interface between the Kubernetes cluster and the CI/CD process, there is no straightforward way to verify the files that are committed. Imagine if instead of a Git PR you make an API call. In that case, the validity of the request is checked, while in the case of GitOps it’s entirely up to the user to make sure the manifest or Helm files are correct.

A Different Solution?
All these downsides don’t mean GitOps isn’t a good solution for releasing applications and configuration changes. It is an approach that provides a lot of benefits without locking you into heavyweight tooling choices. You just have to be mindful of the problems you will encounter on your journey and factor them into your choices.
So what is a solution that takes all the good stuff from GitOps while improving on the downsides? Let’s look at what we want to keep first:
- Log of all environment changes
- Description or configuration of environments stored in a declarative format
- Approval process for environment changes
- Control who can make changes to environments
- View intended state of an environment, and verify if it differs from the real state.
As mentioned earlier, the problem is that even though Git offers these features, it isn’t designed for frequent automated changes. It isn’t suited for analysing the data stored in it. An obvious alternative choice is an API service backed by a database and the same agent-based sync process as in the GitOps setup. (If you are reading this on a small screen, you can download this diagram here.)
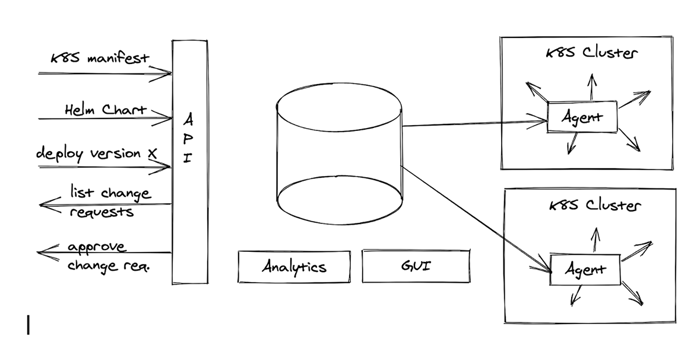
The database stores all previous versions of the manifest files or Helm charts. This way, it is possible to have a large number of updates on the API without the ugly conflict-resolution process needed with Git (unless we run into real conflicts, which is rare in this scenario). The change-request approval process is implemented using API calls and database fields. RBAC is similar.
This is all costly to implement. However a lot of good features can be realised:
- Structured search on the database (How often does application X get deployed?)
- Single centralised system handling all environments: No Git repo proliferation.
- Manage configuration values over many environments easily. Have hierarchies of configuration values.
- Implement or integrate with centralised secret management.
- Validate inputs
Because the above-mentioned solution is much more expensive to implement than a GitOps-based one, one has to either build a complex internal tool, or rely on a third-party one.
Spinnaker is the most popular of such tools, while Humanitec is the next generation fully focused on Kubernetes. It has some of the above features realised, and others on the roadmap. We see great potential in such systems as the alternative to GitOps.

Enjoy our content so far? Please make sure to subscribe to our WTF is Cloud Native newsletter: