
About a year ago, we at Container Solutions started our engagement with FiduciaGAD, the largest IT service provider for banks in Germany. The focus of this project is to build a Continuous Integration/Continuous Delivery platform for development teams across the organisation.
As a new OpenShift-based cloud platform was being put into production, our job was to develop the technology and best practices to make development teams work efficiently. Here are four important design decisions we made during the project, and the effects they had.
Decision No. 1: Independent microservice delivery as default process
Our main challenge at the start of the project was to decide what kind of workflow(s) we would support. When we started the project, we learned that a lot of decisions hadn’t been made yet.
It wasn’t clear, for instance, whether the development teams would be ready to develop and deploy microservices independently, or if they even wanted to aim for Continuous Delivery. Many of the developers we learned, had no experience with Docker, Kubernetes, or OpenShift. Previously, they did not have to manage their own infrastructure to the extent that Docker and OpenShift requires.
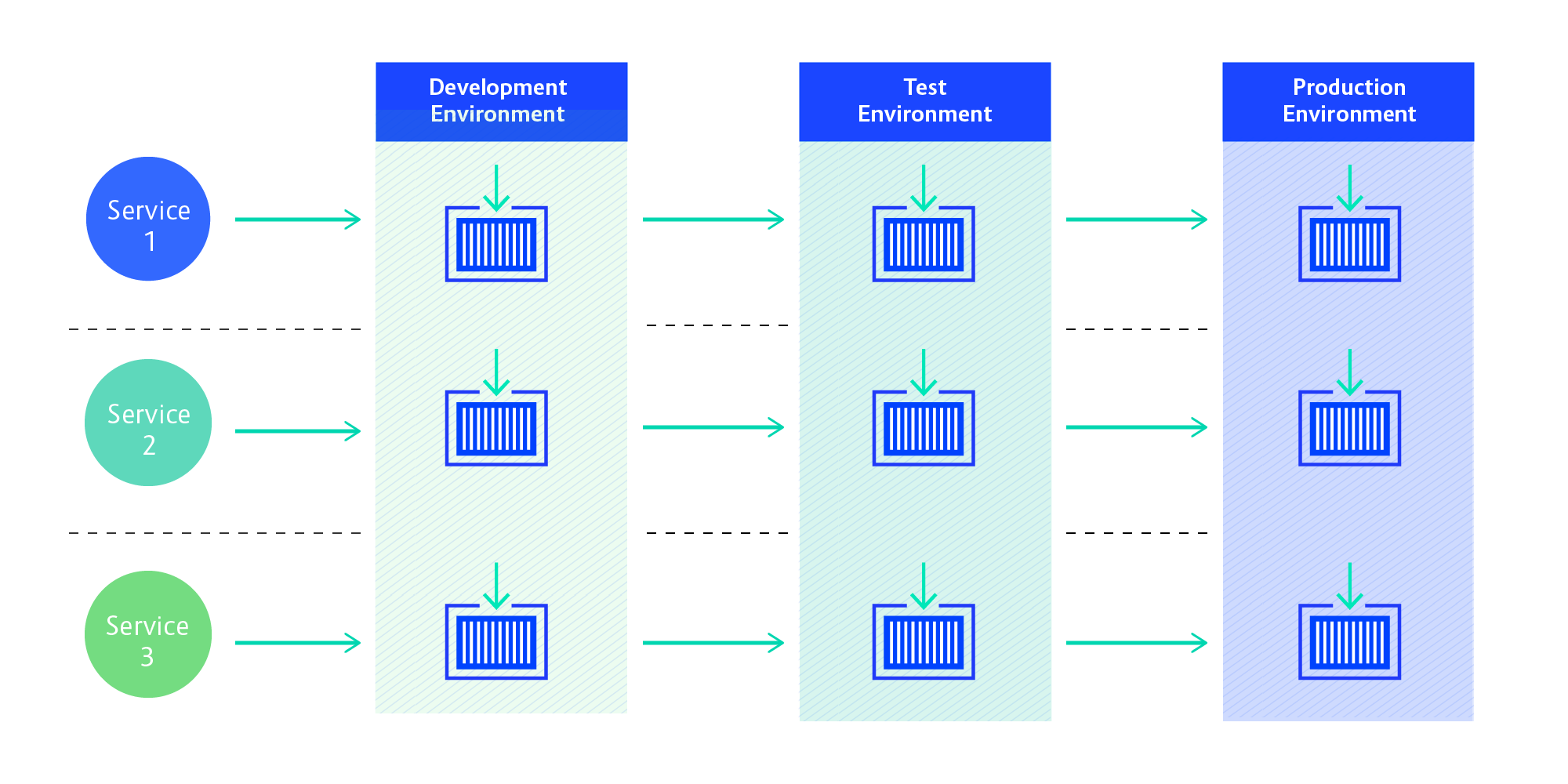
The general consensus among the leaders of the project was that the applications running on OpenShift would be built as microservices. Because microservices go hand-in-hand with CD, we decided to create a per-microservice CD process as the default.
We expected not all development teams to be cool with this. But our reasoning was, if we give them a different process to start with, they’ll never make the next step and might very well end up building microservice monoliths. If the pushback comes, we thought, we’d be able to handle it by helping teams create alternative processes that are only as much a step back as is necessary.
We implemented the microservice delivery pipelines using Jenkins and the Pipeline Plugin. Jenkins Pipelines enable declarative configuration of the steps required to get the application from code to production.
Decision No. 2: Segregating deployment services
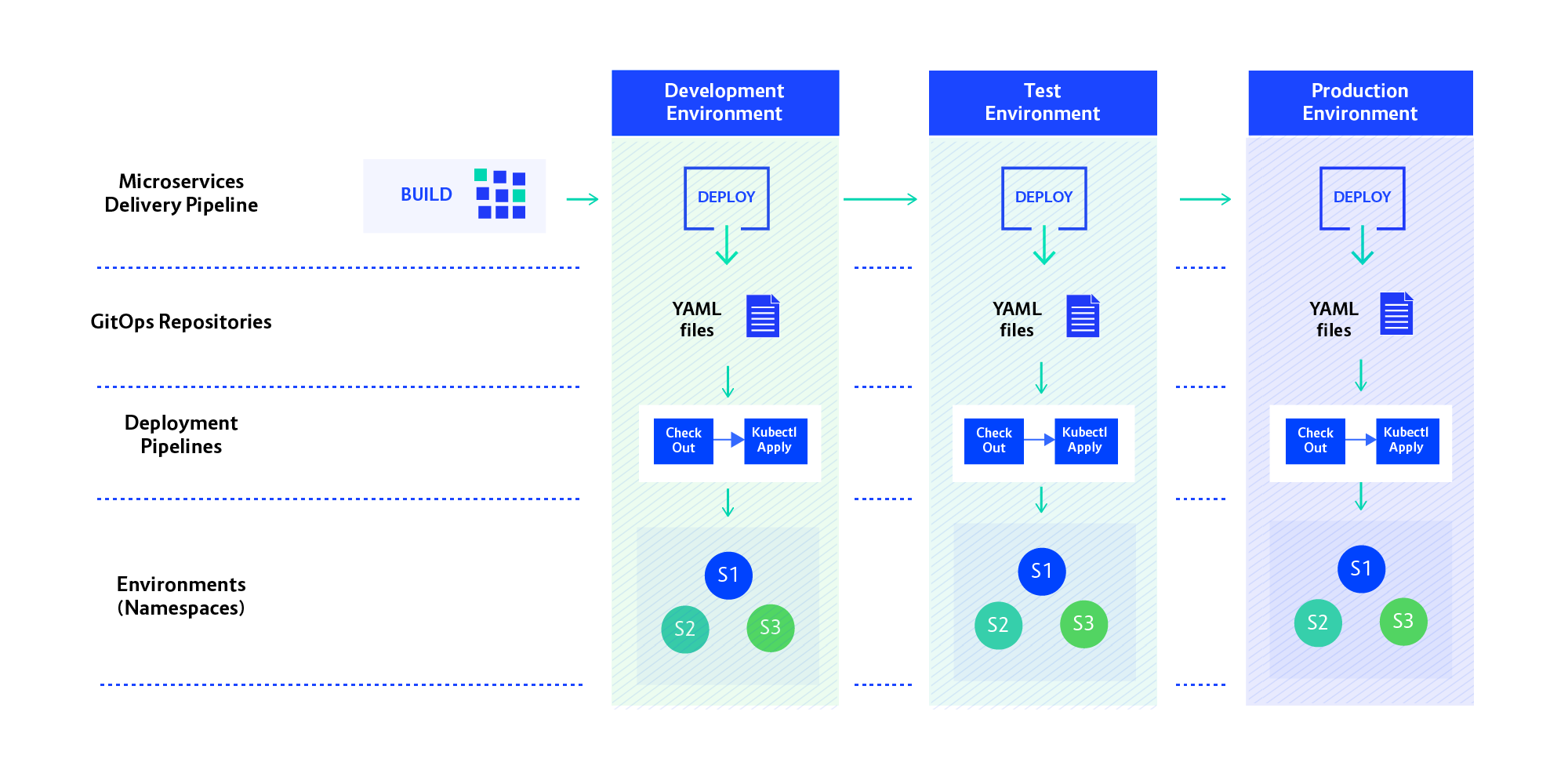
As mentioned previously, our target infrastructure was several OpenShift clusters, on which we create namespaces for teams; a team might have namespaces on more than one cluster. The CD pipelines became the glue between these to transfer applications through testing stages to production. Our first challenge was to create security barriers between the developers and (mainly) the production environments.
We decided to resolve the segregation problem by putting Git between the Jenkins, which runs the CD pipeline, and the actual namespaces on clusters. Each namespace on OpenShift gets a corresponding Git repo holding its intended state and will be deployed to when this repo changes. The CD process running in the team’s Jenkins will be creating pull requests against this repo. This pattern is called Gitops and provides us with an audited and secure demarcation line between the CD workflow controlled by developers and the deployment process, which is security-sensitive.
At the same time, it allows developers a lot of flexibility in shaping their own delivery process, as they have full control over their Jenkins instance. You can read more about this architecture in my previous blog post.
Decision No. 3: Building our own CLI for provisioning CI/CD
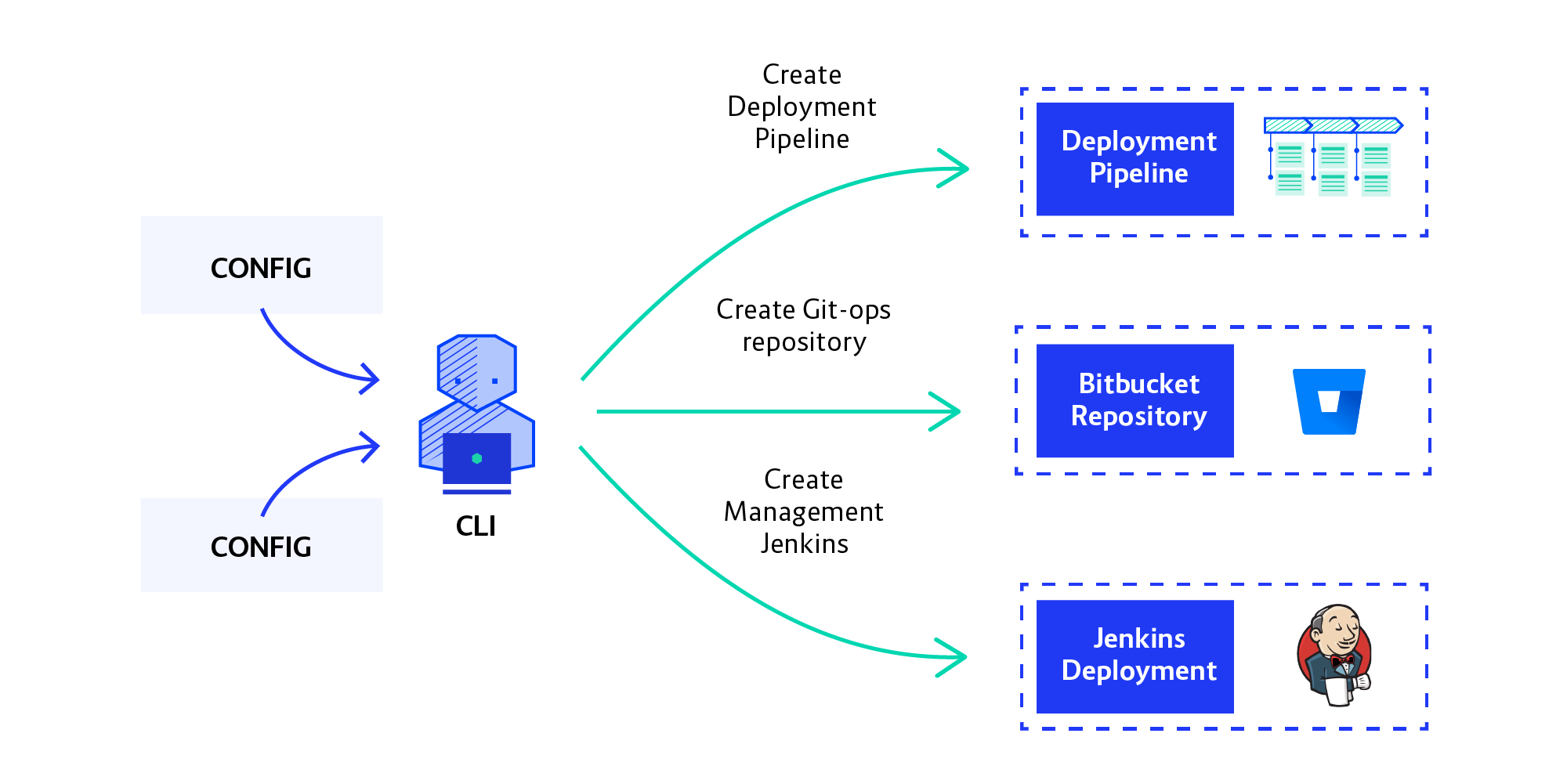
Our next challenge was to automate the setup of the pipeline. Manually creating instances of the CI/CD system wasn’t sustainable, of course. We first gave it a try with Terraform but ran into so many issues (including the departure of our only experienced Go developer) that we decided to just write the provisioning as a CLI tool in Java.
Switching to writing Java (in which the team is proficient) from writing Terraform plugins in Go, gave us a huge productivity boost. It turned out the flexibility you get from using a general-purpose language as opposed to a configuration management tool can be very handy, especially for abstracting problems. (By the way, the resources we were provisioning were not supported by Terraform without writing custom plugins.)
Our CLI tool takes the declarative definition of a development team—with a list of their environments—and creates all the resources on all the OpenShift clusters the team will need. This includes their Jenkins instance, namespaces on OpenShift, and Git repos in Bitbucket for holding environment state and change history (we call these Ops Repos).
Decision No. 4: Using Operators to create self-service functionality
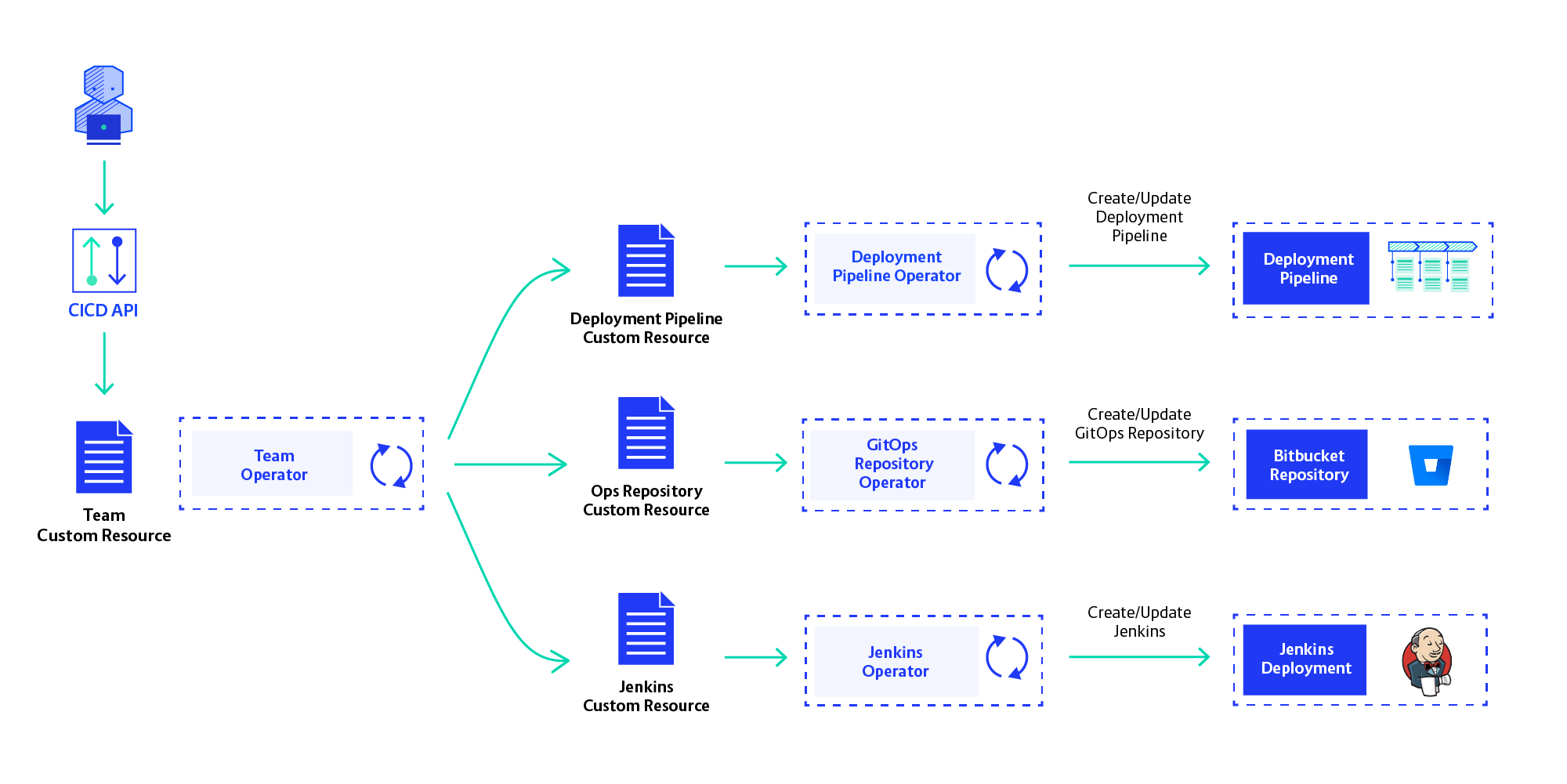
The next step was to create self-service capability for development teams. Even with the CLI tool, we were still the bottleneck as requests for new teams and new environments have increased. To free ourselves from this toil we had to fully automate all platform operations—creating, updating, and deleting team pipelines and environments.
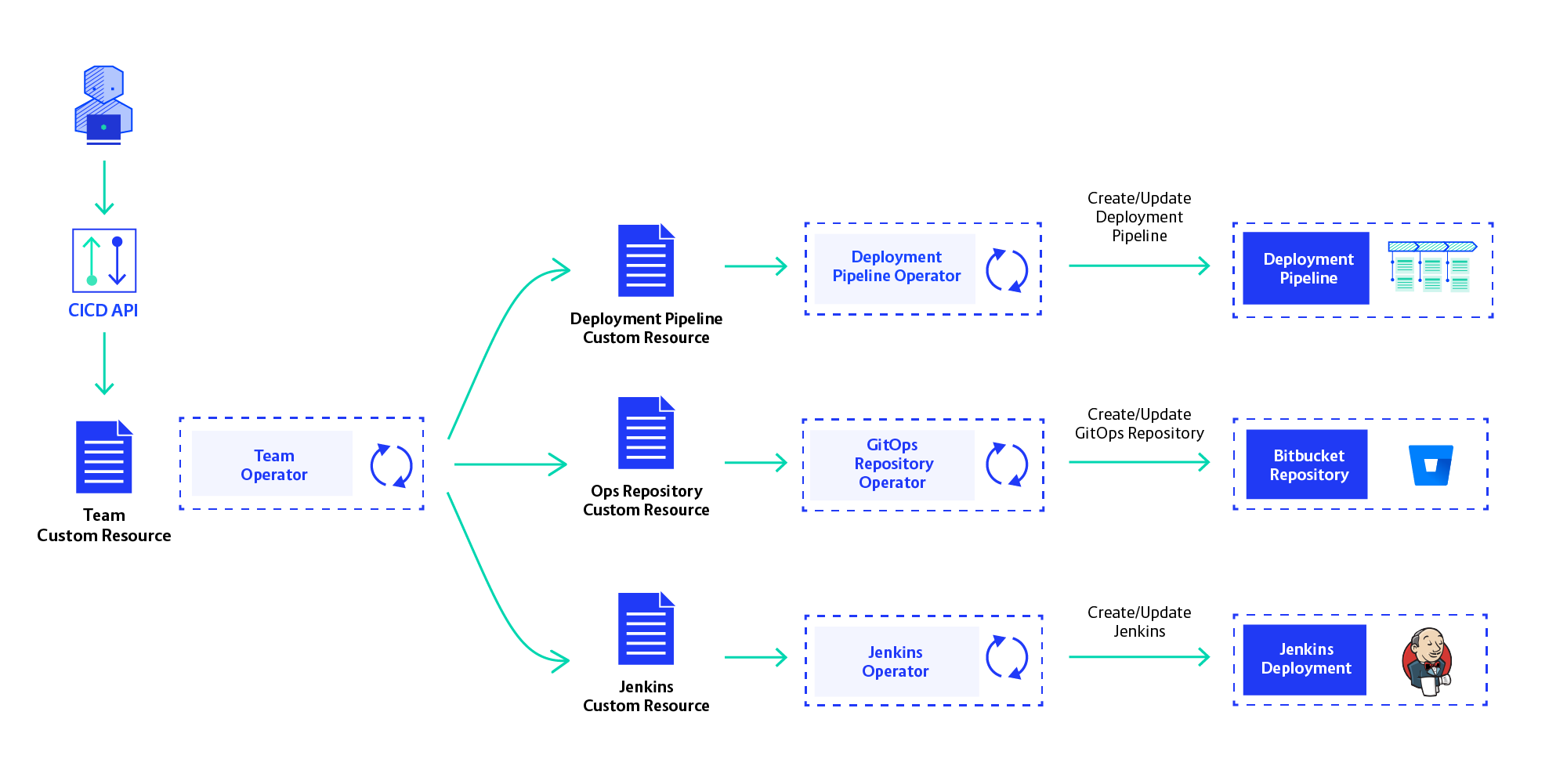
To enable self-service we had to move away from our CLI-driven provisioning strategy. We opted to provision teams’ CI/CD instances using Operators. Operators are a versatile architecture pattern that is becoming ever more popular. The idea is to use Kubernetes API Custom Resources to manage infrastructure components. An Operator will be driven by these Custom Resources created in the K8s API server and create the infrastructure components described by them. They should do this fully automatically, not expecting user interaction.
We are now in the process of implementing Operators for each resource in the CI/CD Platform: Jenkins, OpenShift Project, Bitbucket Repository and Deployment Pipeline. These sub-resources will be created and orchestrated by the Team Operator, which works with the definition of a development team and creates all CI/CD resources for them. Self-service is realised by creating Team Custom Resources in the Openshift API, using our own API service.
We still need to see if the Operator-based architecture works out, but so far results are looking good. The Kubernetes API is very good to store resources, as it provides events for changes of these resources and an easy way to update them. This way, we’ll tie ourselves to OpenShift— but since that is our cloud platform, that isn’t a problem.
Where the Project Stands Now
FiduciaGAD is still early in its journey towards Cloud Native, but so far our decisions have paid off. Teams don’t embrace Continuous Delivery yet, but a discussion has been started. This is largely aided by having a CI/CD Platform in place that supports true, microservice-based Continuous Delivery as the default way of working.
Security and compliance concerns have been addressed in a simple and efficient manner by employing the Gitops pattern to separate delivery workflows from deployment pipelines. Also, provisioning CI/CD for teams is going smoothly with our CLI tool and will get much better with the refactoring towards self-service.
Looking back, one of the best things we did was to be empathetic to developers who were not used to continuously delivering microservices. We gave them the tools to do so, but didn’t force it on them. Allowing teams to shape their process made our implementation work harder, but it led to developers feeling in control—which, in turn, leads to more acceptance of the learning process needed to make CD work for an organisation.
Check out our latest Microservices for Managers Whitepaper, click below to download.
