

In the past few weeks, I have been doing a lot of different tests and deployments on Kubernetes. Therefore, I had to create and destroy Kubernetes clusters many times (some days, even a few times an hour). I needed a fresh cluster due to specific things I was testing, so simply deleting all the pods, services, deployment, etc., to make the cluster ‘like new’ wouldn’t help.
I also needed to have the most ‘production-like’ cluster as possible, so all the local solutions (Minikube, Vagrant, and so on) wouldn’t work either.
![]()
At the beginning, I used managed Kubernetes from one of the cloud providers because it’s simple to deploy and, as soon the cluster is up, I could just download the kubectl config with a click of a button. But there were three problems with it:
- It takes sooooo much time, about 10 minutes to deploy per cluster. If I have to deploy and destroy it a few times per day, it adds up to a lot of wasted time.
- Downloading and loading the kubectl config, while simple, is still a manual process.
- It’s a managed service, so I don’t have full access to the cluster—and sometimes I needed it.
So I decided to create something that would allow me to deploy and destroy a Kubernetes cluster in the cloud faster and easier. (You can see what I did in this GitHub repository.)
I ended up with a simple Bash script that creates virtual machines on Google Cloud, deploys a four-node Kubernetes cluster (one master and three workers), downloads the kubectl config, and loads it into my system—and does all of it in under 60 seconds! From nothing (not even having VMs) to being able to do kubectl apply -f any_deployment.yaml in under one minute. Here’s how I did it:
Requirements
One of the important factors for me was to make the solution as portable as possible. I tried to make as few tools required as I could (so no Terraform, no Ansible, nothing that required installation and configuration). That’s why I wrote it in Bash and the only dependency I kept was to have GCloud CLI installed and configured (with default region and project set).
VMs
We start with VMs. Creating VMs in the cloud normally takes about 45 to 60 seconds. For example, on DigitalOcean, VMs are up (meaning ping starts responding) after about 40 seconds, but you need another 15 seconds for all the systems services to be up (and most importantly, the SSH server being able to accept connections).
So first we need to make that step faster— like, at least twice as fast!
We can achieve that by using a slimmer OS image. That’s why currently I stick to Google Cloud, because they provide Ubuntu Minimal image (which is less than 200MB in size). In the meantime, I tried many other minimalistic distributions but some of them were missing necessary kernel modules, even though they were slim—they take a long time to boot up.
Creating and booting up Ubuntu Minimal VMs on Google Cloud takes about 30 seconds (from the GCloud API, call till the SSH server is ready). So, we got our first step. Now we have another 30 seconds for…
Kubernetes
How do we deploy a Kubernetes cluster in about 30 seconds? There is one answer: k3s. For those who haven’t heard about k3s, similar to Minimal OS images, it’s simply a slim K8s solution.
K3s is intended to be a fully compliant Kubernetes distribution, with the following changes:
- Legacy, alpha, non-default features are removed. Hopefully, you shouldn't notice the stuff that has been removed.
- Most in-tree plugins (cloud providers and storage plugins) have been removed; they can be replaced with out-of-tree add-ons.
- Sqlite3 is added as the default storage mechanism. Etcd3 is still available, but not the default.
- It’s wrapped in simple launcher that handles a lot of the complexity of TLS and other options.
- It has minimal to no OS dependencies; just a sane kernel and cgroup mounts are needed.
By using k3s, we don’t actually have to do much to get Kubernetes up and running, because k3s installer does everything for you. So, my script only downloads and executes it.
Connect the Pieces
We found a way to boot up VMs in less than 30 seconds by using a slim OS image. We have k3s.io, which allows us to run Kubernetes in about 20 seconds. And now we just need to connect all the pieces together. To do that, we prepare a Bash script with:
- GCloud commands to deploy VMs
- Download and execute k3s installer on the master node (curl piped to sh).
- Get the token (cat command over ssh) generated by k3s, which is used for adding nodes to the cluster.
- Download and execute (with token as parameter) k3s installer on the worker nodes.
The only real challenge was to get the kubectl config generated properly—the public IP address on Google VMs is not visible/accessible on the machine itself (when you do ‘ip addr’ or ‘ifconfig’, you won’t find that IP there). So when k3s generates certificates and kubeconfig, it’s not valid for accessing the cluster from the outside.
But after a lot of searching, I found parameter ‘--tls-san=’, which allows providing additional IP addresses for certificate generation. We can get that IP address via Gcloud command and then pass it as a value of that parameter when executing k3s installer. Then, if k3s is deployed on all nodes, and workers are registered properly with the master, our cluster is ready.
The only thing left is to simply download the kubectl config (using scp to get the file from master node). Everything usually takes 55 to 58 seconds. As you can see, there is nothing extraordinary about the solution—just a few GCloud and curl commands glued together in one Bash script. But it does the job and does it quickly.
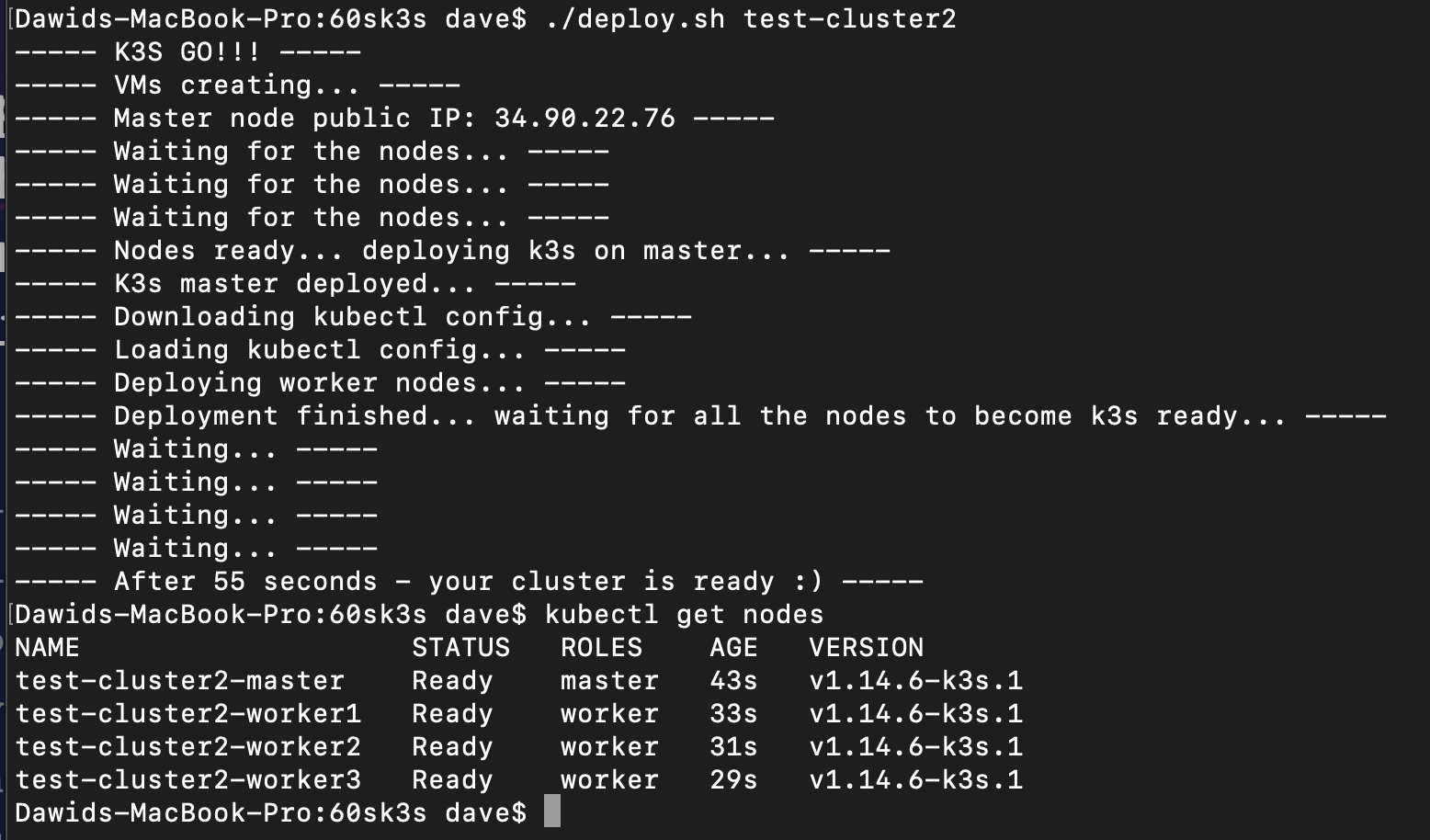
Next Steps?
First of all: Currently the whole solution is hardcoded to have a four-node cluster (one master and three workers). It’s rather simple to make it configurable—I just never needed a bigger cluster for the tests I did. But I will definitely add that option soon.
Secondly, the kubectl config is now either being only downloaded (so you can pass it yourself to kubectl command as a parameter) or it overwrites your existing kubectl config (which works just fine for my needs, since I don’t have any long-running clusters). But it would be beneficial to add an option to append the config to your existing config—and then change the context to it.
If there is anything else you can think of that would make this solution work better, feel free to let me know in the comments, or open a GitHub issue.
