
If you Google “DevSecOps”, and in particular if you read the typical security vendor blogs, you’d be forgiven for thinking that the term is all about automation and tooling. However, in much the same way that Cloud Native is really about culture far more than it is about containers, DevSecOps is really all about enabling effective communication.
For the purposes of this article, we’ll be considering the CAMS model (which stands for Culture, Automation, Measurement and Sharing) but disregarding Automation, primarily because there is plenty of advice around security automation already online, and also because it is not typically where we find constraints in most business settings.
Culture
To discuss it we’ll focus on Dr Schein’s work on culture, which is also the approach that Dr Nicole Forsgren et al took in their seminal book “Accelerate.” Accelerate, which also features on the WTF recommended reading list, demonstrates that the performance of our software development teams is linked to organisational performance.
In Dr Schein’s model organisational culture happens at 3 different levels: basic assumptions, values and artefacts.
Basic assumptions
Basic assumptions tend to be formed over time, as employees and other directly involved third parties make sense of their relationships and how work is done through their processes and activities. These are the things “employees just know”, tend not to be particularly visible, and as a consequence are hard to change. In security, basic assumptions are typically focused on understanding the environment and the context of how work is prioritised, how decisions tend to be made, and, correspondingly, what those decisions are based on.
A good first question to start to explore basic assumptions could be “whose job is it to do security?” Our industry has come to parrot the adage “security is everyone’s job” although in practice that is seldom helpful. If we make the effort to really understand other people’s jobs, how they perform them and the constraints they are under, we may find some places where security genuinely is a collective problem, others where it isn’t even considered. We may also find particularly interested individuals who can and would love to champion security within their own teams. We can start to change the underlying basic assumptions by teaching our potential security champions the fundamentals, thereby giving others in their teams a more secure way to do the things they are already doing.
To expand on this further, we should note that within these basic assumptions there are two key elements—agency and trust—which will give you an indication of the collaboration dynamics between security governance and your development or platform teams. Agency—having control over the work that you do—has to precede ownership, as no one will want to be responsible for something they can’t co-create. For us, as security professionals, this means that, rather than telling the software developers what to do, we need to give them the necessary tools and then allow them control over how security may or may not be embedded into their normal work, and to actively determine mitigations for identified vulnerabilities. However, this also requires that those tasked with governance are able to develop a high level of trust that the processes and practices that are in place provide sufficient evidence that the organisation performs due diligence in guaranteeing an appropriate level of security for their products and services.
Exploring agency and trust within your organisations, in particular in the relationships between security governance and engineering, will give you insights into what the underlying basic assumptions are.
Values
Values tend to be more visible to group members since collective values and norms can be discussed when you’re aware of them. These values influence group interactions and activities by establishing social norms, which shape the actions of group members and provide contextual rules (ie: here we can do things like this, but not things like that).
For some practical tips on how to identify and work with values:
- Focus on learning company and team level values, for example by asking what it is they feel proud of. More often than not, security teams are ignorant of these, which can lead to attempts to “throw the baby out with the bathwater”, causing security initiatives to be met with resistance. Security champions or communities of practice are great ways to hear and explore the narratives of how security feels in the organisation
- Next. frame security activities within the attainment or pursuit of those values. If there are metrics or measurements for some of them, try to influence stakeholders to set up contributing measurements that relate to security, for instance, if our organisations have a goal and values aligned to being competitive or enabling time-to-market, we can frame the need for our security automation programme. A brilliant analogy was put forward by Google Cloud CISO, Phil Venables, who called it “slipstreaming” business initiatives to drive security improvements.
- When introducing practices and tools, frame those initiatives in the attainment of company values. Language is important.
- If you manage a team, ensure that the mapping between what you do and company values are regularly reinforced in your communications by yourself and your team members
When starting to address values, it’s useful to differentiate between the actual company values and the nice-sounding values on a typical corporate culture deck. As Patty McCord (ex-Netflix Chief Talent Officer) put it:
“The actual company values, as opposed to the nice-sounding values, are shown by who gets rewarded, promoted or let go.”
Often an organisation’s true values are revealed when the company is under threat. This has implications for how we deal with security violations, security incidents and security reporting. If, as a leader, you’ve made a habit of sanctioning and bringing out the disciplinary handbook too soon, you can expect a chilling effect on your culture as no one will willingly be forthcoming about any security vulnerabilities they may find, for fear of the consequences of doing so. That implies that we need to be deliberate and relentless in making it safe to report and discuss security issues through the promotion of organisational psychological safety. You need to make it so that reporting issues, even when someone feels they made a mistake, is always the best option and never a career-limiting activity. However, I appreciate that the line of “gross negligence” will always exist, so you need to be very deliberate and conscious as to where it is and the effects it can have on the whole organisation’s dynamics.
Artefacts
This particular quote is telling in how we should be approaching the issue of culture change, which often tries to start from assumptions and values which is less effective, according to Shook.
“What my experience taught me was that the way to change culture is not to first change how people think, but instead to start by changing how people behave—what they do”
This suggests our first focus should be on practices and artefacts knowing that they’ll have a knock-on effect to values and assumptions over time. Cultural change takes time, so plan accordingly and embark on it with realistic expectations.
Artefacts are anything that people “touch”. This might be a codebase, a policy document, a questionnaire on a spreadsheet, a software agent one needs to install and so on.
Artefacts often serve as “boundary spanners”—the input and/or output interfaces between teams. For example, some Development teams may be required to fill in a system security plan on a spreadsheet highlighting all the controls which will be in place for a new system being built. This is then reviewed by a security professional as sign-off of the design and authorisation to build it is granted.
There are some key challenges we see in how artefacts are used which affect how effective you can expect security to be. Some of the key challenges are:
- Artefacts are created but not maintained as capabilities
- Creating artefacts that exist outside the normal work context of engineers
- Artefacts don’t enable traceability for management system concerns
Artefacts are created but not maintained as capabilities
Sriram Narayan’s article on Martin Fowler’s blog describes the idea of “ Products over Projects” thus:
“Software projects are a popular way of funding and organizing software development. They organize work into temporary, build-only teams and are funded with specific benefits projected in a business case. Product-mode instead uses durable, ideate-build-run teams working on a persistent business issue. Product-mode allows teams to reorient quickly, reduces their end-to-end cycle time, and allows validation of actual benefits by using short-cycle iterations while maintaining the architectural integrity of their software to preserve their long-term effectiveness.”
The Infosec world, largely speaking, is still stuck on the paradigm of managing and delivering projects rather than on managing products. One of the key distinctions is that the work isn’t over when we give a team an agent for them to install, or a new policy document to adhere to. Organisations are living things, constantly adapting and evolving within the constraints of their goals and context, and if we just “build and forget” or “build and hold accountable for not meeting”, then we’re selling ourselves short and being detrimental to our organisation’s ability to keep evolving. In this worse case, we end up creating the conditions where covert work systems emerge as engineers discover that meeting security expectations requires unacceptable trade-offs and imposes unrealistic constraints on achieving their goals.
Creating artefacts that exist outside the normal work context of engineers
When creating these artefacts both for our teams and other engineering or business teams to use, we have a tendency to make them in such a way as that they sit outside of the normal work context. For instance, we provide tools that don’t provide feedback in a CI/CD pipeline, forcing engineers to log on to different portals to see the output of security reports, as opposed to choosing technology that normalises all issues of quality (like their unit, integration or end to end testing) directly into the CI/CD system itself. Or we create policy documents that exist only as Word documents, or in collaboration tools the engineers never use, and then we wonder why others aren’t paying attention. To affect how normal work is done we need to consider the context and ensure we’re building capabilities that seamlessly integrate with it. Anything different from this adds friction and is thus not an enabling element of our security programmes for other teams.
Artefacts don’t enable traceability to management system concerns
What I mean by this is that we may know we’re running validations against the use of insecure software dependencies, or making some validations regarding permissions on roles being used, but there’s nothing that can be leveraged to connect it back to either the organisational risks we’re trying to manage or the compliance obligations we may have.
Leveraging the use of metadata to keep that traceability to things we care about is key when scaling the use of provided capabilities and to include it in the creation of artefacts, as it becomes another mechanism for enabling meaningful communication between teams. For instance, if we have a test that outputs the results of running a validation against known vulnerabilities of software dependencies, and that test is tagged with the compliance requirement it helps us achieve, now we have an artefact that has the necessary information in context for engineering. In addition, it also provides the required evidence that the compliance manager can use directly from the running of the process to confirm which compliance requirements are being met every time someone deploys code or a new system. This eliminates the need for manual audits and manual tracing and makes all parties more effective.
Measurement
Measurements are yet another challenging aspect of creating and sustaining our security programmes. Before discussing metrics, we should think about who the audience is going to be for them and how what we intend to measure aligns with the concerns of those who will be affected by them.
Jabe Bloom discussed (referencing prior work by Elliot Jacques, a psychoanalyst and social scientist who originated the concept of “timespan of discretion” ) which links the complexity of decisions taken by a stakeholder in an organisation and their scope of responsibility. The same concept also ties into the idea of observability of actions, meaning “how long will your manager allow you to produce outputs before checking on the outcomes?” For Executives, this tends to be in multi-year cycles, whereas for a knowledge worker (such as an engineer) it is likely constrained to two-week sprints or similar.
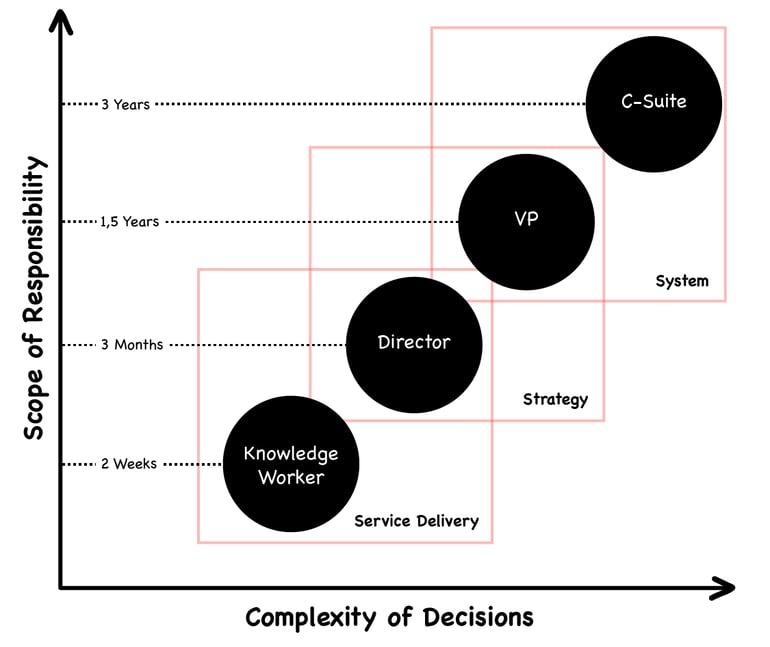 Original from: https://www.youtube.com/watch?v=WtfncGAeXWU by Joshua Bloom (full reference in chapter references)
Original from: https://www.youtube.com/watch?v=WtfncGAeXWU by Joshua Bloom (full reference in chapter references)
Measurements should allow us a venue to connect these different timelines based on content that is meaningful at each timescale.
One such approach is to connect the measurements through management of risk at the executive level, focus on security capabilities and key risk indicators at the VP/director level, and connect it to practices of threat modelling at the knowledge worker level.
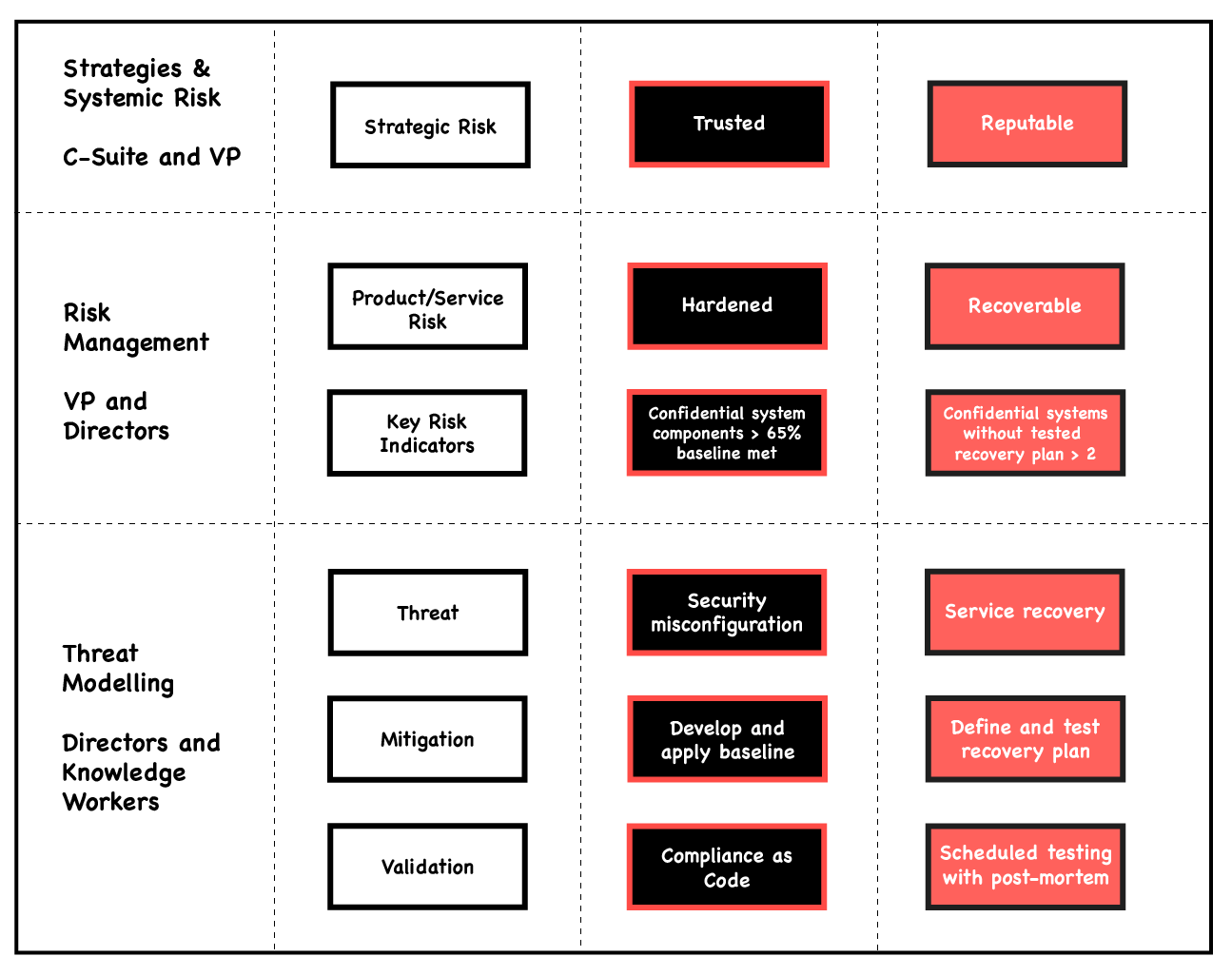
Risk can be presented using bow-tie diagrams and similar techniques to provide a visualisation of both the threats and controls, as well as the consequences and mitigations against them, using either quantitative or qualitative approaches depending on your level of risk management maturity.
The VP/director level is where expressions of risk tolerance should be translated into metrics and objectives negotiated, keeping in mind all the other constraints and goals of the organisation through attributes that make sense in your context.
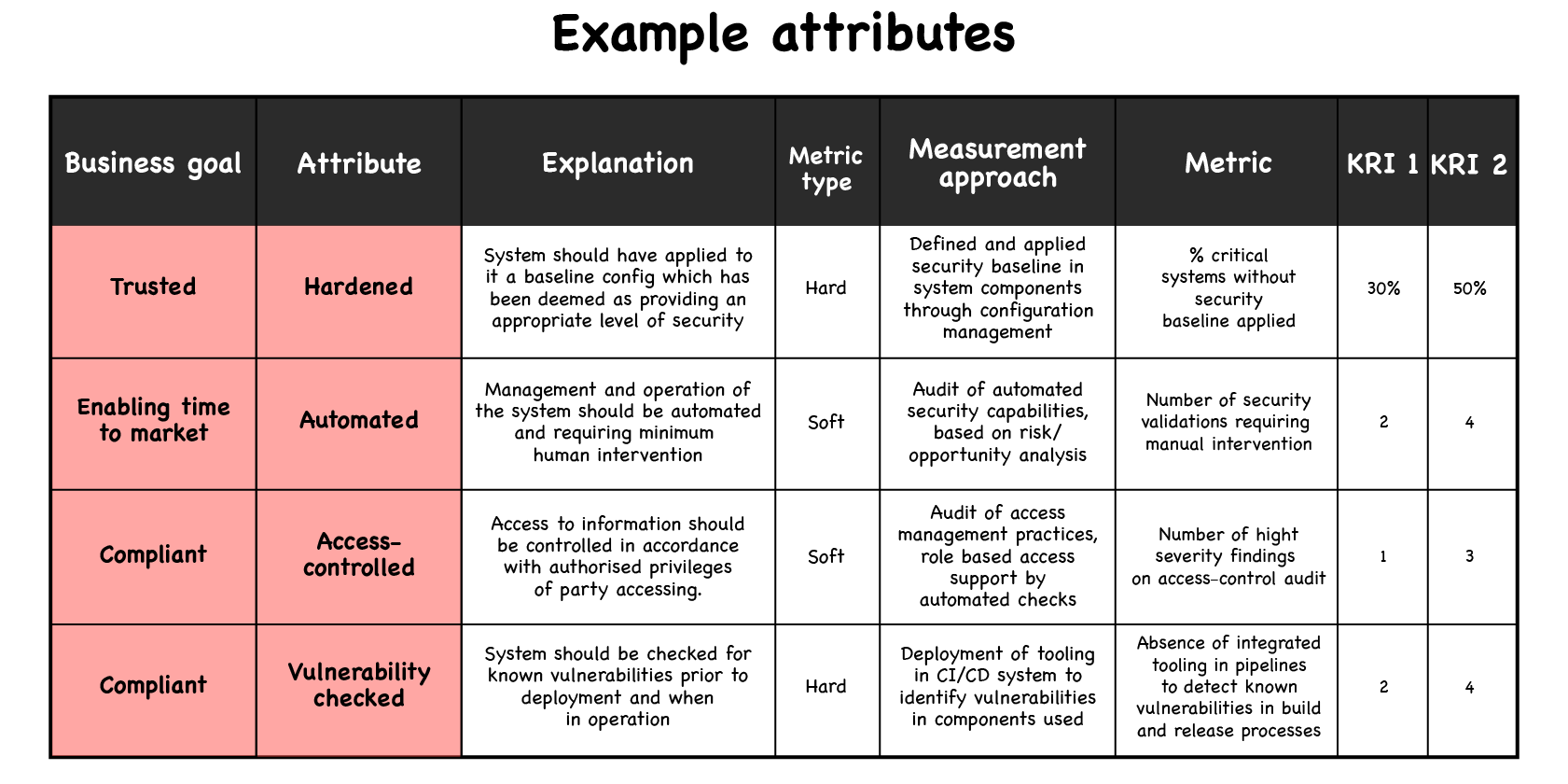
These can then help inform targeted threat modelling sessions to help explore these positive security attributes and ensure mitigations are put in place to protect against corresponding threats.
At the Engineering level, the same metrics are relevant however understanding how security practices can affect key DevOps metrics would be where I suggest you start.
The research from DORA (and their State of DevOps reports) has associated 4 key metrics for software delivery performance with organisational performance that we need to be familiar with. These metrics are:
- Lead time—the time it takes to go from a customer making a request to it being satisfied
- Release frequency—Software deployment to production (which is a proxy for a batch size of code deployment)
- Time to restore service—the time it takes to restore service when incidents happen
- Change fail rate—what percentage of changes to production systems fail
How we approach security can have different effects on these metrics—either detrimental or supportive.
| DORA metric | Detrimental Infosec | Supportive Infosec |
| Lead time | Manual reviews and prior-to-dev risk analysis may affect this negatively (tempo of risk specialists unaligned with Development sprint planning) | Minimise manual reviews, heuristics and lightweight processes for analysis risk such as service level (as opposed to feature level) risk assessments and targeted risk-informed threat modelling |
| Release Frequency | Manual vulnerability checks or penetration tests may affect this negatively, whilst the absence of them be too risky | Develop platform-level verifications with immediate feedback to Developers, easy to consume and interpret output with local management of false positives |
| Time to restore service | Convoluted, untested disaster recovery processes and unplanned forensics will negatively affect this indicator | Regularly tested incident management and disaster recovery processes, and regular review of “near misses” or wargaming/Game days can help improving this metric by periodically testing responses |
| Change fail rate | Failing builds on security findings, without letting Developers manage false positives or have clear and quick exception management processes aligned with Development tempo | Establish pragmatic security boundaries that fail builds only on security findings posing actual risk to the organisation, such as critical vulnerabilities with known exploit code or actively being exploited by attackers |
The main take-aways regarding metrics are the following:
- Make them relevant (so within their agency) to the stakeholder looking at them: They must be able to support informed decision making within the scope of an individual’s responsibility and not just relate to someone else’s concern. Ideally, they should help highlight goal conflicts and trade-offs.
- Contextualise your metrics: a “one size fits all” approach across the whole organisation is likely to alienate those further behind and not be a driver for action for those further ahead. Team context is key, and as such, the relationship with Product owners is a key element as well. Targets for metrics must be negotiated to be effective.
- Do not establish target metrics without understanding what “current” looks like or the trade-off’s involved: That’s a recipe to commit to targets that have no bearing in reality or are unachievable considering performance and capability objectives which are someone else’s actual day job.
Sharing
Sharing is key to enabling knowledge and capabilities to disseminate within an organisation. This must have an expression in at least 3 dimensions: sharing of concerns, sharing of capability and sharing of information.
To ensure sharing of concerns, you must make it a goal to establish the conditions where it’s psychologically safe to report weaknesses, vulnerabilities or risks. Doing this is hard, requiring continuous and deliberate action, and jeopardising it is very easy—one poorly judged management or executive response can establish the conditions for people not to be forthcoming. For a recent example, consider how Volkswagen recently fired a senior employee after they raised cyber security concerns. Whilst there may be nuances here that aren’t conveyed by the FT article, just the fact that an article or communication exists is enough to make employees more likely to try to hide or pretend they didn’t see security concerns for fear of reprimand or career limitation. What we want, of course, is for employees to be forthcoming about what they found; if they don’t feel able to be so we’re left both ignorant and more exposed to risk. Reporting mechanisms and how leaders deal with bad news are key elements to optimise to support this.
To ensure sharing of capability, your goal should be to create the artefacts which ideally can support multiple teams at the same time, so that a few individuals can become experts at them and then be in the position to support others to improve their own integration of security capabilities. This is a key element to appropriately scale your security programme and has obvious implications for organisational design. The idea of “enabling teams”, described by Manuel Pais and Matthew Skelton in Team Topologies, is a way of providing the capability, often supported by the creation of security communities of practice or security champions programmes. These can then in turn act as a “sensor network” as to how security feels in your organisation and also provides a touchpoint where security teams can greatly leverage their impact across multiple different teams.
Finally, to ensure sharing of information, the main insight is that information needs to be available as close to the context of the recipient as possible. In a software development context, don’t expect your developers to know your security policies if they’re on a Word document on a collaboration tool that they have no other use for and never access as part of their daily jobs. If your developers spend their life in GitHub or Confluence to look for guidance and their own documentation, that’s where your policies should be so that they reside within the context of their work. This removes a context switch which is associated with increased cognitive load and decreased performance. Enabling asynchronous consumption of information is always a good idea, so recording short videos on how to solve a particular problem or integrate a tool becomes useful both to refresh knowledge and help with onboarding new team members.
Closing thoughts
DevOps and DevSecOps are about much more than just tools and automation, and our security programmes should reflect this. Focusing on culture changes, determining relevant measurements that help provide a sense of direction for the programme without becoming targets in and of themselves is key as is taking deliberate action towards making sharing an integral component and focus of your security programme. Focusing on those will have a much bigger impact on your security outcomes than spending your time and effort trying to select between a Leader or a Visionary DevSecOps tool vendor on Gartner’s magic quadrant will ever do.
Our focus should be on getting the right culture, the right mechanisms for sharing, decent available measurements that can help direct and course-correct action and any reasonable technology. DevOps and DevSecOps are about continuous improvement and decreased feedback loops. Taking a lesson from Disney’s Frozen movies we should focus on “doing the next right thing”.
