

If you’ve got something valuable, you can pretty much guarantee that someone will be looking to carry out unauthorised activities around it, and cloud workloads are exposed to just as many security risks as traditional architectures. But the risks are different, and so are defences.
Security in a cloud environment is very different from the things we’re used to. The cloud gives you less to worry about, but also less control—most things are higher-order abstractions, which are easier to manage, but this means you’ve got more work to do at those higher levels of abstraction. This in turn impacts both your applications and the supporting infrastructure configuration, at least to the extent you can control it.
In the same way that building modern 12-factor cloud apps is different from traditional software engineering, cloud security requires very different thinking. Having less control over the “perimeter” and more zero trust relationships with the external world leads you to different priorities in your security work. Data-related security risks are often overlooked.
Having complex data flows less limited by your capacity to build infrastructure, and more justified by business needs, creates unique requirements in terms of orchestrating data security controls - making data available where it’s needed, securely.
Hence thinking about data security in Cloud Native environments requires a different perspective, and we’ll try to provide one in this article. Having created many data security tools and libraries and helped dozens of customers protect sensitive data in high-risk environments, we have gathered some observations on how tech companies build their data security tooling in the cloud.
Cloud native data security is different
Every solid security decision comes from a combination of mental models: risk assessment, risk mitigation choices, threat models, threat vectors, loss event scenarios, etc.
From a risk perspective, the cloud environment is not so very different from your traditional racks of servers in a data centre. But the responsibilities are split differently: in theory it is the responsibility of your cloud provider to ensure that everything runs securely. But when it fails you might find that it’s the fault of your “S3 bucket misconfiguration”, i.e. your vulnerable application that has failed. Thus, while you have to take care of less, you actually extend your risk posture—the overall cybersecurity strength of your organisation—to more things you have insufficient control over.
Engineers often think, “it’s a cloud; the best security professionals are taking care of it”. In a sense, this is quite correct since the cloud provider’s team have really polished their set of controls for millions of customers and those controls have stood the test of time, but it barely gives you a full picture.
Cloud security should accommodate risks relevant to the cloud. Remember that the data owner, but not the infrastructure operator, is held responsible for a breach under a number of regulations (GDPR, PCI, CCPA, country-wide regulations).
There is a need for field level encryption that prevents developers and DBAs from accessing sensitive data; security controls to stop SQL injections and insiders; audit logging to restore the incident picture in case something goes wrong.
Cloud security should also accommodate different architectural assumptions in the cloud: state management, disposable replicas, load-balancing, etc.
In other words This “grey zone” of control requires you to work on security more rather than rather than less.
Data security in the cloud
Even more in the cloud world data is the ultimate at risk asset. So when you can re-provision your whole product with two terraform scripts and a bunch of IaC tools on top, the only thing that matters is trusted execution and data security (integrity, availability, confidentiality).
With many other security concerns eliminated (or subordinated to access control and infrastructure management), investing in application security and data security brings the biggest improvements in security posture inside the cloud.
All means to these two ends matter. There is a lot said about application security—it’s infinite. Unfortunately, data security is often underlooked until it’s too late.
Managing complexity
The biggest data security challenge is not in encryption or key management, although these are challenging. The biggest challenge is managing complexity: setting out dataflows and mapping controls onto them.
Phil Venables has a great take on this in his “Is Complexity the Enemy of Security?” post.
Managing complexity gets exacerbated in the cloud:
- More building blocks can be easily connected and exchange the data in novel ways.
- Having more data and building blocks means more sophisticated access policies and configurations to harmonise different data security controls.
You might be lucky if you can define choke points to data access and gather most data security around them. For example, by setting up an encryption proxy before each database, or deploying a data access service responsible for grabbing sensitive data from protected storage. See examples below in the Reference architecture.
When it’s not possible, making the data accessible in necessary parts of its lifecycle via Encryption as a Service and other related security controls is a must.
When you finish, you’ll end up with five to ten different security controls that should, ideally, be coordinated between themselves to avoid policy gaps and provide perfect defence-in-depth.
Lock-in is actually a security risk
When you think about cloud databases, whilst shifting large volumes of data from one cloud provider to another is time consuming and hard, you do at least often get interoperable data models and even wire protocols. But when looking at security tooling, migrating configurations and keys often becomes a challenge. Migrating security tools along with data is even more challenging, as cloud-specific controls need also to be re-deployed and re-configured in the other environment.
The risks outlined in the Security concerns during data migrations paper are equally valid for database migration.
Aside from being bad from a budget and continuity perspective, lock-in is a problem: migration means massive risk exposure of spillover and risk of misconfigurations along the way.
Cloud architecture vs data security
Not everything about data security in cloud environments is bad. Cloud environments already provide many helpful security services. Among them are the always available and reliable AWS IAM and KMS, enabling more fine-grained access control and encryption management. It’s easier than ever to triage each database query against access control roles of each individual user, if necessary.
Cloud environments also help with availability: snapshots, database backups, encryption keys, etc.
However, there are certain downsides.
- Everything costs money, and CloudHSM / KMS Vault costs are not inconsiderable. This often leads to novel incentives to bend security architecture in (entirely understandable) favour of reasonable OPEX.
- Implicit choices are hidden under the lower cost of provisioning/managing, leading to inelegant knots in the architecture.
- Field level encryption increases data volume. If you pay for the volume, you’ll pay more to store encrypted data.
Building data security layer in a cloud
In terms of engineering practicalities, there are three central things you to consider when designing a data security platform for the cloud:1.Focus on mitigating more security risks with fewer tools (fewer tools → fewer bugs). Remember, each tool, even a security tool, brings bugs and increases the attack surface. Also, orchestrating security policy over systems built from hundreds of components is harder when security tools are abundant.
2. There are many types of security controls: preventive, detective, corrective. They should be orchestrated and work together. For example, access control is useless without triggering security events, but gathering events without monitoring them is also meaningless.
3. Consider if you need centralised security or decentralised. If your product is 10-20 interconnected applications in one cloud account, you need a data security platform (rather than standalone features in one app) to manage encryption and data security controls. It’s easier to armour a single encryption layer with specific controls: DLP, anomaly detection, firewalling, anonymisation, etc. See NIST SP 800-204.
Application level encryption vs TLS
Application level encryption (ALE) is an encryption process that happens within the application and doesn’t depend on the underlying transport and/or at-rest encryption.
Application level encryption works together with data at rest encryption (database-level) and data in transit encryption (TLS). ALE means that sensitive data is encrypted by the application before it’s stored in a database, and decrypted by the application after reading it from a database.
Typically, only sensitive data fields are being encrypted, thus the “field level encryption” term is used. For example, the user table contains encrypted Personally identifiable information (PII) while avatar, login date and nickname are stored in plaintext.
ALE can be implemented in various ways to address different security requirements—from end-to-end encryption and zero trust architectures to partial field-level database encryption. ALE protects from more risks than transport and at-rest encryption, but at the cost of tradeoffs.
Using TLS between various components of your infrastructure is a necessary measure. But it only protects the data against leakage and tampering of the network traffic between nodes and adds authentication for node-to-node links, when set up correctly.
Database level encryption schemes are often self-defeating as data and keys end up in the same database (thus, privileged users with access to the database can access sensitive data in plaintext).
Reference architectures
The data security layer usually combines several security controls around data: authentication, firewalling, and application level encryption. The encryption engine could take many shapes: from a standalone service with access to encryption keys that hides cryptography details from the apps, to a built-in encryption SDK directly in the application code.
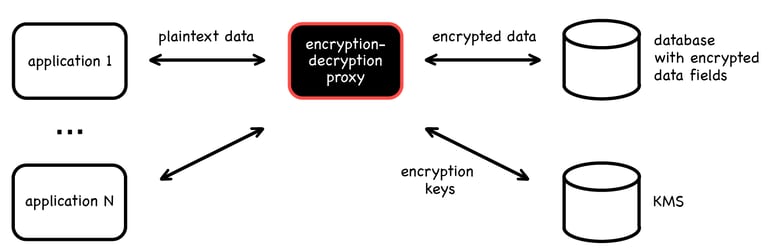
Database proxy
A database proxy works as a transparent encryption/decryption proxy for databases. The application connects to a database via proxy. The proxy in the middle intercepts the data, encrypts it and sends it to the database. When the application reads the data back, the proxy decrypts and sends it to the app.
The beauty of this scheme is that it's "transparent" encryption. The application doesn't know that the data is encrypted before it gets to the database. The database also doesn't know that someone has encrypted the data. All developers need to do is to configure the database proxy which data fields to encrypt. This approach is called "field level encryption".
Encryption is not the only feature of a database proxy. It will typically also provide tokenization, masking, anonymization, SQL firewalling, and so on.
Tools:
- Acra database security suite in SQL proxy mode – encryption, searchable encryption, tokenization, masking, firewall, access control, audit logging.
- ProxySQL – firewall for MySQL and MariaDB.
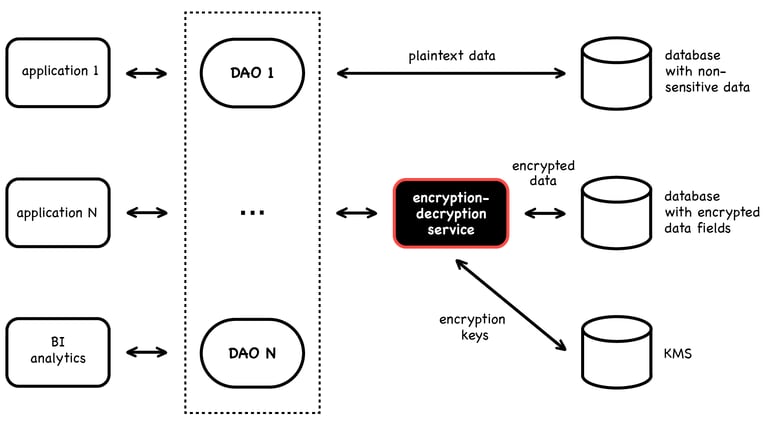
Data Access Object
A Data Access Object (DAO) is a service that proxies data exchange between backend modules and the database. This is conceptually similar to a proxy, but the DAO service can work with multiple databases (both SQL and NoSQL). The DAO knows the data layout— which data is sensitive and stored encrypted (so the DAO asks the encryption engine to decrypt it), which data is stored in plaintext (so the DAO asks the databases directly).
A DAO often provides an API for applications to read/write data to the database, while encapsulating the encryption/decryption of sensitive fields. The DAO is responsible for authenticating applications, and finding/using the appropriate encryption keys.
Many existing Encryption as a Service tools can be configured as a DAO. Also, the DAO should provide high availability and scale with the solution.
Tools:
- Acra database security suite in API service mode – encryption, tokenization, access control.
- Hashicorp’s Vault.
- Cloud KMS + Encryption API (Azure, GCP and AWS’s KMS all have encrypt/decrypt API and libraries with generated / BYOK wrapped keys).
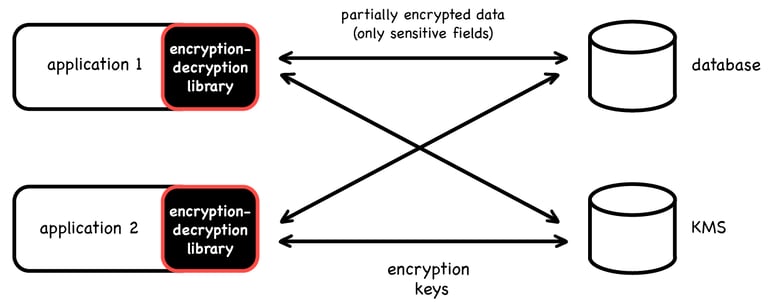
Encryption library (SDK)
An encryption library is a cryptographic code integrated into an application that handles sensitive data. The library encapsulates cryptography, providing “encrypt” and “decrypt” methods. The application is responsible for encrypting fields before sending them to the database and decrypting them upon retrieval. The approach is called “client-side encryption”.
The advantage of such an approach is that there’s no need to deploy and maintain separate encryption services as the applications are responsible for protecting data that goes through them.
However, there are multiple downsides: apps have access to the cryptographic keys, thus significantly increasing the risks of data leakage through application vulnerabilities. In addition, applications now encapsulate sensitive cryptographic code, and therefore need to be maintained, have dependencies updated and so on. It is also much more complicated to take care of the security of multiple applications than a single data security layer.
Tools:
- Any popular cryptographic library can be used: libsodium, Themis, Tink, etc.
- MongoDB provides a ready-made SDK for client-side encryption.
Technological processes to remember
Data security comes hand-in-hand with technological and organisational processes.
Key management
Encryption brings key management: generation, distribution, secure storage, rotation, expiration, revocation, key backup. Refer to NIST SP 800-57.
Key backup is essential, as losing encryption keys could lead to losing all data encrypted with those keys. Therefore, we recommend multi-layer encryption schemes: separate data encryption keys to encrypt data fields, key encryption keys to encrypt DEK, customer-related keys to encrypt KEK. Such schemes provide more flexibility in key rotation and allow us to back up only high-level keys.
When a company processes the sensitive data of its enterprise customers they expect that their data is encrypted with customer-related keys. BYOK/HYOK schemes come to the rescue here. In such schemes, it’s essential to define who is responsible for key storage and backup—the customers themselves or the solution provider.
Monitoring and audit logging
The data security layer requires robust telemetry and anomaly detection. Correlate events from the data security layer with typical metrics from other parts of the system.
- Encryption and decryption errors. An increased number of decryption errors related to the same application might indicate a configuration error of this application or malicious activity.
- “Access to cryptographic keys” errors might be a sign of KMS compromise or misconfiguration.
- CPU load on encryption/decryption performing services—is someone grabbing too much data?
- Correlating database connection errors together with database load could suggest suspicious activity in the database cluster.
The essential goal of the security layer is to ensure trust, protect data and provide a basis for data security compliance. Thus, it should contain logging, and more specifically, audit logging that:
- covers all key access processes;
- covers all key management procedures;
- covers all security-relevant access events.
Audit logs are helpful if they contain a timestamp, an ID of an event or error, service names, session ID, and the message itself.
But audit logs are even better if they provide protection against tampering. Often such log messages are cryptographically linked with each other and cannot be noticeably changed. Simple implementations of tamper-free audit logs look like a chain of logs (see this blogpost and this paper); more complex one are based on Merkle trees (see RFC6962).
Application security as a process
Security is a never-ending process. Just deploying encryption, monitoring or firewalling is not enough.
The data security platform should be subject to a general application security practice: secure software development (see NIST SSDF), dependency and vulnerability monitoring, validation against popular standards like OWASP ASVS v4.0.2, secure CICD, security testing and many more.
Summing up
Cloud Native security requires different security thinking. The data is everywhere: applications, databases, backups, 3rd party APIs, analytic services, etc. Data security moved from "protect data where it's stored" to "protect the data whenever it exists".
Data security measures become a security boundary for data. Cloud Native infrastructures require the orchestration of many tools to build a data security layer across all the places where data lives.
The main functional and nonfunctional requirements of the data security layer in a cloud are that:
- The data security layer should provide enough security that misconfiguration, API exposure and privileged administrator should not be able to configure the platform to expose the data outside.
- Security should not prevent scaling architecture.
- Data security measures should not prevent the system from consistently recovering from split-brain-like incidents.
- Data encrypted by a data security layer should not become inaccessible via a single failure.
- Key management and encryption should be independent from access management (e.g. access management provides fine granularity, key granularity for encryption should not depend on it).
Luckily, there are production-ready tools to select from independent of a cloud provider you are using. Check the reference infrastructures, try the tools, read data security blogs, and stay secure!
