
Moldable Development is a way of programming in which we construct custom tools for every software development problem. This introduces a new feedback loop that helps you steer your software system more rapidly and with greater confidence.
“WTF?”, you ask? Let me give you a couple of examples.
Applying Moldable Development to a Database Migration Project
Let’s say you learnt that it’s critical for business development to get finer grained data about the running of your business. In the process, you also realise that the old database is running on an unsupported platform and needs to be moved to a more up-to-date service. That’s great. Sounds like a database migration project—only it’s not. You soon realise that moving the data is the easy part, but you still need to adjust the applications that rely on that data. Did I mention that this is an old database? It’s a core database, too; one of those that are used directly by several systems. It grew organically and nobody really knows what should go where.
A problem like that can feel monumental. What should be done first? How should it be coordinated? Who should be involved at all? These questions require a better view of the system.
You talk with people, you read the docs, you peak into the database schema. It’s tricky because all these systems are heterogeneous and are built by various teams you don’t always have proper access to. Furthermore, they sometimes access the database through intermediary services. Eventually, you get to this:
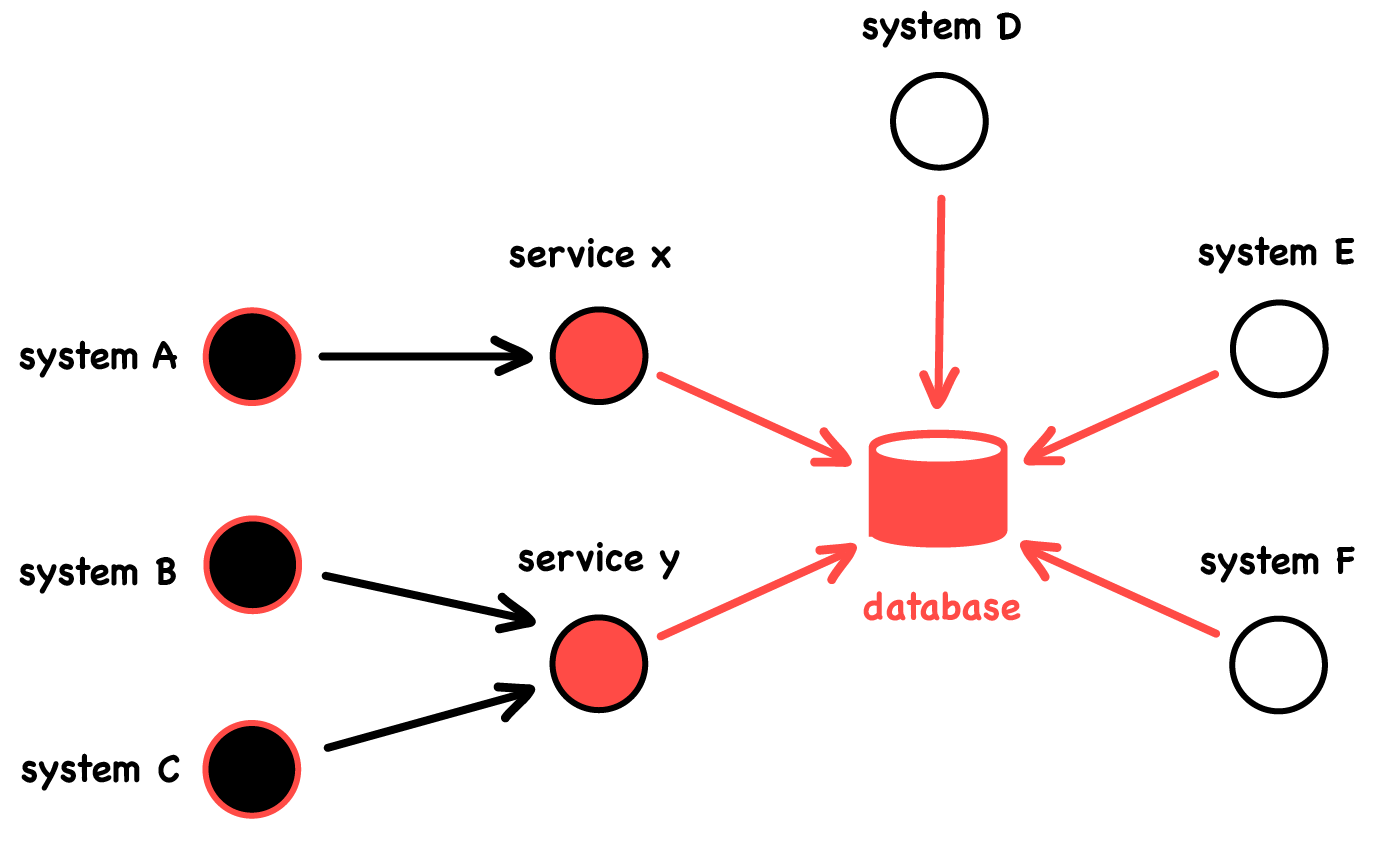
This gives you a better feeling. You get an overview. But, wait. What overview is that? It isn’t an overview of the system, but rather an overview of your understanding of what the system is—your own mental model. And there is a large difference between the two. Any picture you manually draw about an existing system documents your belief. These pictures are important because they reveal your hypotheses about the system, but they should not be the basis for decision making.
What you need is something like this:
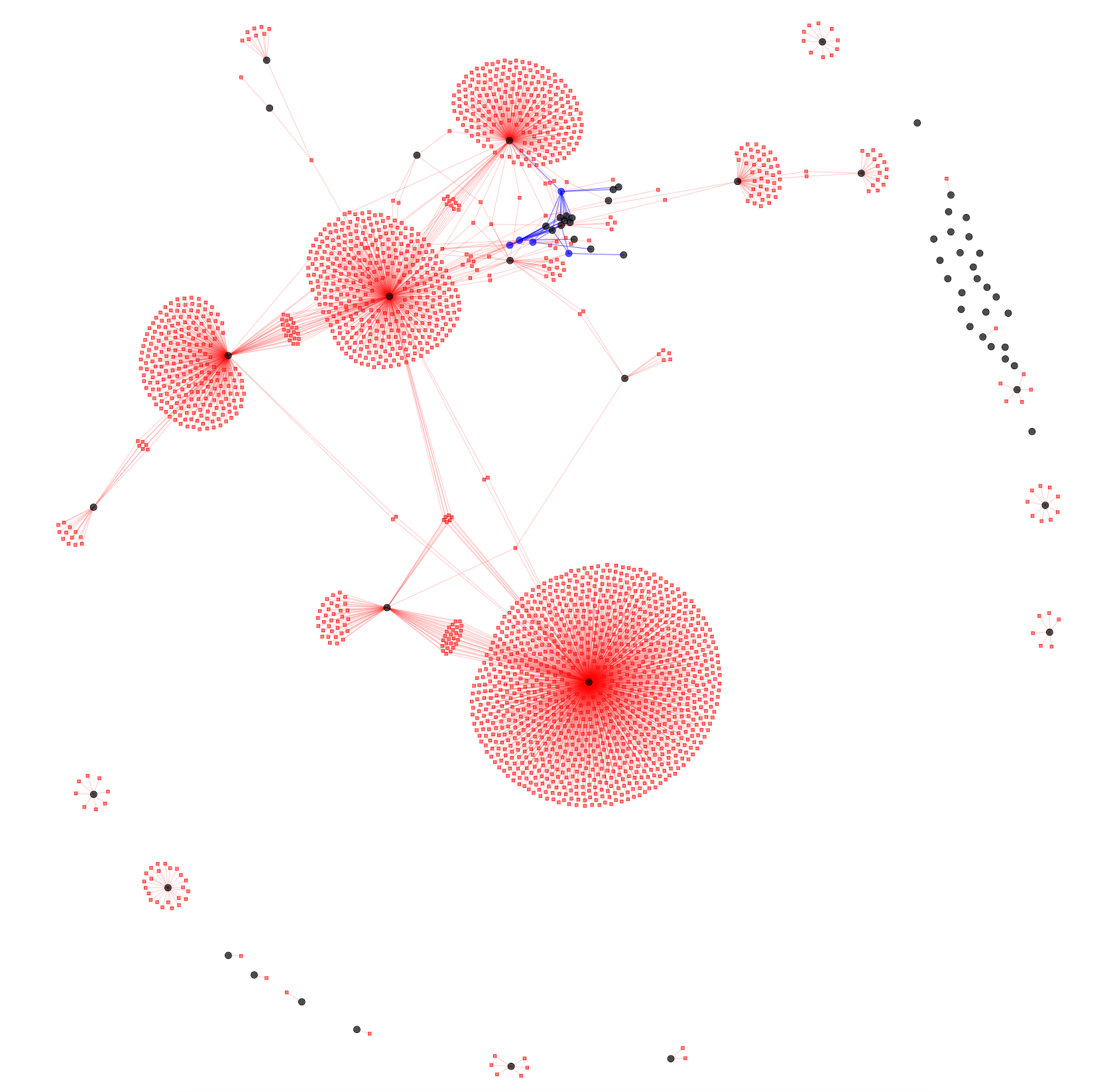
It’s a seemingly similar view, only this visualization is created out of the system. Specifically, the dark circles represent systems from the organisation; the red squares represent the tables from the database that has to be migrated, and the lines between them represent usages.
You quickly spot that your database serves multiple systems. You also notice that while you have strong table clusters around systems, there are also tables that are used by multiple systems. This gives you a strong insight into how the database should be partitioned and who should be involved.
This visualization is custom built for your problem and is based on several sources of data: the database schema, the database access logs, and some source code. It’s custom built because this is the only way to capture what is important for our problem.
Domain Discovery with Moldable Development
The above problem can be considered an architectural one, but suppose you want to extend your system to support discounts of prices. This is more like a domain-driven design scenario. You already know about the importance of the ubiquitous language and you are actively engaging in deep conversation with domain experts. You end up with this drawing on a whiteboard:
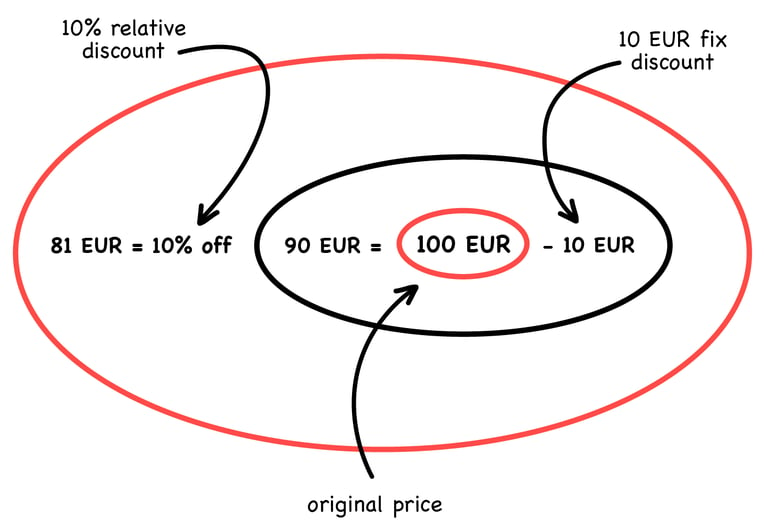 This is great. You have a concrete idea of how people see the discounting of prices. So, you go and implement. Of course, as it always happens along the way, you realise that a discounted price is also a price, and you change a few names here and there, too. For example, “price discounted by money” sounds better to you than “fix discount”, and once that is settled you also prefer “price discounted by percentage” instead of “relative discount”. These are not large changes, but they still diverge from the agreed common language and they should be made explicit the next time you have a conversation with your business colleagues.
This is great. You have a concrete idea of how people see the discounting of prices. So, you go and implement. Of course, as it always happens along the way, you realise that a discounted price is also a price, and you change a few names here and there, too. For example, “price discounted by money” sounds better to you than “fix discount”, and once that is settled you also prefer “price discounted by percentage” instead of “relative discount”. These are not large changes, but they still diverge from the agreed common language and they should be made explicit the next time you have a conversation with your business colleagues.
So, when the next session comes, what do you do? Drawing on the whiteboard is great when you don’t have a system. But, as soon as you do have a system, it should be the system that draws itself. In your case, when inspecting any price, you want to see the drawing from the whiteboard:
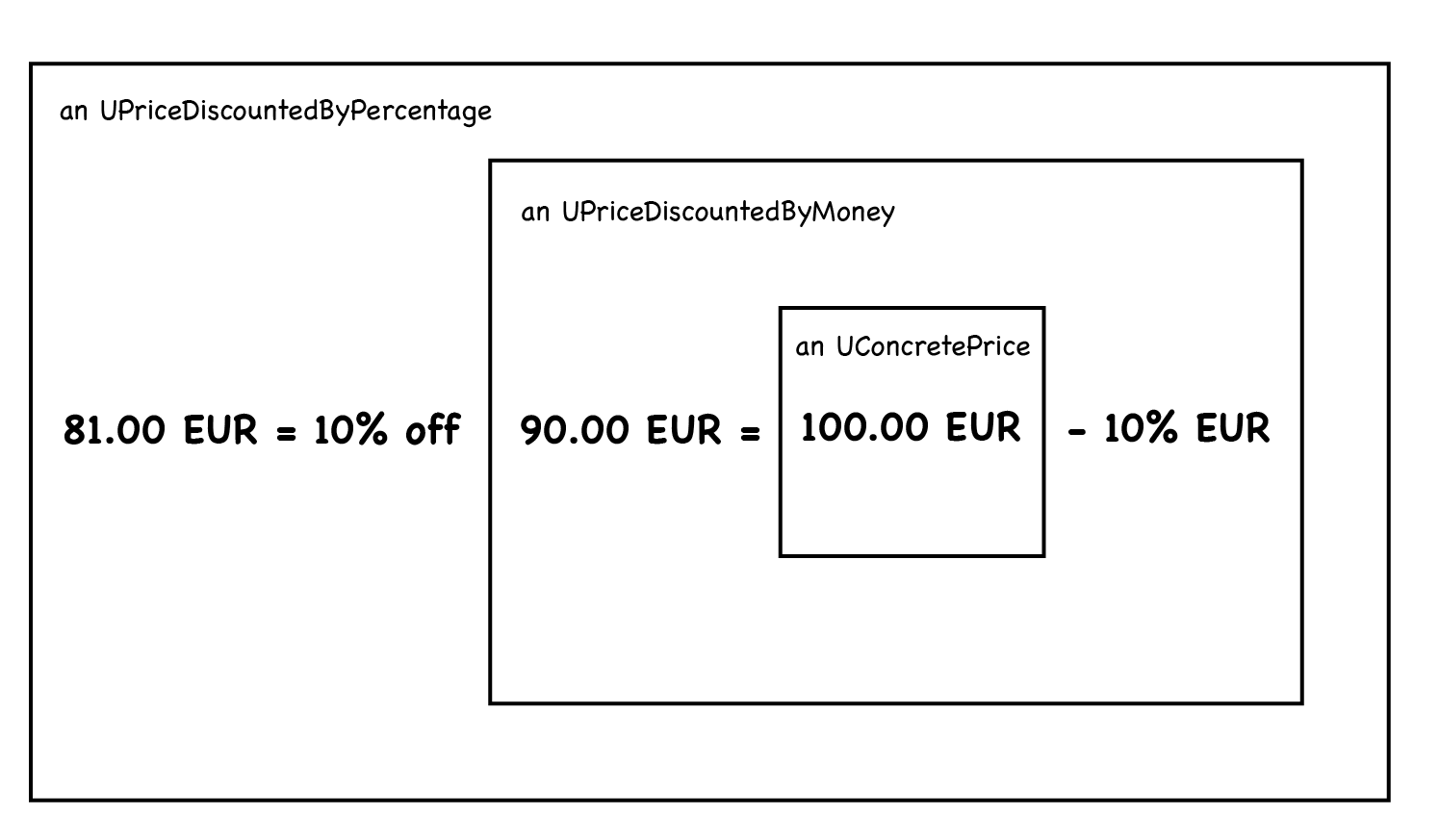
And, once you have the drawing, it provides the perfect basis to have a clarifying conversation and to explore the next steps:
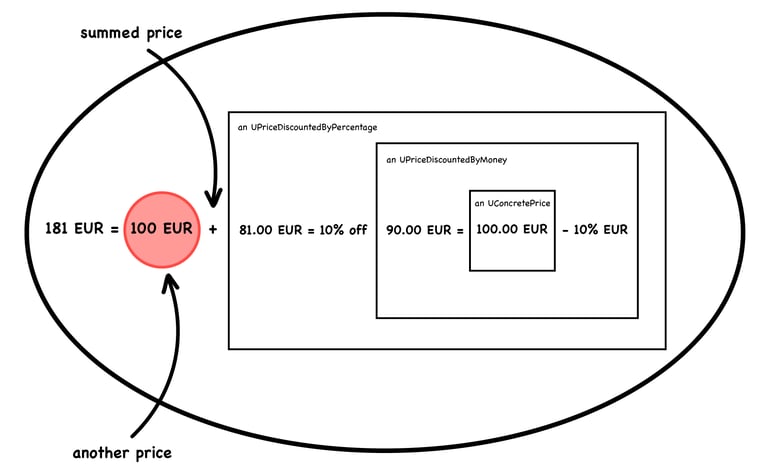 These are concrete scenarios that we encounter in our daily work at feenk. At first sight they are quite distinct: one is about an architectural issue, and another one is about the modelling of a domain; one concerns millions of lines of code, and another one relates to dozens of lines of code. Still, they have something in common—they are served through custom tools that are created for a context and that only make sense in that context. We create tools like these for all development problems we encounter in many distinct scenarios.
These are concrete scenarios that we encounter in our daily work at feenk. At first sight they are quite distinct: one is about an architectural issue, and another one is about the modelling of a domain; one concerns millions of lines of code, and another one relates to dozens of lines of code. Still, they have something in common—they are served through custom tools that are created for a context and that only make sense in that context. We create tools like these for all development problems we encounter in many distinct scenarios.
While these custom tools appear as cost, they are, in fact, multipliers. They are magic.
The Economics of Moldable Development
Most software engineering conversations today focus on how to construct systems, and as an industry we’ve poured a huge amount of time and energy into solutions for building code, from code editors to deployment facilities.Yet developers alone spend more than half of their time figuring out how existing systems work (for more on this see here.). In other words figuring out systems is the highest cost in a software team. Still, perhaps surprisingly, how this time is being spent is rarely, if ever, a subject of conversation, and therefore isn’t an explicit activity and isn’t optimised. We can do better.
The first thing to do is to talk about it. When you do so, you quickly discover that most of this time is spent reading through textual artefacts in some sort of editor. The problem is that reading source code is the most manual possible way to extract information out of data. And that’s exactly what all stakeholders do. They need to make decisions about where the system should be evolved, and for that, they need information about the system.

The time spent by developers reading code is something we can measure directly, but the real cost lies in the resulting decisions, which are often based on an impartial or inaccurate understanding. Given these costs and consequences, it’s more interesting to regard software development as a decision-making activity rather than a construction one. And therefore, we should optimise for it, too.
Moldable Development offers exactly that: a systematic approach that enables effective decision making by creating custom tools that summarise the system. Decisions require accurate information, and given the size of systems we can only gather that information through automatic means. However, as systems are also highly contextual, the automation must also be bespoke, created within the context of the system. This is the essence of Moldable Development.
Although this approach feels very unusual there are some parallels elsewhere in software practice. For example, it has some similarities to testing, where you create a test specifically to capture what’s valuable in the context of that system. A test is typically not reusable in another system, and that’s exactly what makes it valuable. Similarly, for views about systems to be valuable, they should be created for your specific problem.
There are also parallels in how data science facilitates decision making about large amounts of data through narratives created specifically for a problem. The same principles apply when we make decisions about software systems, as everything about systems is data, including code, configuration or logs.
Custom tools summarise the system in condensed views, and by doing so, they make the system approachable. Constructing custom tools does require effort, but they bring with them a new feedback loop. Like any other major feedback loop, Moldable Development implies new skills and a new way to exploit these skills. The promise is that you can create new kinds of value both at the technical and at the business level. We already saw brief examples of how steering agile architecture or domain discovery could be. The same skills and techniques can also help well beyond that in areas like knowledge management or onboarding new developers. One investment. Multiple returns.
The Mechanics of Moldable Development
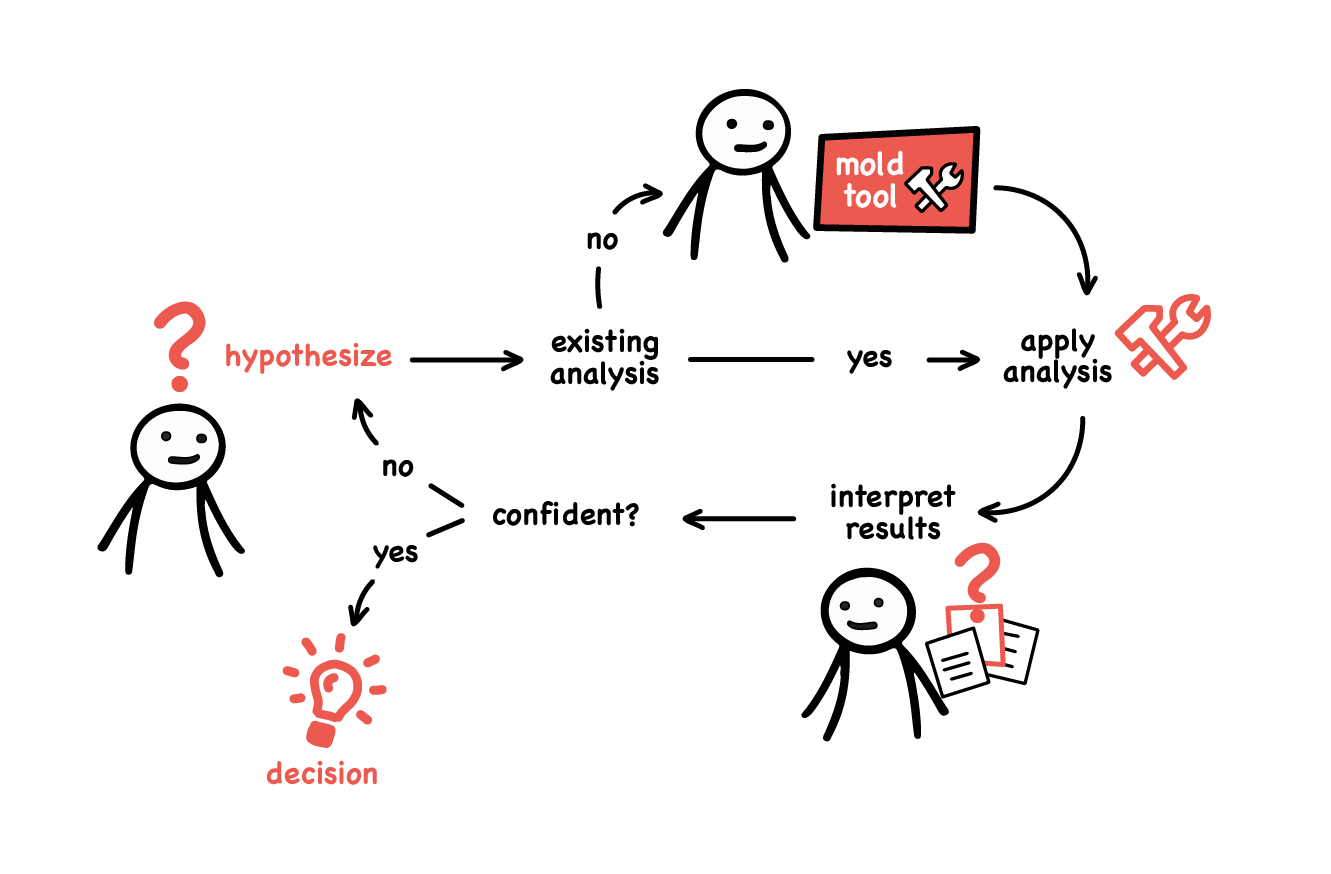
It all starts with a hypothesis. For example, a hypothesis can be “different systems are using different parts from the database”. You check the hypothesis through an analysis. If you are confident in the results, you make a decision. The decision is always the goal. For example, say you learn that indeed, different systems do use separate parts of the database. The decision of how to move on will be quite different than if it turns out that the tables are shared by multiple systems.
If this all sounds like the scientific method, it’s because that’s exactly what the basis is. But there is a little divergence. The thing is that software is highly contextual. As a consequence, we can predict classes of questions people will have, but we cannot predict specific questions. Thus, for your specific context, it’s probable that you have no appropriate tool to help you perform your analysis. That’s when you need to mold a tool that matches that context.
Why? Because if you don’t build a tool, you will end up reading, and reading simply does not scale. Mind you, the tools we talk about are primarily intended for replacing reading. By creating them, you essentially document what you want to read and how you want it summarised, and you let the computer do the tedious work.
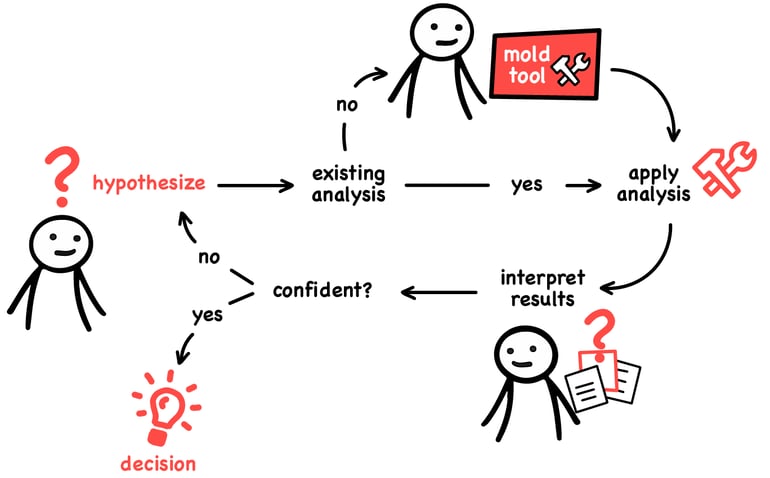
There are two roles involved. The stakeholder owns the problem and, given the right information, knows how to act. Anyone involved in the system, from the developer to the CEO, can and should be a stakeholder. The facilitator knows how to build tools much like how a data scientist does.
Of the two, the stakeholder is the most difficult to train. The facilitator is a technologist and relies on skills that can be learnt similarly to other technologies. But the stakeholder is a qualitative skill, as the upper bound value of any assessment lies in the quality of the question.
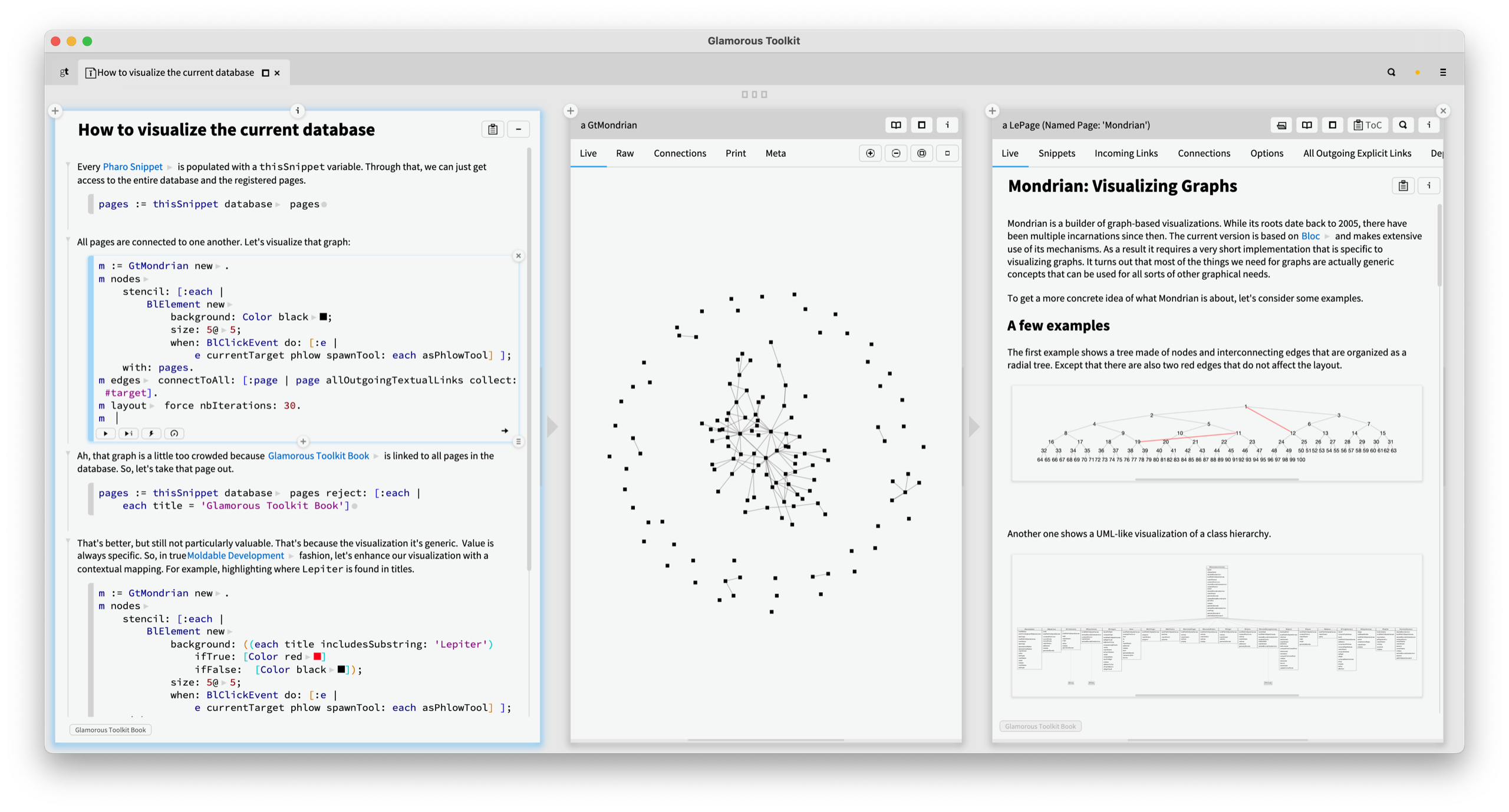
Glamorous Toolkit: The Moldable Development Environment
To show how Moldable Development works in practice, we construct Glamorous Toolkit, a Moldable Development environment that makes the construction of custom tools inexpensive.
Glamorous Toolkit is free and open-source and is available under an MIT license. It is built in Pharo, a Smalltalk system, but can be applied to other systems such as those written in Java, C#, C/C++, and JavaScript. It is also an extensive case study as we are developing it following Moldable Development. For example, in the distribution, we have more than a thousand custom tools that we have constructed to support our work whilst developing the environment itself.
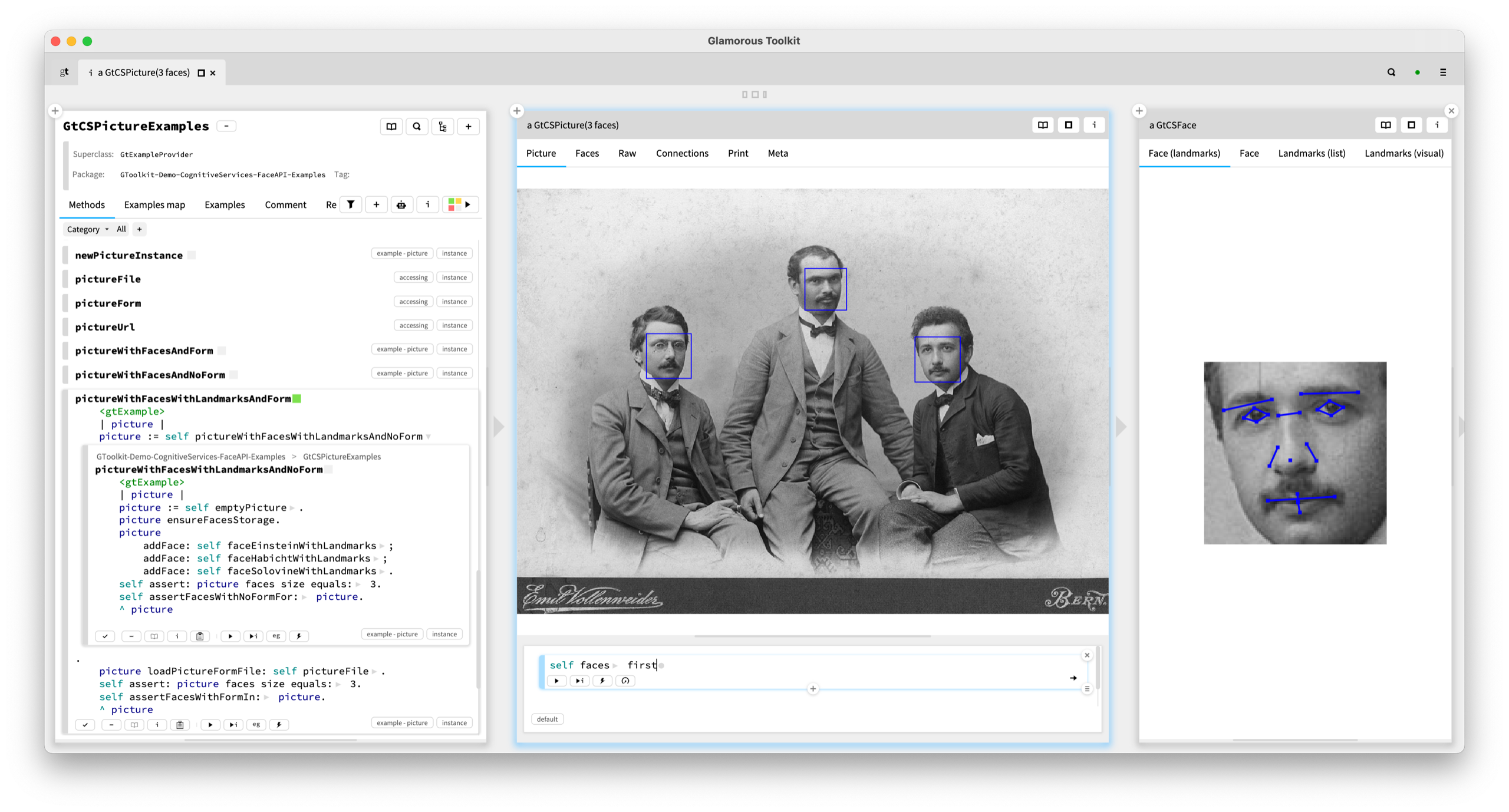
These views can be combined in many ways to support various investigations. They also provide examples of how to build such views for new problems. Combined with the ability of a multi-language notebook and knowledge management system, we can form many narratives about systems, too.
The first target of Glamorous Toolkit is educational in nature. We want people to experience first-hand what Moldable Development can be. We are convinced that this is a large space and that once we start a global conversation, many new angles will emerge. That is why Glamorous Toolkit is an extensive case study itself, and that is also why we are using it in many different industrial scenarios.
Adopting Moldable Development
If I have persuaded you that Moldable Development is worth looking at, and I hope I have, I should also say that there is a lot to learn and apply in practice. We spent more than a decade researching this space, and we’re still discovering new things. Like anything worth learning, it’s not a trivial journey. But the good news is that you can improve the status quo within a relatively short amount of time.
The first thing to do is to talk explicitly about how you reason and make decisions about your systems. The conversation can and should happen at various levels of granularity from how a single developer can find what API entry point is most appropriate for a use case to how a large migration should be steered. Look for artefacts, like diagrams or tables, that are created manually and ask how else could they be generated out of the system. This exercise alone will return the investment manyfold.
To practice how views can be created, you certainly should play with concrete technologies. Glamorous Toolkit can be a good choice to explore what’s possible, but there are other options, too. For example, as the facilitator is not that different from the data science skill that you likely already have internalised, use notebooks to construct narratives about your system. Just start, and you will likely begin to notice opportunities all around you.
For all these exercises, always pick concrete problems. Don’t ask “what are the dependencies in my system?” as this is a generic question that makes sense in any system, and hence, has little value. Instead, ask something like: “are there dependencies between these two modules I want to split that do not go through the designated API?” This question is about something contextual (those two modules), it has direct value (you want to split them) and is specifying what is interesting and what is not (API and non-API dependencies). Ask questions like these, and they will guide the kinds of tools you will want to build.
There is certainly more to say about how to adopt Moldable Development and about the implications of doing so. I could continue talking about how once you can extract information about your system at any time and at close to zero cost, the whole business can act differently and much faster. I could talk about how you can steer agile architecture by involving everyone in the team at the cost of minutes per day. I could talk about how Moldable Development can be applied to many seemingly distinct domains like monitoring, security or data reverse engineering. Or, I could talk about how you can decrease the domain discovery costs dramatically, and even give pitches to investors directly from the development environment well before there is a system in place. But this is not the right space for it.
Instead, I’ll say one thing—these custom tools can make the inside of the system feel beautiful. Imagine feeling joy when working with a legacy system.