

Is it a networking tool? Is it a security tool? Is it an observability tool? Is it a service mesh? Is it a load balancer? Yes, yes, yes, yes, and, yes… and so much more. So WTF is it really? Here’s my elevator pitch answer: the Cilium project aims to be how we all connect, observe and secure workloads, using eBPF as the core technology to provide solutions in an efficient, Cloud Native way.
eBPF gives applications superpowers through custom programs that attach to events in the kernel, and the Cilium project consists of a team of superhero applications powered by eBPF that you can deploy to help you efficiently manage container clusters. That’s right, I said a team of superheroes. Cilium is a project with several application deliverables: Cilium, Hubble, and Tetragon—The Justice League of Container Connectivity or the eBPF Avengers (you pick the comic book universe continuity team-up that works for you: all I know is I identify strongly with Gleek from the classic Super Friends cartoon).
No, seriously WTF is Cilium?
Cilium was originally created by Isovalent, and open-sourced in 2015. Like the major superhero franchises, it’s very popular, with 14,000+ GitHub stars, 500+ contributors across the various repos in the Cilium GitHub organisation, and 14,000+ users registered for the Cilium community Slack. More importantly, these superheroes are active in the real world—Cilium is widely deployed in production environments by organisations in all sorts of verticals, like media, finance and search. All three major cloud providers now support Cilium in their Kubernetes service offerings: Google in GKE data plane v2, Amazon in AWS EKS Anywhere, and Microsoft in Azure AKS.
Cilium joined the CNCF at the Incubation level in October 2021, and in October 2022 applied for graduation status. Graduated project status is a major milestone for any CNCF project and indicates the project has a sustainable community of contributors,is widely adopted, and is well on its way to becoming an expected part of any cloud-scale stack.
The Cilium superhero family tackles the three main pillars of container networking cloud scale challenges:
- Connectivity
- Security
- Observability
I can’t stress this enough, Cilium is here to solve these problems at scale. So let’s start by talking about scaling connectivity securely, which Cilium achieves through the power of eBPF.
Scaling Cloud Native connectivity
The big advantage of Kubernetes is its dynamic nature, which gives it the ability to scale services on demand, and reconcile pods and services to their desired state in the event of a problem. For example, if a node goes down, Kubernetes will automatically restart pods on another node in the cluster to make up for its loss. But this dynamism creates headaches for traditional networking, as IP addresses are reassigned and reused across the cluster. For human operators, there is an observability problem, as you can no longer make assumptions about the IP addresses that match particular workloads. And in the underlying networking stack, some components weren’t designed for the constant re-use of IP addresses, leading to performance issues at scale.
Cilium injects eBPF programs at various points in the Linux kernel, providing a connectivity layer fit for the Cloud Native era that uses Kubernetes identities rather than IP addresses, and allows for bypassing parts of the networking stack for better performance.
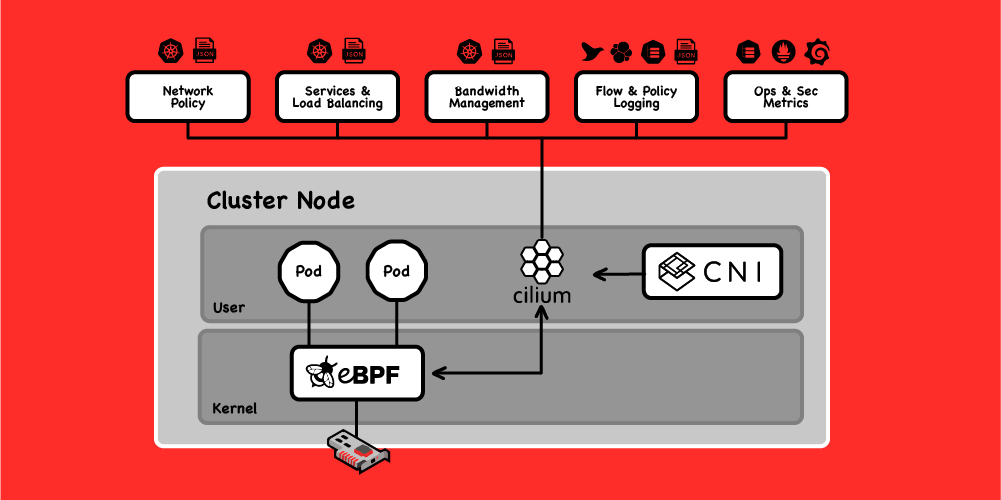
In Kubernetes, pods typically run their own network namespace, which means that packets have to traverse a network stack twice—once in the pod namespace, and once in the host. Cilium allows for bypassing significant parts of the host stack, leading to significant performance gains. Like the Flash, it’s lightning fast.
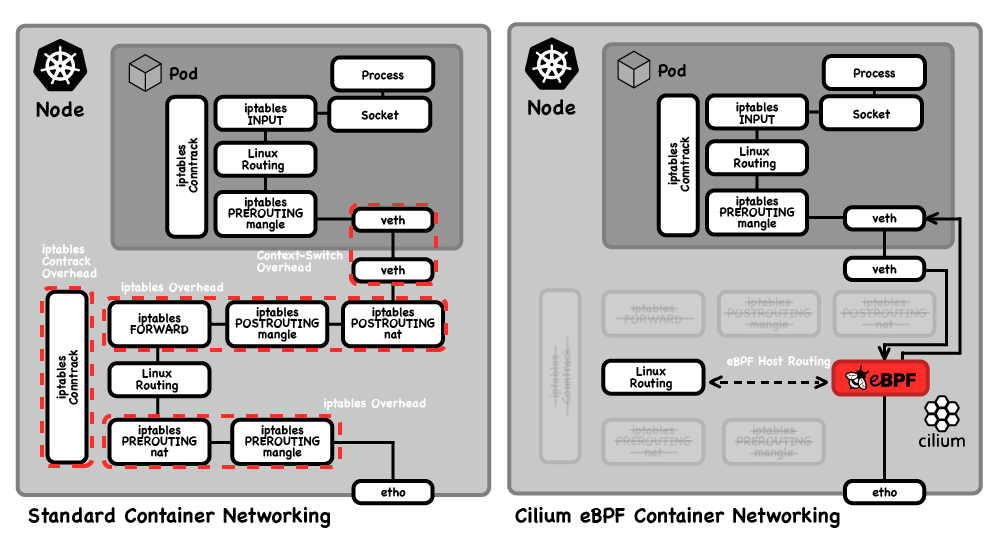
You can see from the diagram above that Cilium can bypass iptables in the networking stack. This is a component that wasn’t designed with the behaviour of Kubernetes in mind, and performance of iptables typically degrades at scale because of the dynamic nature of Kubernetes. In large clusters with many nodes, pods, and services, there are generally large numbers of iptables filters and forwarding rules, which need updating as pods come and go. What’s worse is that with iptables, changing one rule means the entire table gets rewritten. As a deployment grows, the rules take longer and longer to converge every time a pod is created or destroyed, causing significant delays in correct operation at scale.
Instead of iptables, Cilium keeps track of pod endpoints in eBPF maps. These are data structures stored in the kernel that Cilium’s eBPF programs access to make highly efficient decisions about where to send each network packet.
Cilium identity-based network policy
Traditional Kubernetes network policy enforcement has been based on iptables filters, which suffer from the same scale problems. Cilium takes a different approach, using Kubernetes labels to assign a security identity for pods (similar to the way Kubernetes identifies which pods are assigned to each service using labels). Network policies are represented in eBPF maps, and allow super-fast lookups from these maps as network traffic enters or leaves a Cilium-managed node to make decisions on whether to allow or deny packets. It’s like having a tiny little superhero, like Atom, sitting in the network stack checking packets as they enter and leave a node’s network interface. Those eBPF programs are super tiny and super fast.
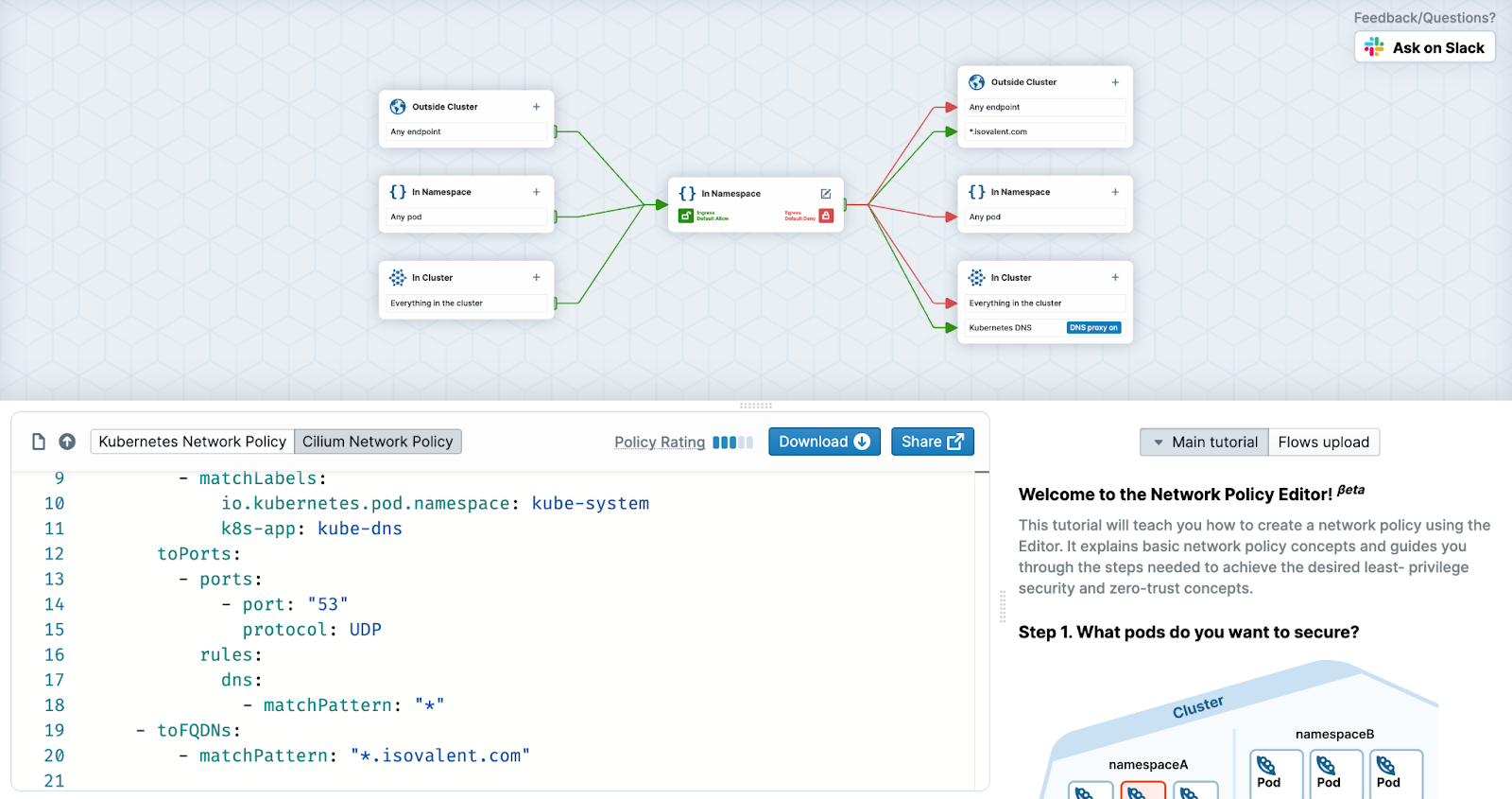
But wait there’s more! With Cilium, you can write application-aware L7 policies! For example, you can write a policy that restricts access between pods to just allow a specific HTTP REST method on a specific API endpoint. You can also filter traffic based on fully-qualified domain names or IP addresses for when your traffic needs to communicate outside the cluster. If you're unfamiliar with all the ways you can use Cilium’s network policy features, you can explore network policies, and get a visual understanding of their effects on traffic, at networkpolicy.io. The Cilium project also has a great walk-through for getting started with L3/4 and L7 network policy using your own live Cilium deployment.
Transparent encryption
Policy enforcement isn’t the only aspect of network security that Cilium provides. Zero-trust networks have rapidly become best practice, and transparent encryption is perhaps the easiest way to ensure that all network traffic is encrypted. You can flick a switch to have Cilium create IPsec or WireGuard connections through which traffic passes. Through the magic of eBPF, this happens at the kernel level, so your apps don’t need any changes for their traffic to be encrypted. Cilium’s transparent encryption is like giving your nodes Professor Xavier’s telepathic superpower to securely communicate with different teams of X-men. (I know, I know I jumped comic book universes with that one.)
Integrating with legacy infrastructure
Cilium also makes it easy to connect your containerised clients and services with your legacy infrastructure. Network traffic from your Kubernetes pods ends up looking like it's coming from pseudo-random IP addresses to your legacy services running on VMs in server racks in a data centre. Your legacy firewall infrastructure would very much prefer static IP addresses to deal with so it can tell friends from foes. Cilium has an Egress Gateway concept to route traffic meant for your legacy services through a specific egress node with a fixed IP address.
And going the other way, Cilium also supports Border Gateway Protocol (BGP) to make it easier to announce routes to your Kubernetes services to your networking infrastructure external to your cluster. Cilium has you covered both coming and going when integrating with your external services. Like Cyborg’s superpower, Cilium is able to integrate with new and old digital technologies and get them working together.
Cluster meshes
We’ve talked about integrating Cilium with external, legacy workloads, but what about multiple Kubernetes clusters? Do you need to treat connection from one cluster to another like just another external service? No! You can bring multiple Cilium-enabled Kubernetes clusters together and take advantage of Cilium’s identity model in really cool ways to help multi-cluster service configurations. Cilium calls this multi-cluster support a ClusterMesh.
With a Cilium ClusterMesh, you can designate global services with Kubernetes annotations, and Cilium will load balance access to service endpoints associated with that global service that exist in multiple clusters—with encrypted traffic if you desire. You can designate service affinity for those global services to prefer sending requests locally if the endpoints are healthy, failing over to remote service endpoints in other clusters if needed. Batman would love Cilium ClusterMeshes because they make it easy to have a contingency plan for a service. And we all know how much Batman loves his contingency plans.
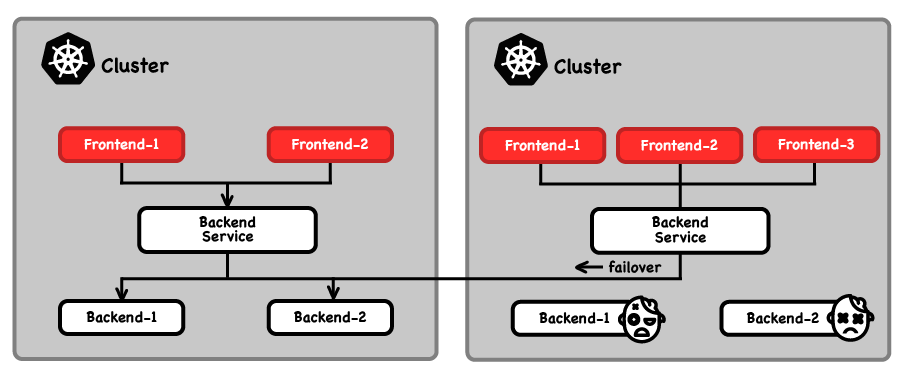
Simplifying cross-cluster fail-over is just one benefit: there are a variety of real-world multi-cluster use cases that become easier to implement inside of a Cilium ClusterMesh. Setting up a ClusterMesh is just a matter of making Cilium-enabled clusters aware of each other, and the cilium cli tool makes this process very simple. In fact I was able to spin up a global service failover Cilium ClusterMesh spanning both east and west US regions in Azure AKS in just a few minutes, using the Cilium project’s quick start guidance, without knowing much of anything about Azure AKS before attempting it for the first time.
Network observability
So far I’ve been focused on network connectivity and security, but Cilium can help with network observability at scale as well.
Network observability inside of a Kubernetes cluster gets very complicated. With pods constantly coming and going, and internal IP addresses re-assigned across different workloads as they scale up and down, watching the packet flow is difficult. Trying to track packets by IP address inside a cluster is futile. Even running an eBPF-powered tcpdump on a node isn’t going to be enough because IP addresses and ports are hard to match to workloads, especially when Kubernetes itself might be fighting you by rapidly re-commissioning pods to try to solve the problem you are diagnosing. How do we gain insight when there is a problem with one of the microservices or our network policy?
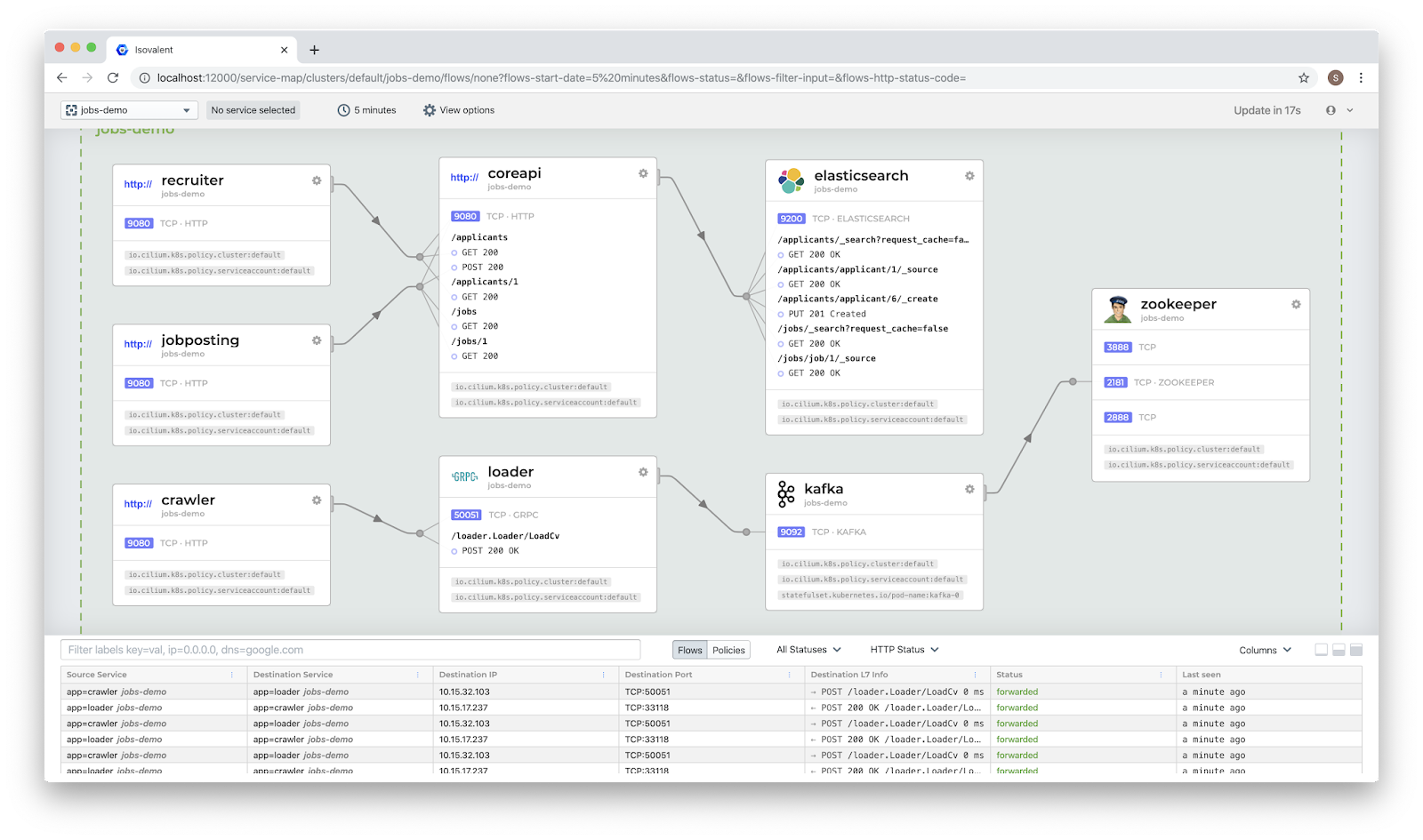
It’s time to introduce you to Cilium’s super friend Hubble. Hubble’s superpower is a kind of x-ray vision—pick whichever Kryptonian you want, personally I like Zod for this metaphor because his name rhymes with “pod”. Hubble sees past the surface noise of the dynamic IP addressing, presenting network flows with their Kubernetes identities, so you can clearly see how pods and services are communicating with each other and with the outside world. Hubble builds on what’s possible with Cilium to create a first-class container networking observability platform capable of showing you the details of flows not just at network Layers 3 & 4, but also at Layer 7, showing you the details of protocol flows like HTTP and gRPC.
The Hubble UI takes this even further, providing a graphical depiction of service dependency maps along with network flow details.
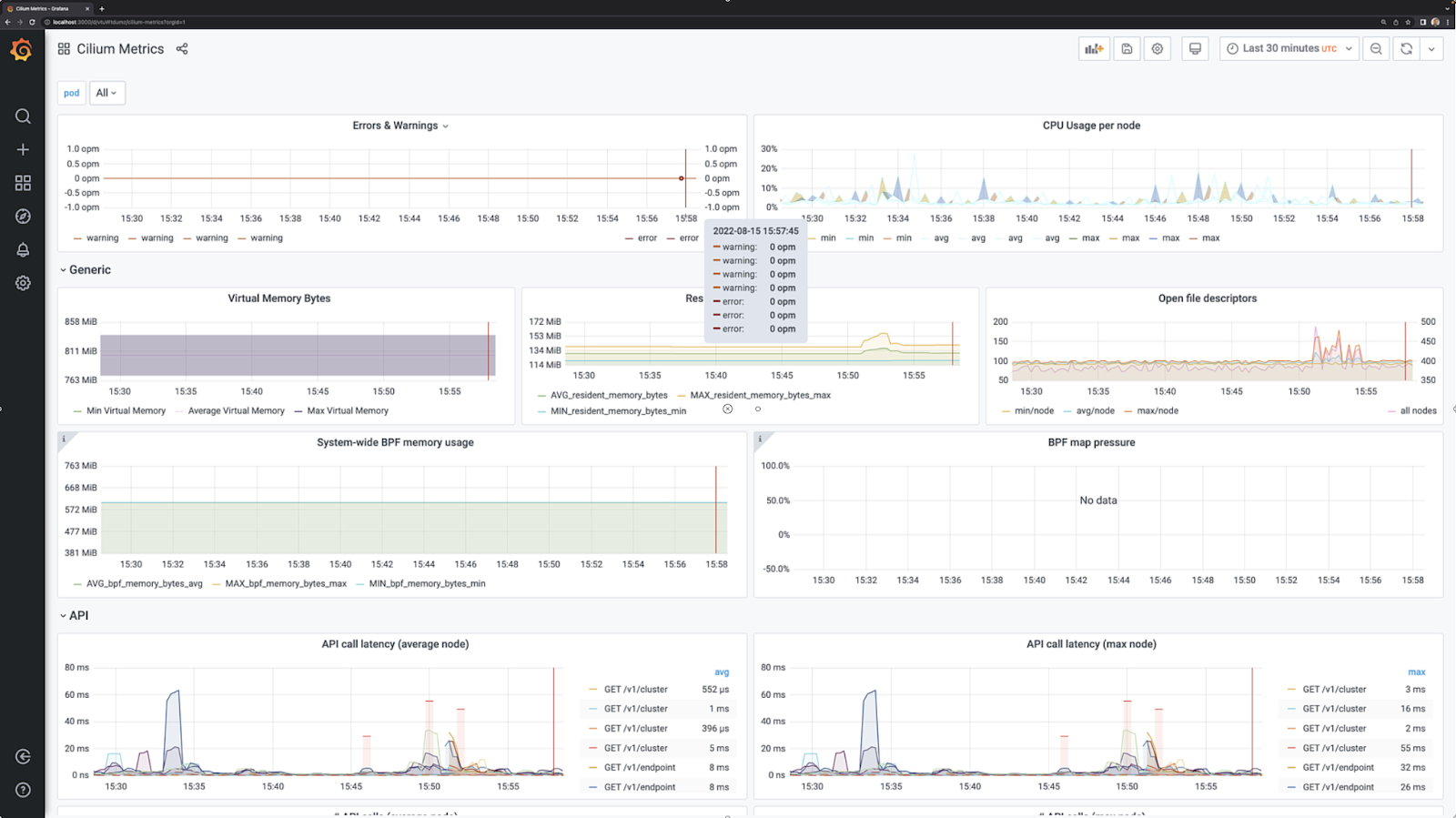
Cilium and Hubble together expose a wide variety of metrics, traces and logs that are invaluable for observing your network and diagnosing issues. You can pull this data into Grafana for easy visualisation, and, like Barbara Gordon’s alter-ego Oracle, easily answer all sorts of questions about your network. For example, if you want to know the rate of 4xx HTTP responses for a particular service or across all clusters, or if you want to know the latency of request/responses between the worst performing services, Hubble metrics have you covered.
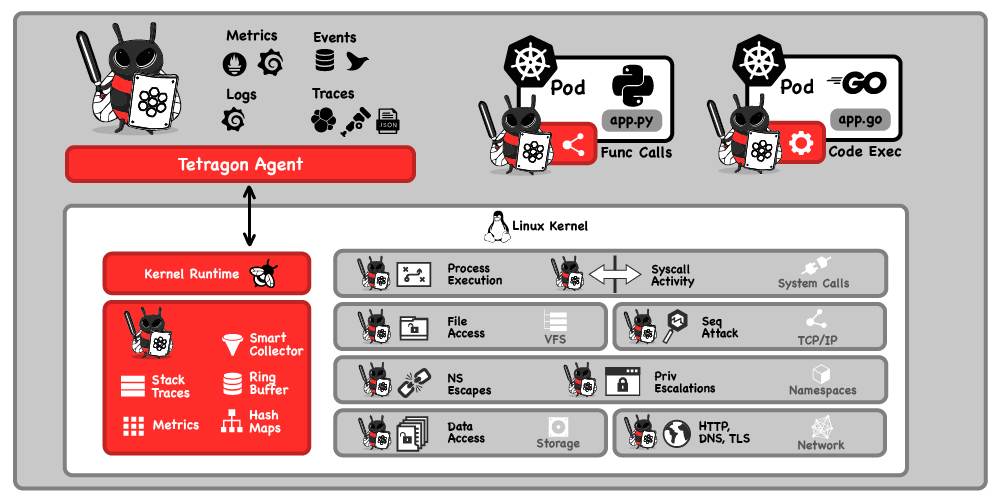
Runtime security: observability and enforcement
But container security isn’t just all about network policy, container runtimes benefit from security policy too. This is where Tetragon, the newest member of the Cilium Super Friends, steps into the light. Tetragon is laser-focused on using eBPF for runtime security observability and enforcement. Tetragon detects and can report a stream of security-significant events, such as
- Process execution events
- System call activity
- I/O activity including network & file access
Tetragon isn’t the first eBPF-powered security tool to emerge, but it brings a lot of new capabilities to the fight for container security. Where other projects hook into system calls at a superficial level, they’re subject to a time-of-check-to-time-of-use vulnerability where the parameters to a system call might be overwritten before they get to the kernel. Cilium engineers used their knowledge of kernel internals to hook into events at points that aren’t subject to this issue.
Tetragon’s TracingPolicy lets you configure what kernel events you want to observe, and define matching conditions and take action. What’s more, Tetragon provides contextual information based on Kubernetes identities. For example, if you want to detect access to a particular file or directory, you can configure a TracingPolicy that will emit logs that tell you exactly which process, running what executable, in which pod, accessed that file. You can even configure the policy to kill an offending process before the file access is complete. This is incredibly powerful and adds an entirely new approach to container security to help you limit the attack surface your containers expose. Like Shazam, Tetragon is empowered with the Wisdom of Solomon with vast amounts of knowledge and a finesse in judgement about how to take action.
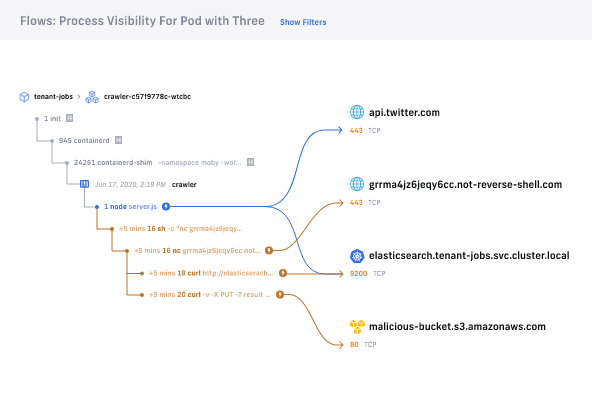
Tetragon can be used standalone, independently of Cilium’s networking capabilities. But imagine what you can do with a Tetragon & Cilium superhero team-up, combining network and runtime security superpowers so you can, for example, see the full process ancestry that initiated a suspicious network connection.
Sidecarless service mesh
You’ve seen that Cilium implements not just connectivity between Kubernetes services, but also provides observability and security features, and is able to act at Layer 7. Isn’t that very similar to a service mesh? Absolutely! And now, the Cilium superheroes assemble to provide service mesh functionality without the overhead of injecting sidecars into every pod, improving service mesh efficiency. How big of an improvement? Let’s take a look at the impact on HTTP latency processing between containers on the same node. There’s always going to be a cost to using an HTTP proxy but, when you use sidecars, you potentially pay that cost twice as microservices communicate with each other and traffic passes through both the ingress and egress sidecar HTTP proxy. Reducing the number of proxies in the network path and choosing the type of HTTP filter has a significant impact on performance.
Here’s a benchmark comparison, from a blog post diving into how the Cilium service mesh works, that illustrates typical latency cost of HTTP processing for a single node-wide Envoy proxy running the Cilium Envoy filter (brown) compared to a two-sidecar Envoy model running the Istio Envoy filter (blue). Yellow is the baseline latency with no proxy with no HTTP processing performed.
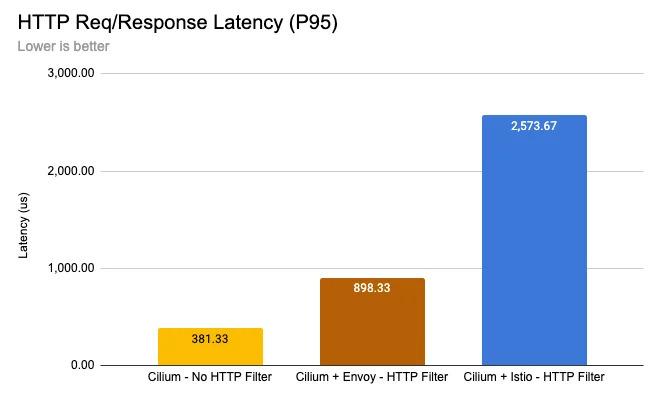
Cilium Service Mesh achieves this latency improvement partly by using an Envoy network proxy that’s run as part of the agent on each node, instead of attached to each pod as a sidecar. But the improvement is also partly because Cilium does as much as it can using eBPF before redirecting network traffic to that node-wide Envoy proxy. It’s an impressive one-two punch combo, worthy of Wildcat, leveraging timing and technique instead of brute force to get the results you want.
This isn’t a new approach—Envoy has been used in Cilium to implement Layer 7-aware network policies for years. To implement its sidecar-less service mesh, Cilium extended support for a fully compliant Kubernetes Ingress, and Gateway API implementation, along with a lower-level CRD that exposes the full capabilities of Envoy within Cilium. If you’re using a sidecar-based service mesh right now and starting to feel pinched by the resource costs associated with deploying service mesh sidecars in every pod, this is a great time to take a look at Cilium Service Mesh as a more resource-efficient replacement.
Not just Kubernetes
As I bring this blog post to a close, I need to point out that while I’ve been talking about Cilium in the context of Kubernetes clusters, Cilium isn’t limited to just Kubernetes. The benefits Cilium brings to connectivity, observability and security can be realised for workloads outside of Kubernetes too. For example, Cilium can be used as a stand-alone load balancer and has shown impressive benefits in a real-world production environment.
Superheroes, assemble!
If any of this sounds exciting to you and you want to get involved with this superhero franchise, you can join the Cilium project community and sign up for the community newsletter. And if you want to give Cilium a try for yourself, head over to the Cilium project website and dive in using the getting started resources.