
WTF is a Service Mesh? A Service Mesh is a system that carries the requests and responses that microservices send each other. This traffic ultimately travels from Pod to Pod the same way it always has, but by passing through a Service Mesh layer as well much more advanced observability and control is possible. Think of a Service Mesh as a smarter network.
Service Meshes are at the forefront of Cloud Native infrastructure. As Kubernetes revolutionised compute—the execution of services—Service Meshes are a massive value-add in networking. They’re also replacing a lot of boilerplate that used to happen in application code, but which is better done by the infrastructure.
Much as projects like Terraform made the infrastructure team’s lives better, a Service Mesh is something that microservice developers and owners can use to better operate their applications. Service Meshes also augment the features of these applications, offering real top-line value, not just saving cost.
Operation
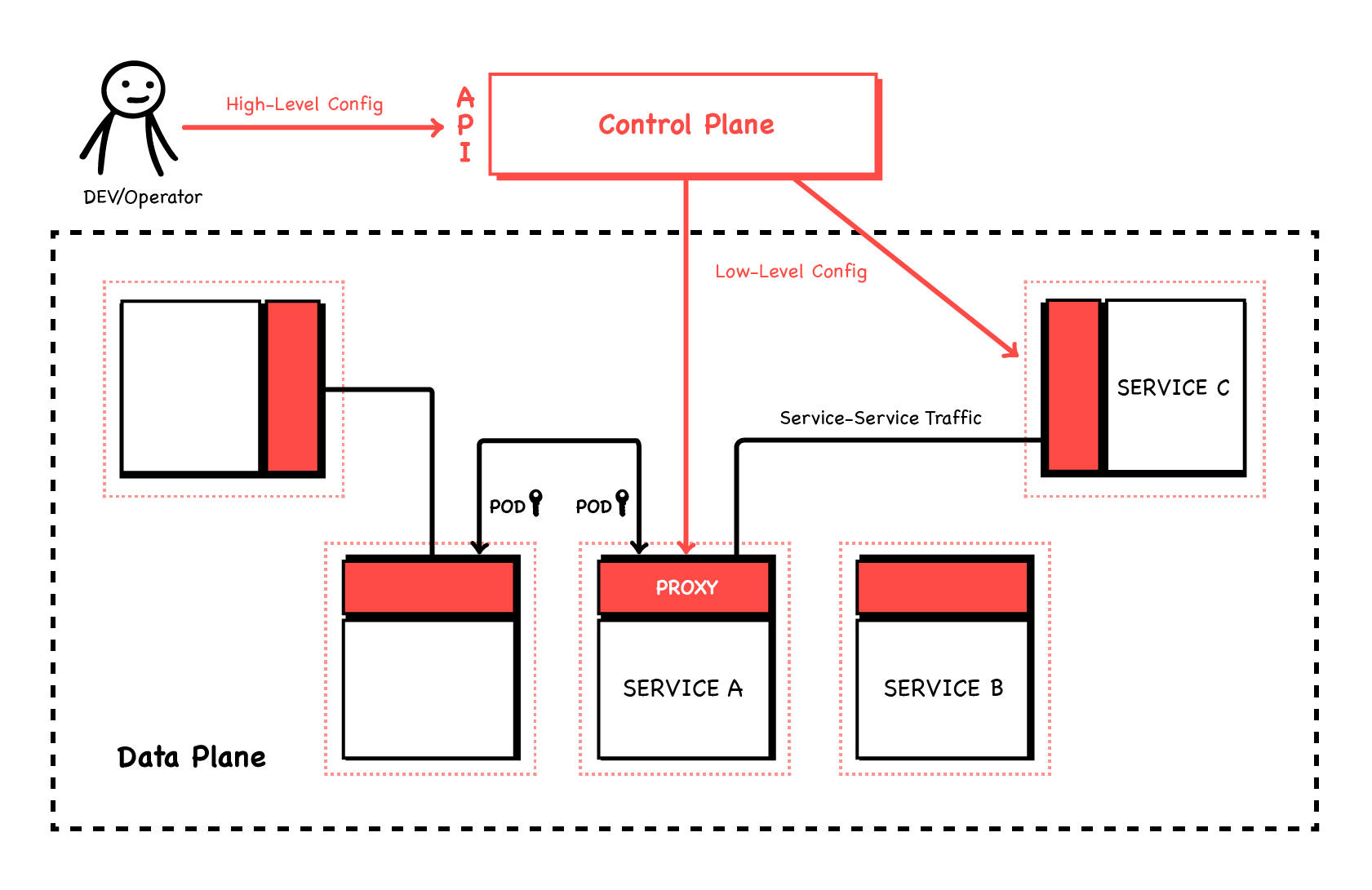
The internal workings of a Service Mesh are conceptually fairly simple: every microservice is accompanied by its own local HTTP proxy. These proxies perform all the advanced functions that define a Service Mesh (think about the kind of features offered by a reverse proxy or API Gateway). However, with a Service Mesh this is distributed between the microservices—in their individual proxies—rather than being centralised.
In a Kubernetes environment these proxies can be automatically injected into Pods, and can transparently intercept all of the microservices’ traffic; no changes to the applications or their Deployment YAMLs (in the Kubernetes sense of the term) are needed. These proxies, running alongside the application code, are called sidecars.
These proxies form the data plane of the Service Mesh, the layer through which the data—the HTTP requests and responses—flow. This is only half of the puzzle though: for these proxies to do what we want they all need complex and individual configuration. Hence a Service Mesh has a second part, a control plane. This is one (logical) component which computes and applies config to all the proxies in the data plane. It presents a single, fairly simple API to us, the end user. We use that to configure the Service Mesh as a logical whole (e.g. service A can talk to service B, but only on path /foo and only at a rate of 10qps) and it takes care of the details of configuring the individual sidecars (in this case identifying the sidecar alongside Service B,configuring it to recognise which requests are from Service A, and apply its rate-limiting and ACL features).
 Any HTTP proxy implementation could be used for the sidecars (although they all have different features). However modern ones like Envoy are well-suited as they can be configured and reconfigured by a network API rather than consuming config files. They’re also designed so that they don’t drop traffic during reconfiguration, meaning uninterrupted service.
Any HTTP proxy implementation could be used for the sidecars (although they all have different features). However modern ones like Envoy are well-suited as they can be configured and reconfigured by a network API rather than consuming config files. They’re also designed so that they don’t drop traffic during reconfiguration, meaning uninterrupted service.
Features
Observability
One immediate benefit of implementing a Service Mesh is increased observability of the traffic in the cluster.
Lyft was one of the pioneers in the Service Mesh space (and the authors of Envoy!), and this is a benefit they talk about getting immediately.
With all of the requests to our services running through sidecars, they’re in a perfect position to produce logs, metrics, and trace spans documenting what they see. This is nothing services can’t do of course, but now they don’t have to. Consistently-labelled statistics are generated for all workloads, with no code needed in the services, and all are sent to the same central collection point (such as a Prometheus server). This means, for example, that there is now one place to go to see p99 latency for all services, meaning you can easily spot outliers. Because these are HTTP proxies, they produce these statistics at Layer 7—e.g. latency broken down by HTTP path and method. It’s worth saying that although HTTP is by far the most common Layer 7 protocol in use, and very well supported by Service Meshes, it’s not the only one. Depending on the Service Mesh and hence its proxy implementation, most can see “inside” HTTP to give stats on gRPC, as well as understanding other TPC protocols like postgresql and Kafka.
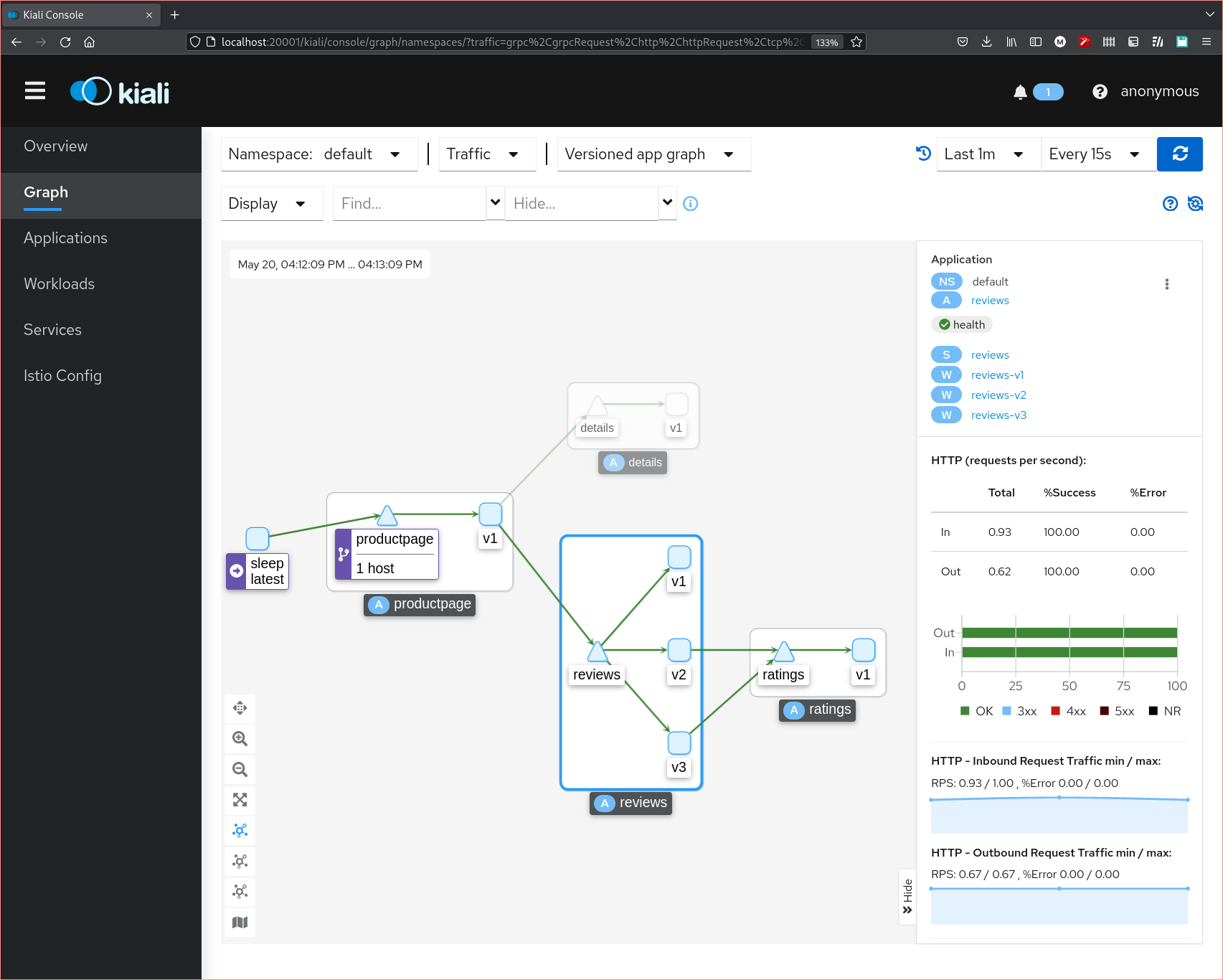 The Kiali software connected to an Istio instance, displaying a live call graph for several microservices. On the right you can see traffic success and rate metrics for the selected reviews service.
The Kiali software connected to an Istio instance, displaying a live call graph for several microservices. On the right you can see traffic success and rate metrics for the selected reviews service.
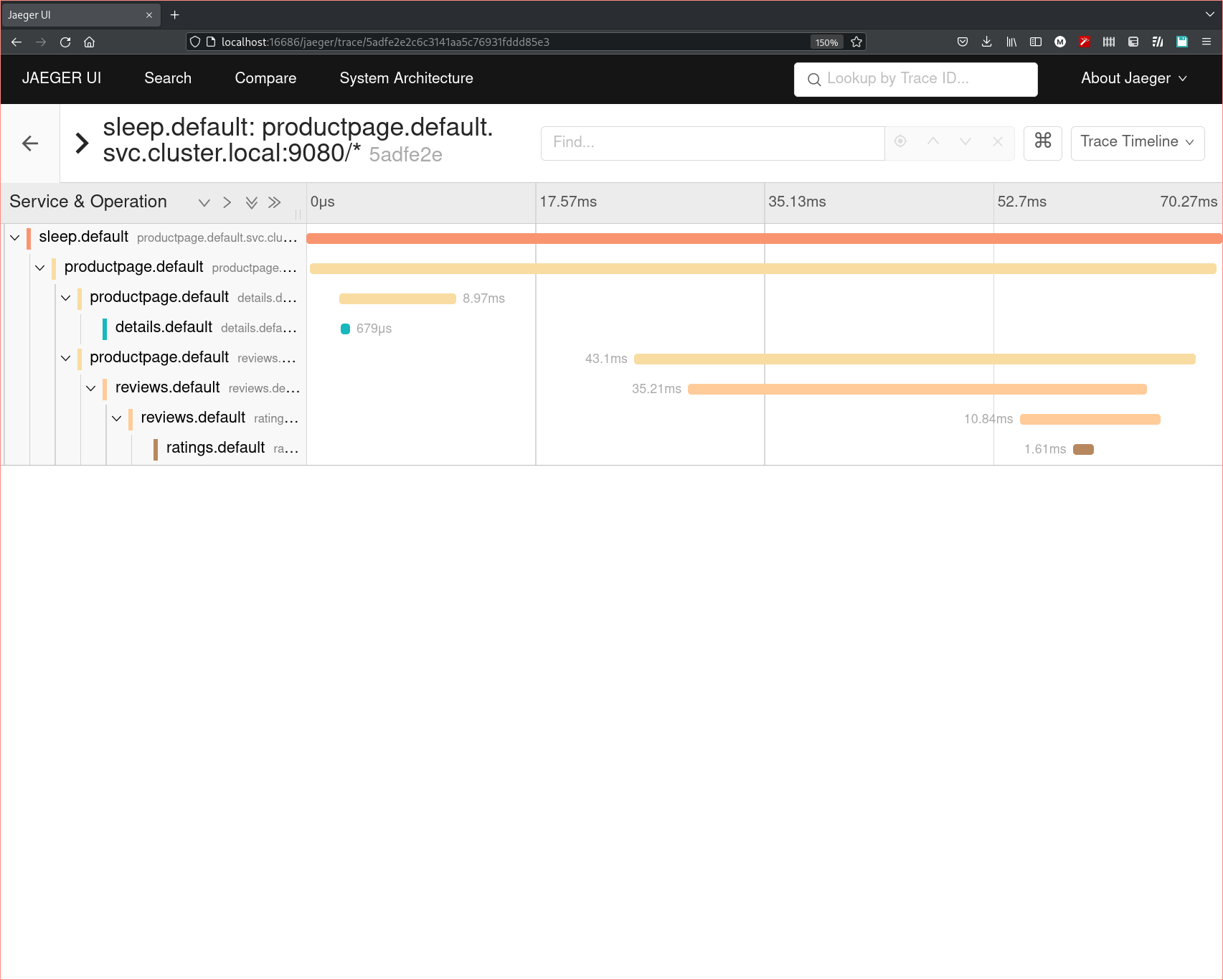 Distributed trace spans showing all of the traffic for one user request to the same microservices shown above.
Distributed trace spans showing all of the traffic for one user request to the same microservices shown above.
This first feature comes for “free”: just inject the sidecars to get the traffic flowing through them, and there’s the observability. That said there are a couple of caveats to be aware of.
The first is that trace events are automatically produced at the entrance and exit of each service, but for them to be attributed to useful spans, services must forward the set of tracing headers. This requires cooperation from the application code, forwarding the necessary headers.
The second is that the sidecars do have some impact on performance since each extra hop in and out of the sidecar for request and response will inevitably add some latency. I won’t quote any numbers here because they’re both context-specific and can quickly become out-of-date, but good independent articles on the subject do exist, and your best bet as ever is to test your use cases in your environment, and compare the results to your performance requirements.
We should note as well that there is a theoretical cap on bandwidth (qps) imposed by the processing rate of the proxies, but this will likely be a non-issue as your services will be slower, unless they’re highly optimised (or written in Rust 😉 ).
Routing
If the previous Observability features were “passive”, we’re now onto “active” Service Mesh functions. These actions aren’t taken by default because they interfere with traffic flow, but if you choose to configure them they can offer great power and flexibility when building systems of microservices.
Since every traffic hop passes through its data plane, a Service Mesh can route traffic between microservices in sophisticated ways. For example, the following YAML would configure the Istio Service Mesh to intercept all traffic heading for service-b sending 90% to the incumbent version and 10% to a new test version (destination.host items are Kubernetes Services).
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: service-b
spec:
hosts:
- service-b
http:
- route:
- destination:
host: service-b-v1
weight: 90
- destination:
host: service-b-v2
weight: 10
These percentages can be as precise as you want: the raw-Kubernetes “hack” of running 1 v2 Pod and 99 v1 Pods to get a 1%/99% split isn’t needed for example. With layer 7 routing the possibilities are myriad. Other examples include
- Inspecting the HTTP headers and sending, say, just people with
Accept-Language: en-GBto v2 because perhaps we haven’t had a chance to translate our new version yet and want to release it just to English speakers. - Routing GET requests for a certain HTTP path to a caching service layer
Resiliency
With the move from monoliths to microservices, what used to be a simple function call is now a network request. Function calls are effectively infallible and instant. Network requests on the other hand can fail, partially succeed, and/or be very slow. Since cascading failures can be hugely problematic, our services need to be able to cope with and contain these kinds of problems rather than cascading the failure throughout the system. Ideally things would gracefullly degrade at a micro- and macroscopic level. With a Service Mesh, this is something else that doesn’t need to be coded into each and every microservice—it’s not a business logic concern so deferring it to the infrastructure is preferable, and we can simply configure the Service Mesh to make the microservices appear to behave correctly in the face of failures. For example, this Istio configuration snippet enforces a timeout of 1s on “service-c”: if “service-c” doesn’t reply to its caller within 1 second, the Service Mesh will intervene, aborting the request and returning an HTTP 504 to the caller (an indication that the proxy, acting as a gateway, has timed the request out on the caller’s behalf). This saves the calling application code from having to manage its own request timeouts and deadlines.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: service-c
spec:
hosts:
- service-c
http:
- route:
- destination:
host: service-c
timeout: 1s
The flipside of coping with timeouts and errors from services (faults) is injecting them. This may sound strange, but when we split the monolith into microservices we turned a self-contained, possibly synchronous system into a distributed one. Distributed systems are hard, and one way of assuring their reliability is to test the various issues that could befall them, which now includes erroneous (HTTP status 500), missing, or delayed responses to network calls. A Service Mesh can inject these faults allowing us to test how systems react to failures, under controlled conditions. Let’s say we want to release a new version of a service: we could make the requests it sends return errors 50% of the time, and timeout the other 50%. The services it’s calling aren’t that buggy (we hope!), but we can simulate that to see how our new version would cope on a really bad day. We could also inject faults only for requests that opt in to testing by setting the header x-testing: true. Again, the possibilities are nearly endless. We can even inject faults at a low rate into the production environment network all the time, akin to running a Chaos Monkey for compute workloads. The idea here is that if a service’s downstreams are too reliable its authors become complacent about handling errors, so we make sure they never seem 100% perfect, no matter how good a job their teams do.
Security
Last, but absolutely not least, Service Meshes can greatly improve the security of your network and services. Whilst HTTPS is ubiquitous for customers to connect to our external-facing services over the internet, most of our internal network (including Kubernetes clusters) use plaintext HTTP. This is based on the assumption that we don’t need security within our perimeter because it’s impenetrable. Implicit in that is the assumption that all the Pods in our clusters are also 100% trusted and won’t try to access anything they shouldn’t. With the growing threat posed by supply-chain attacks this is much less true than it used to be. The solution is an approach called zero trust, which basically states that internal services are treated as untrusted clients just like any random device on the internet would be; they don’t gain special privileges just by being on our network. A Service Mesh can enforce the security policies needed for zero trust.
The first thing to do is to encrypt all traffic on the network so it can’t be sniffed by a compromised workload. We can do this by using HTTPS. This is conceptually simple; we just need each service to have a TLS certificate so it can serve TLS, and clients need a copy of the Certificate Authority so they can verify it. However if you’ve ever tried to roll this out across your services you’ll know it’s a nightmare to distribute and rotate individual certificates to services, but with a Service Mesh this isn’t something the applications have to manage. They can talk plaintext HTTP (as both clients and servers) and the sidecar proxies will upgrade that to HTTPS, i.e. the server-side proxy serves HTTPS by presenting a TLS certificate and the client-side proxy validates that when it makes the connection. The Service Mesh’s control plane takes care of generating, distributing, and rotating these certificates. With a modern proxy like Envoy, certificates can be updated on-the-fly by an API call, meaning no downtime to rotate them.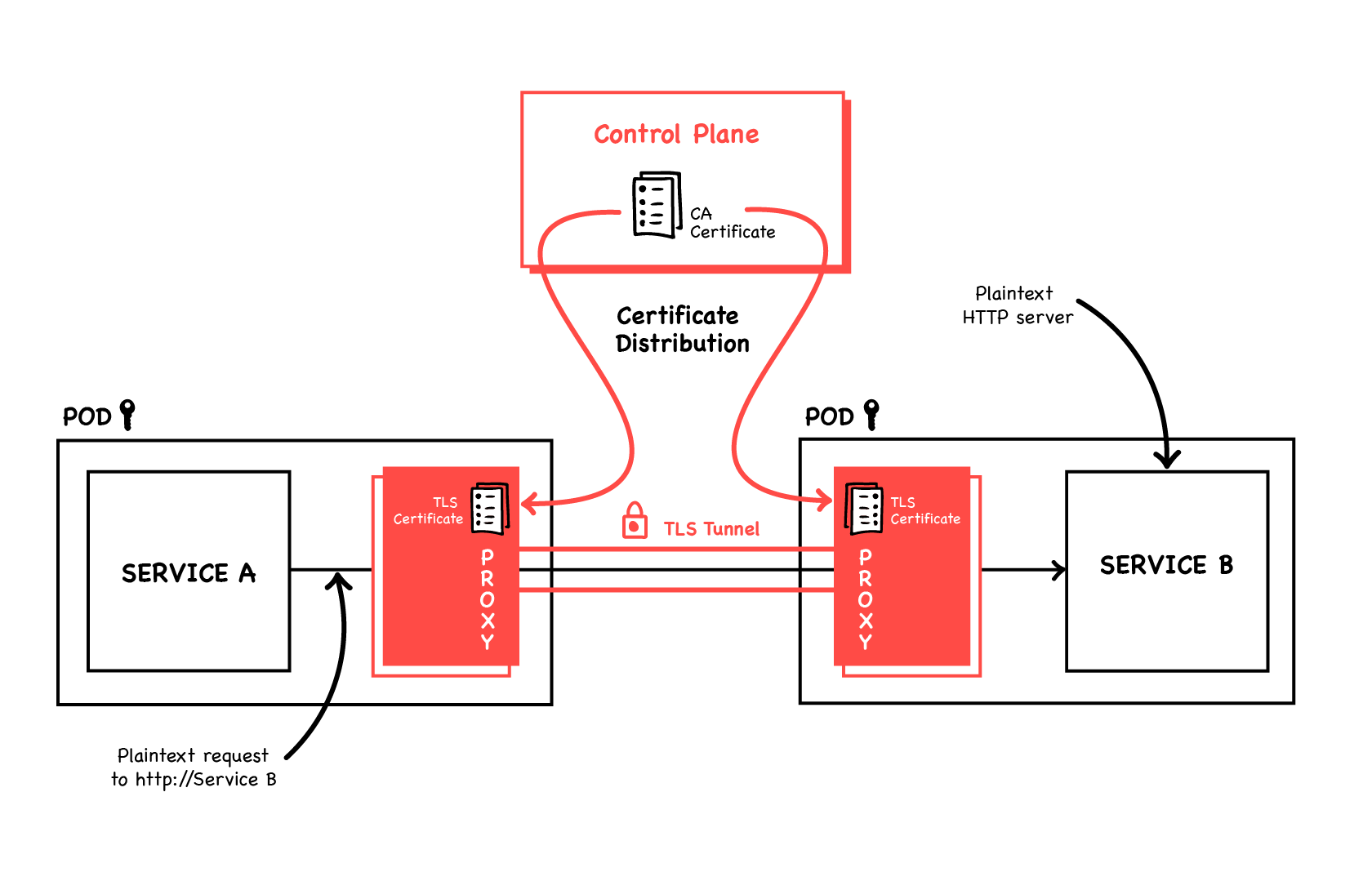 We can also delegate access control to the Service Mesh. Say you’re running a webstore: the orders microservice is critical—it can be used to create and manipulate orders, sending your stock to anywhere in the world. You also have a small service that looks up users’ profile pictures to display them when they’re logged in. This profilepicture service has no business talking to the orders service; any attempt it makes to do so is either a bug, or worse a security breach. To prevent this ever happening we can firewall one from the other. Rather than using Kubernetes
We can also delegate access control to the Service Mesh. Say you’re running a webstore: the orders microservice is critical—it can be used to create and manipulate orders, sending your stock to anywhere in the world. You also have a small service that looks up users’ profile pictures to display them when they’re logged in. This profilepicture service has no business talking to the orders service; any attempt it makes to do so is either a bug, or worse a security breach. To prevent this ever happening we can firewall one from the other. Rather than using Kubernetes NetworkPolicy, which applies at a blunt Pod-to-Pod level, we can let profilepicture GET from orders’ count endpoint, for example to show a gold ring round the picture of anyone who’s ordered 10 or more things. Simultaneously we can prevent reading any other path, or POST access to any of them.
It’s not just the identity of the calling workload which determines if access should be granted; we want to look at which end user is trying to make the request. When our users are logged in to our mobile app, every API request sent has a JWT in the HTTP Authorization header. If our services forward this field then every service in our cluster can know which end user the request is on behalf of. JWTs need validating (they’re signed by a private key) and we can defer this to the Service Mesh—configure it with the corresponding public key—and requests with invalid JWTs will simply never arrive at the services at all.
WIth all JWTs guaranteed to be valid, their claims can be used for access control. In the same way that profilepicture couldn’t access most of orders’ API, we can prevent humans who are not in the gold_member group from making requests to orders’ /discounts path. This is another example of our apps not having to contain boilerplate code to perform common operations like JWT validation and access control, especially the notoriously tricky subtlety of security code.
Other use cases
The above Service Mesh features often fulfil our use cases on their own, directly addressing requirements for observability, traffic control, resiliency, and security. In addition, many of the Service Mesh products have some extra features that aren’t so easily categorised, and several features can be combined to do even more useful things. Some examples of this are:
- Protocol canonicalisation: have a gRPC service that needs to be called by a web app that can only talk “REST” (JSON/HTTP)? The Service Mesh can translate one encoding to the other transparently.
- Topology-aware routing: want to save cloud costs and latency by sending requests to the Pod in a Deployment that’s physically closest to the originator? The Service Mesh’s control plane knows which Node everything ended up scheduled on, and where those Nodes are in relation to each other (by querying Kubernetes’ API). Using these data it can configure all the sidecars to prefer their local instance of any service they try to call, falling back to one that’s further away in case of an error.
- Traffic mirroring: unsure what a new version of a service will do in the face of unpredictable real-world user traffic? Configure the Service Mesh to send a copy of every request headed to the current version to this new version too. Responses from the new version will be discarded in case they’re still buggy, but you can observe the new code’s logs, error rate and performance metrics.
There are many more examples besides these, with innovation happening all the time. A big area worth mentioning quickly, though outside the scope of this article, is migration of legacy workloads. Service Mesh sidecars are easy to inject into Kubernetes Pods—both hooking the Pods’ startup to run the proxy as well, and having it intercept all traffic. The same can be done for workloads that are still running on raw VMs (e.g. under systemd or raw Docker). It’s more tricky to set up, but when you have, the VM-based workloads “join the mesh”, giving all the advantages I’ve talked about in this article. Although it might seem backwards, a good approach to legacy workload migration is to join them to the mesh first and then use the observability and routing control that affords to aid migration into Kubernetes.
One last area of innovation is solutions being built on top of Service Meshes—yep, they’re not even the cutting-edge top-of-the-stack any more! For example, combining the ability to split arbitrary percentages of traffic between different service versions, and the detailed metrics on error rates and performance produced for each version, a Service Mesh is ideal for enabling a canary roll-out. Send 1% of traffic to vNext, check the metrics. All good? Send 2%, check the metrics again, repeat. Metrics looking bad now there’s more load? Immediately direct 100% of traffic back to the stable version. This is perfectly possible to do by hand, but very tedious. By using the control plane’s unified, high-level API (essentially feeding it the same YAML documents we saw above), this process can be automated. Projects such as Weaveworks Flagger and ArgoCD do this. These APIs are also used by supra-mesh “management planes” like Meshery. Implementations By now I hope you’re sold on the Service Mesh dream! So where do you go to get one? There are several implementations to choose between. I won’t try to make a recommendation here, but I’ll give a quick rundown of the major players.
Recall the separation between the data plane, the proxies that intercept and handle the traffic, and the control plane—the service that takes high-level config from us and renders all the complicated individual config that each proxy needs. High-performance, secure HTTP proxies are not easy to write, so most projects don’t reinvent that wheel. A lot of the Service Meshes use the Envoy proxy I’ve talked about, which is a separate open source project, for their data planes. Differentiation comes in the control plane.
Istio is the best-known and most popular Service Mesh. Its control plane is written in Go and it uses Envoy as its proxy. Similar to Kubernetes it’s maybe more of a platform than a polished product, so the learning curve can be steep and installation can be tricky, but it has got a lot better in recent releases. Istio is an open-source project and has the biggest support backing with both community and third-party commercial offerings. There are even Istio “distributions” now from vendors such as Tetrate and Solo.
Linkerd is another long-established Service Mesh. Note that there was originally a Linkerd 1, which was architecturally very different and had some serious shortcomings. The current Linkerd 2 (neé Conduit) is a solid modern product with a Go control plane and a bespoke Rust proxy. It’s open-source with commercial support offered by the vendor Buoyant.
There are many more Service Meshes besides, please don’t read anything into me not mentioning a particular one here. A great landscape guide and comparison is produced by Layer 5.
I will mention two more specific Service Meshes though. Cilium from Isovalent is a Kubernetes cluster network (a CNI plugin), equivalent to things like Calico and Flannel. They have a Service Mesh offering in beta which is vertically integrated with their cluster network. Both the cluster network and Service Mesh layers make heavy use of eBPF, which performs a lot of the Layer 7 operations I’ve talked about. Pods don’t need sidecars, as eBPF in the kernel takes on most of the work previously done by the proxy, which improves performance and reduces resource usage. Cilium currently runs one Envoy per Node, to which traffic is sent if it needs treatment eBPF can’t provide, as it’s not infinitely flexible.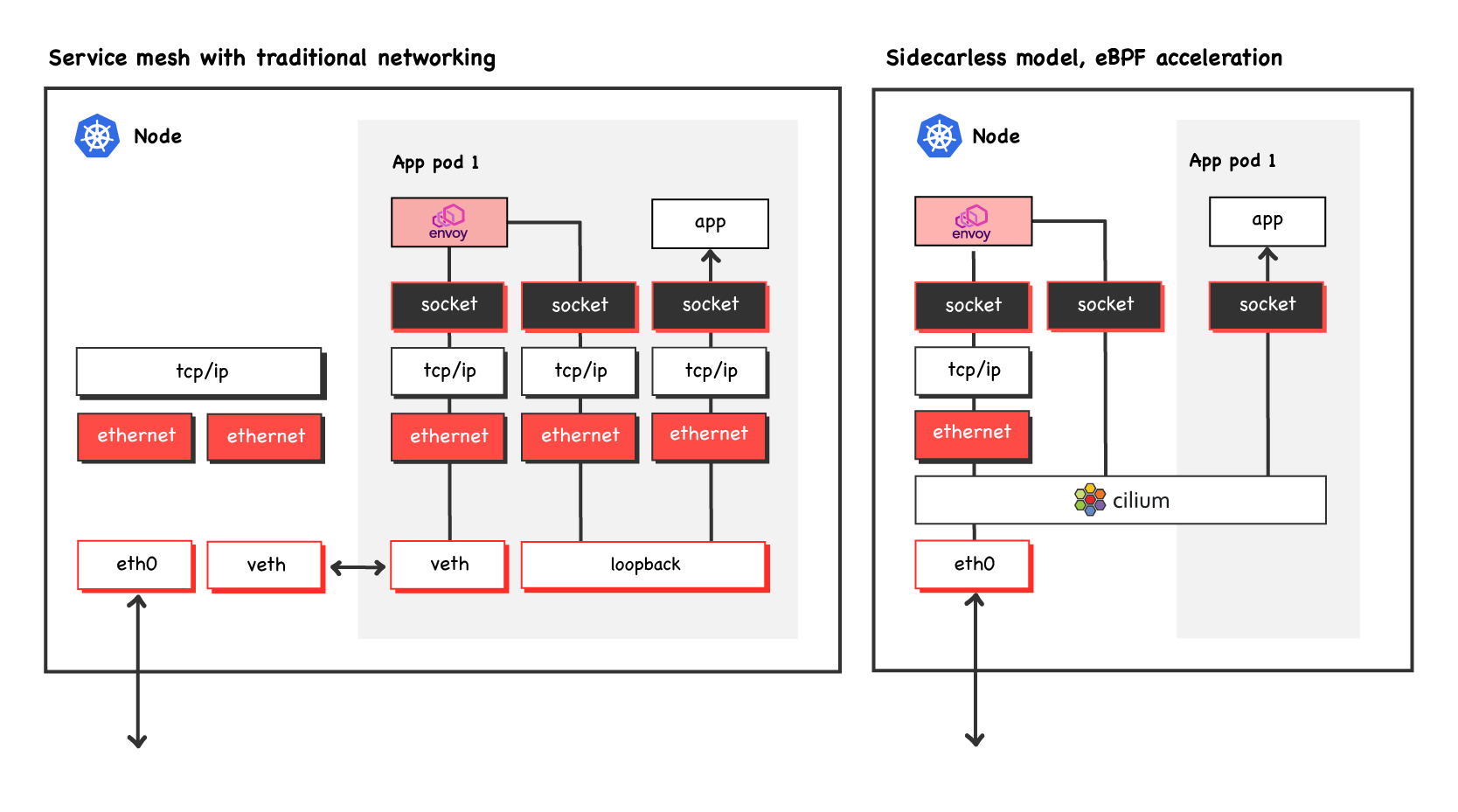 Original image from https://cilium.io/blog/2021/12/01/cilium-service-mesh-beta - used with permission.
Original image from https://cilium.io/blog/2021/12/01/cilium-service-mesh-beta - used with permission.
AWS AppMesh is a proprietary product using the Envoy proxy. It’s tightly integrated with other AWS services like CloudWatch, and is able to provide sidecars to ECS/Fargate workloads as well as Kubernetes Pods, although currently not lambdas.
This landscape might appear big and disparate but there are some common themes. As I mentioned, a lot of these Service Meshes use Envoy as their proxy. Envoy is extensible meaning it can be loaded with new load balancing strategies or taught to parse new Layer 7 protocols. Extensions are provided as Web Assembly binaries so they can be written in a number of languages which compile to WASM. These extensions are thus reusable across many meshes (although the ease of loading them into the proxies varies between meshes), and ongoing core Envoy development benefits all. There’s also a standard for Service Mesh APIs, the Service Mesh Interface (SMI), which is vendor agnostic allowing both products like Flagger to work with any mesh which implements it without the need for additional code, and individual developers to use Service Mesh technology without lock-in to a specific implementation. Several of the big meshes implement SMI, but notably Istio doesn’t.
Conclusions
Service Meshes add powerful features to an often unconsidered part of Kubernetes clusters: the network. Layer 7 observability, sophisticated traffic routing, and solid security can all be factored out of application microservices and instead configured as network functions. Or, perhaps more realistically, a Service Mesh can easily add them to apps that never had them in the first place. New innovations, like WASM Envoy plugins and sidecar-less eBPF meshes, are moving the space further forwards all the time. However there are already several well-established Service Mesh projects which offer an easy route to all these benefits today. Deploying a Service Mesh unlocks even more value in the projects now built on top of them, like the Flagger progressive delivery operator. They can be incrementally adopted (Kubernetes labels are used to opt in one Namespace or even just one workload) meaning you can start safely experimenting today.