

Back in 2017, I wrote on my personal blog about Things I Learned Managing Site Reliability for Some of the World’s Busiest Gambling Sites. A lot of it focussed on runbooks, or checklists, or whatever you want to call them (we called them Incident Models, after ITIL).
It got a lot of hits (mostly from HackerNews), and privately quite a few people reached out to me to ask for advice on embedding similar practices in their own organisations. It even got name-checked in a Google SRE book.
Since then, I’ve learned a few more things about trying to get operational teams to follow best practice by writing and maintaining runbooks. This blog post is partly an update of that.
All these experiences have led me to help initiate a public Runbooks project at Container Solutions to try and collect and publish similar efforts and reduce wasted effort across the industry.
tl;dr
We’ve set up a public Runbooks project to expose our private runbooks to the world. (If you're viewing this on a mobile device, here's a download of this graphic.)
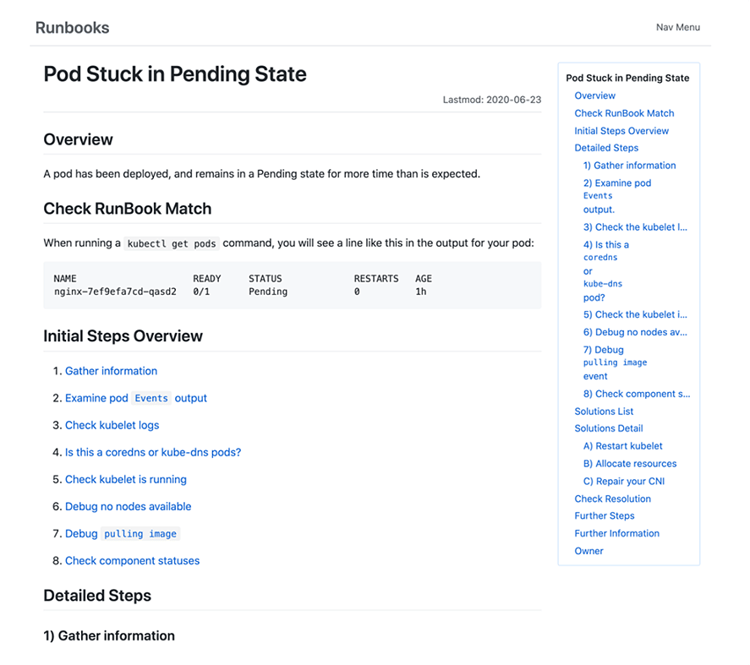
We’re looking for contributions. Do you have any runbooks lying around that could benefit from some crowdsourcing? The GitHub repo is here if you want to get involved, or contact me on Twitter.
Back to the lessons learned.
The logic is inarguable, the practice is hard.
I already wrote about this in the previous post, but every subsequent attempt I made to get a practice of writing runbooks going was hard. No one ever argues with the logic of efficiency and saved time, but when it comes to putting the barn up, pretty much everyone is too busy with something else to help.
In summary, you can’t tell people anything. You have to show them, get them to experience it, or incentivise them to work on it.

Some combination of these four things is required:
- Line-management/influence/control to encourage/force the right behaviours
- A critical mass of material to demonstrate value
- Resources allocated to sustain the effort
- A process for maintaining the material and ensuring it remains relevant
With a prevailing wind, you can get away with less in one area, but these are the critical factors that seem to need to be in place to actually get results.
A powerful external force is often needed.
Looking at the history of these kind of efforts, it seems that people need to be forced–against their own natures–into following these best practices that invest current effort for future operational benefit.
Examples from The Checklist Manifesto included:
- Boeing and checklists (‘Planes are falling from the sky–no matter how good the pilots’!)
- Construction and standard project plans (‘Falling buildings are unacceptable. We need a set of build patterns to follow and standards to enforce’.)
- Medicine and ‘pre-flight checklists’ (‘We’re getting sued every time a surgeon makes a mistake. How can we reduce these’?)
In the case of my previous post, it was frustration for me at being on-call that led me to spend months writing up runbooks. The main motivation that kept me going was that it would be (as a minimal positive outcome) for my own benefit. This intrinsic motivation got the ball rolling, and the effort was then sustained and developed by both the development of more structured process-oriented management and others seeing that it was useful to them.
There’s a commonly seen pattern here:
- you need some kind of spontaneous, intrinsic motivation to get something going and snowball, and then
- a bureaucratic machine behind it to sustain it
If you crack how to do that reliably, then you’re going to be pretty good at building businesses.
A runbook doesn’t always help.
That wasn’t the only experience I had trying to spread what I thought was good practice. In other contexts, I learned, the application of these methods was unhelpful.
In my next job, I worked on a new, centralised, fast-changing system in a large organisation, and tried to write helpful docs to avoid solving the same issues over and over. Aside from the authority and ‘critical mass’ problems outlined above, I hit a further one: the system was changing too fast for the learnings to be that useful. Bugs were being fixed quickly (putting my docs out of date fast) and new functionality was being added, leading to substantial wasted effort and reduced benefit.
Discussing this with a friend, I was pointed at an existing framework called Cynefin, which had already classified these differences of context, and the appropriate response to them. Through that lens, my mistake had been to try and impose what might be best practice in a ‘Complicated’/’Clear’ context to a context that was ‘Chaotic’/’Complex’.
‘Chaotic’ situations are too novel or under-explored to be susceptible to standard processes. Fast action and equally fast evaluation of system response is required to build up practical experience and prepare the way for later stabilisation.
‘Why Don’t You Just Automate It’?
I get this a lot. It’s an argument that gets my goat, for several reasons.
Runbooks are a useful first step to an automated solution.
If a runbook is mature and covers its ground well, it serves as an almost perfect design document for any subsequent automation solution. So it’s in itself a useful precursor to automation for any non-trivial problem.
Automation is difficult and expensive.
It is never free. It requires maintenance. There are always corner cases that you may not have considered. It’s much easier to write: ‘go upstairs’ than build a robot that climbs stairs.
Automation tends to be context-specific.
A runbook pairs a human mind with a set of clear instructions. Unlike a computer program, which requires a very specific context to run in successfully, the text/human pairing provides a flexibility that allows you to cover a great number of situations without extra cost. While a shell script solution will need to reliably cater to many feasible contexts to be useful, a runbook can be flexibly applied to many situations. More specifically, not every organisation can use your Ansible recipe.
Automation is not always practicable.
In many situations, changing or releasing software to automate a solution is outside your control or influence.
A Public Runbooks Project
All my thoughts on this subject so far have been predicated on writing proprietary runbooks that are consumed and maintained within an organisation.
What I never considered was gaining the critical mass needed by open- sourcing runbooks, and asking others to donate theirs, so we can all benefit from each others’ experiences.
So we at Container Solutions have decided to open source the runbooks we have built up that are generally applicable to the community. They are growing all the time, and we will continue to add to them.
Call for Runbooks
We can’t do this alone, so we are asking for your help!
- If you have any runbooks that you can donate to the cause lying around in your wikis, please send them in.
- If you want to write a new runbook, let us know.
- If you want to request a runbook on a particular subject, suggest it.
However you want to help, you can either raise a PR or an issue, or contact me directly.
A version of this blog post appeared on Ian's blog, zwischenzugs. Photo by Jamie Templeton on Unsplash
