
This is the start of a three-part blog series on Site Reliability Engineering. To learn more, request a free copy of the e-book on SRE from which this was excerpted.
Almost all enterprises nowadays look at the successful operation models of companies like Amazon, Apple, Netflix, and Spotify with envy. Many rush to start Cloud Native transformations, only to find out that a successful and sustainable transformation can’t be achieved by just creating some awesome Powerpoint slides.
They install cutting-edge software like Kubernetes. But they find they are still not able to deploy new features quickly and easily.
All enterprises have a history of brilliant innovations, a market position, and a mission that kept them going over the course of their existence. But especially in uncertain times like these, they will notice the things they have lost along the way—and often, it’s the ability to keep their core business going while also innovating to respond to rapid changes in customer demand or needs.
Change is inevitable. It requires that your organisation’s codebase is sustainable and you are able to change all the things you ought to change, safely, and can do so for the lifespan of your product. That’s where SRE can help.
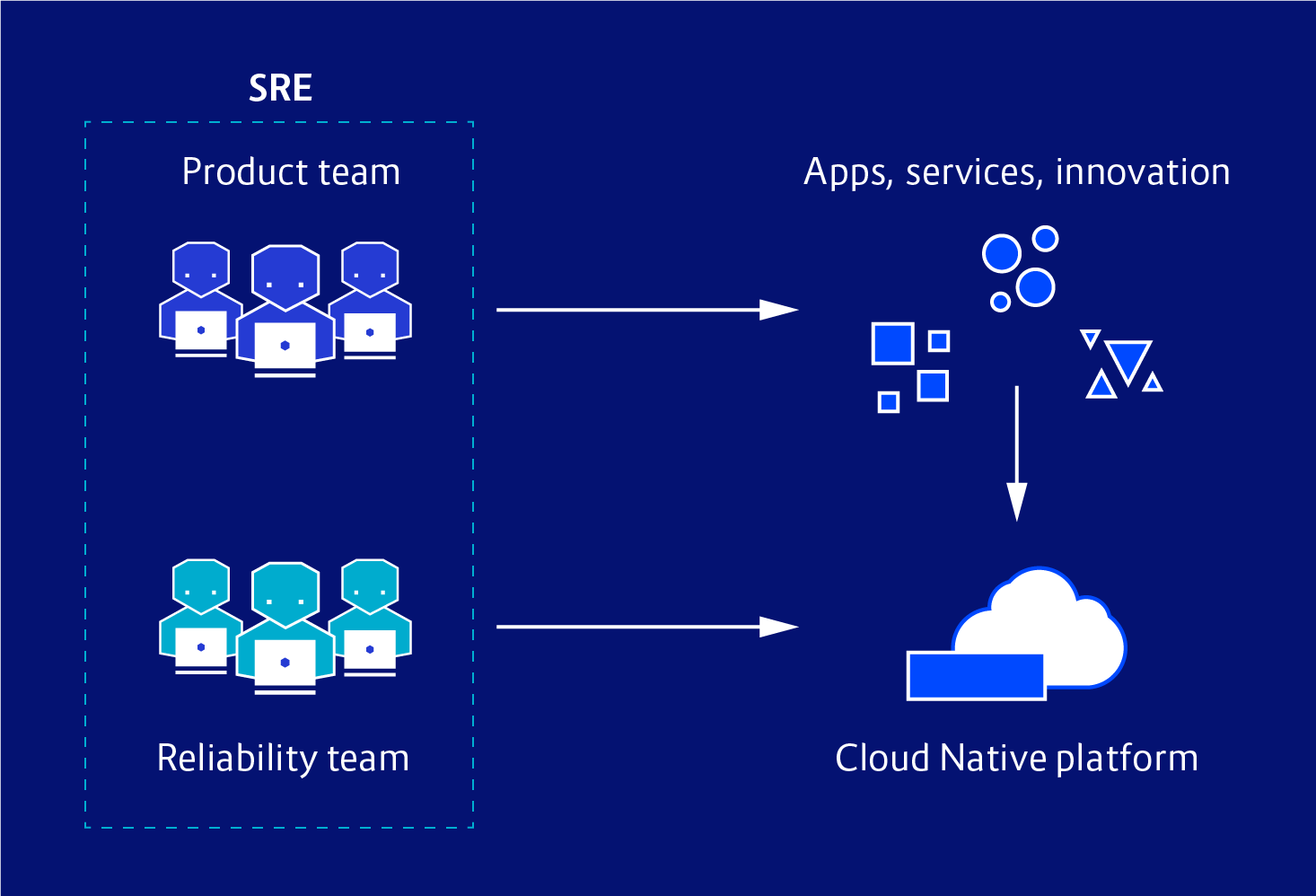
SRE: The Two-Teams Solution
Site Reliability Engineering (SRE) is a term coined by Google to explain how it runs its systems. It was Google’s answer to today's challenges with ensuring application performance and reliability at unprecedented scale.
In SRE, responsibility for an organisation’s platform is split between two teams:
- A product team, which focuses on delivery of the business value, application, or service (including innovation).
- A reliability team, which focuses on both maintaining and improving the platform itself.
In order to understand why an organisation might need SRE, we need to understand the difference between programming and software engineering. Programming is the development of software. Software engineering plays an integral part in programming, but is also about modifications (change) and maintenance of software.
Whether or not your organisation needs SRE depends on one factor: change. If your product or codebase’s lifespan is so short that it will never need to be altered, then SRE isn’t a good fit. But if you build a platform that is meant to last more than a couple of months, change will be required. In other words, you would benefit from SRE.
Supporting Current Needs
While most IT teams usually focus on improving the development process, many teams don’t focus enough on their systems in production. And yet, between 40-90% of the total costs of a platform, according to estimates reported by Google, are incurred after going live.
As the platforms and applications become more complex and are constantly growing, the DevOps teams—the cross-functional teams who are responsible for their applications’ entire lifecycle— need to spend more time supporting current services. This becomes even more of a problem if the teams provide 24/7 coverage in the typical DevOps ‘you built it, you run it’ manner.
A typical DevOps team tends to be small, usually about five engineers, as the scope of such teams spans ideally only one service or functionality. By having five engineers willing and capable of doing 24/7 on-call—with one primary and one backup—everyone is on duty 146 days a year, or nearly every second week. This is a recipe for burnout and high turnover.
In order to reallocate IT’s time towards delivering value to customers, without impeding the velocity of product delivery and improvement, more companies are forming SRE teams. This means dedicating developers to the continuous improvement of the resilience of their production systems.
At Container Solutions, we’ve taken the SRE concept and taken it a step further. In our version—Customer Reliability Engineering, or CRE—the product team is assembled from our customers’ engineering staff, but the reliability team is comprised of CS experts.
This gives customers the benefit of our engineers’ experience while freeing up the in-house product team’s time for innovation and responding to new business demands.
In part 2 of this three-part blog series on Site Reliability Engineering, we will discuss the relationship between SRE and Cloud Native.
To learn more, download the e-book SRE: The Cloud Native Approach to Operations.
You can find all of our information about SRE and CRE in one place. Click here.

| ← Previous | Next → |
 |
 |