
This is part 2 of a three-part blog series on Site Reliability Engineering. You can read Part 1 here. Part 3 is here. To learn more, request a free copy of the e-book on SRE from which this was excerpted.
Traditional IT Operations teams still rely, to a large extent, on manual activities and on processes that slow down the delivery of value. By doing this, these teams can’t keep up with the rapidly growing demand and complexity of modern software applications— and the demand placed upon them from inside and outside their companies.
Development and Operations teams have traditionally adopted a ‘silo mentality’ that is optimised for efficient use of resources and technology specialisation. Silos require formalised, and time-consuming, handover between silos. Often these siloed teams even have conflicting goals. The Dev team needs to deliver faster value to customers by developing and deploying new features and products, while the Ops team needs to ensure production stability by ensuring that applications don’t suffer from performance degradation or outages.
By adopting Site Reliability Engineering, or SRE, you can overcome the traditional conflicts between Development and Operations. SRE, named and formalised by Google, applies software engineering practises to infrastructure and operations—with the main goals of creating scalable and highly reliable Cloud Native platforms without manual intervention.
This does sound at first like the DevOps movement, but there are differences. (More on that in my next blog post, 'Isn’t SRE Just DevOps?')
Too many companies see going to Cloud Native simply as setting up Kubernetes. Blinders on, they see only the exciting new tech that everyone is buzzing about. But without understanding their own architecture, their own maintenance and delivery processes—or, most crucially, their own internal culture and its pivotal role in the transformation process—they will end up with a complex system they can hardly maintain. This will lead to the opposite of being Cloud Native.
Achieving Common Standards
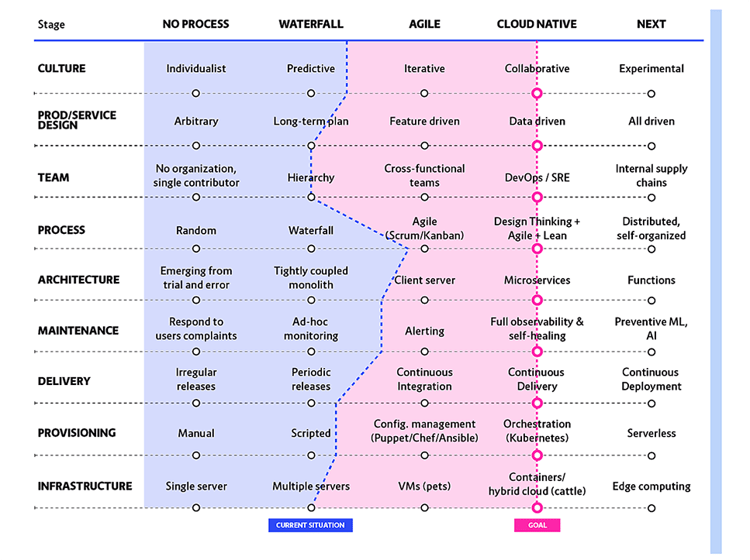
In the graphic below, of Container Solutions’ Maturity Matrix, which maps an organisation’s status in nine categories, you see a holistic view on what it means to become a Cloud Native organisation. SRE is part of that. SRE focuses on Availability, Performance, Observability, Incident Response, and Continuous Improvements—all of which are attributes of Cloud Native.
Cloud Native uses microservices as application architecture patterns. Applications are best built by following the 12 Factor Apps principles and by extending these 12 Factors with composability, which means that applications are composed of independent services; resilience, which means failures of individual services have only localised impact; and observability, which exposes metrics and interactions of services as data.
The design principles of Cloud Native applications are:
- Design for Performance (responsiveness, concurrency, efficiency)
- Design for Automation (automation of infrastructure and development tasks)
- Design for Resiliency (fault-tolerance, self-healing)
- Design for Elasticity (automatic scaling)
- Design for Delivery (minimise cycle time, automate deployments)
- Design for Diagnosability (cluster-wide logs, traces, and metrics)
By applying SRE principles, your architecture will gravitate towards common standards and conventions, even if not centrally dictated. These standards are usually the extended 12 Factors, to build resilient applications.
A Focus on Performance
The better the collaboration between the development team and the SRE team, the more reliably available your platform becomes.
The SRE team will focus on improving service performance. Performance errors usually don’t have an impact on overall availability, but those errors do have an impact on customers. If these issues happen often, it doesn’t matter if your availability is 99.999% if it still means your customers will get frustrated and stop using the service.
That’s why SRE teams should not only help fix bugs and ensure availability, but should also help proactively identify performance issues across the system.
In order for SREs to fulfill these demands, observability is crucial. Observability is a key element of any SRE team and a great deal of time goes into implementing observability solutions. Because different services have different ways of measuring performance and uptime, deciding what to monitor and how to do so effectively is one of the hardest parts of being a site reliability engineer.
But generally, SREs should try to standardise on a few metrics to simplify future integrations. Google’s metrics, ‘The Four Golden Signals’—latency, traffic, errors, and saturation— can be applied to almost all services.
When going on a Cloud Native journey and starting to adopt the SRE operational model, these teams will spend more time working in production environments. By doing so, the organisation will see constantly improving and more resilient architecture—with, for example, additional failover options and faster rollback capabilities. Through those continuous improvements, your organisation can set higher expectations for your customers and stakeholders, leading to impressive SLOs, SLAs, and SLIs that drive greater business value.
While the development teams are in charge of maintaining a consistent release pipeline, SRE teams are tasked with maintaining the overall availability of those services once they’re in production. And because Service Level Objectives (SLOs) are in place and being realistically challenged via error budgets, you will get an effective risk-management system.
Your platform will be more robust and you will be able to change all the things you ought to change, safely—and can do so all the time, with immediate feedback on the availability and performance of each change.
Learn more about SRE by requesting a free copy of our e-book, from which this blog post was excerpted. Just click below. And go here learn about Container Solutions' version of SRE, our Customer Reliability Engineering service.
You can find all of our information about SRE and CRE in one place. Click here.
