When thinking about emerging software trends you might think about things like WebAssembly or GraphQL. You might not immediately think about sustainability but, in common with many other industries, this is a subject that increasingly comes up. There’s a climate problem. Our planet is around 1˚C warmer than it was before the industrial revolution, and it’s continuing to heat up. By 2052 (best case) or 2030 (worst case) it will be 1.5˚ warmer.
It’s taken me a while to realise that although it sounds innocuous, a change of even 1.5˚ is serious. It’s easy to think “I’d barely even notice it if I went outside and it was 2˚ warmer,” or even “if it was a few degrees warmer, that would be nice. I’d wear flip flops, and have an excuse to eat more ice cream!” (In Finland, I was offered ice cream in February, but I assume that’s a regional preference, and the rest of us save ice cream for hot summer days.)

Sadly, a 2˚ rise is the opposite of nice. A warmer world will be a more dangerous place. Hostile environments and diminishing natural resources create political instability and human suffering. We’re already seeing the effect of climate change right now: extinctions, hurricanes, destructive fires, and flooding.
WTF. This is bad!
Yes. Yes, it is.
OK, but WTF does it have to do with me?
 Climate change is a complex problem. It’s like technical debt, except in our infrastructure and policies. Significant refactoring will be needed in the long term, but what we all need to be doing now is driving down our carbon emissions.
Climate change is a complex problem. It’s like technical debt, except in our infrastructure and policies. Significant refactoring will be needed in the long term, but what we all need to be doing now is driving down our carbon emissions.
If you think of industries with a bad carbon footprint, aviation might come to mind. Planes are responsible for a whopping 2.5% of global carbon emissions. Unfortunately, data centres - that’s our industry - consume around 1% or 2% of the world’s energy. If you consider the broader IT industry, our energy usage is higher still. We’re almost as polluting as planes, but with more build pipelines and fewer wings.

You may have noticed I mixed carbon apples and energy oranges a bit in my comparison. Planes use fossil fuels for energy, and burning fossil fuels always emits carbon. Data centre energy can be carbon-free. Hydroelectricity, wind, or solar power don’t generate carbon (once the infrastructure to generate the electricity has been built). We’re also seeing smart data centre architectures which recycle excess heat into heating for the local area. Nonetheless, many data centres still run on coal, or a mix of fuels. Virginia, the data centre capital of the world, is heavily reliant on fossil fuels.
To make matters worse, data centre energy use is going up, fast. It’s expected to increase between 8% and 20% by 2030. Demand is going up in general, but a lot of the rise is driven by machine learning. AI uses a lot of energy. Models are getting smarter, but they do that by getting bigger and burning more electricity. The energy used by deep learning has been doubling every few months recently.
As techies, what we do at work has a big climate impact. We need to cut back, but where? We need to trade off how useful something is against how much energy it uses. One of the reasons we focus on aviation as a climate culprit, rather than cement (8%) or agriculture (20%), is that feeding and housing people seems inherently useful, whereas jetting around for sightseeing and meetings just seems… frivolous. Similarly, NFTs and bitcoin make people grumpy because they use huge amounts of energy and don’t seem to have much purpose except enriching bitcoin miners and speculators. (How much energy is “huge amounts”? Bitcoin mining currently uses more energy than Argentina, and some estimates put it at half of all data centre energy usage.)
At some point, we will need to make some tough choices, but we can start by reducing accidental waste. Waste - by definition - has no value. There’s no downside to getting rid of waste, and it can save money as well as carbon. Trimming out unneeded processing can even speed up applications and reduce latency, making users happier.
But where is waste coming from? How do we find it?
The sad case of the single occupancy dwelling
Let’s talk about where we run our workloads. To understand provisioning efficiency, we need to understand utilisation and elasticity. Utilisation is how much of a system’s computational capacity is being used by workloads. The higher the utilisation, the better. Interestingly, mainframes (remember them?) average about 95% utilisation, so they’re an outstandingly efficient way to run a workload. Mainframes use about half the power of x86, while also going faster. We don’t all have to switch to mainframes, but we should try not to use our x86s in ways where most of the capacity is sitting idle.
The next concept is elasticity. Elasticity is how easily we can scale a workload up or down. Elasticity is what allows us to get high utilisation, because if we can shrink and grow a workload, we can adjust it so it’s only using the minimum required resources.
In the early days of the cloud, businesses rushed to adopt cloud for the cost savings. Instead of running every application on dedicated hardware, machines could be pooled, and workloads could be scaled up and down as needed. The elasticity of the cloud gave high hardware utilisation and lower costs.
That’s still mostly true, but it’s not guaranteed. Think, for example, about Kubernetes. We’ve all seen generously-provisioned clusters which are only running one small workload. The rest of the hardware capacity is unused. What’s going on? Individual applications have great elasticity, and can be scaled up and down. The cluster, not so much. Scaling a cluster up or down is possible, but it's hard work, because cluster nodes are pretty coupled to the underlying machines.
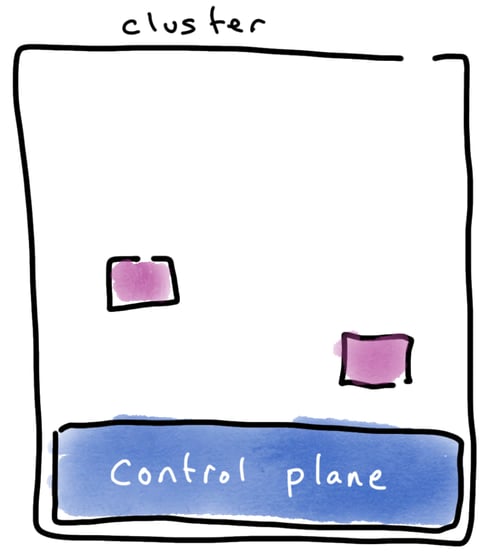 An underutilised cluster.
An underutilised cluster.
What’s more, every cluster has overhead, known as the control plane. Even if you get to be a whizz at shrinking clusters, making a cluster too small turns it inefficient: it’s almost all overhead and only a little bit application.
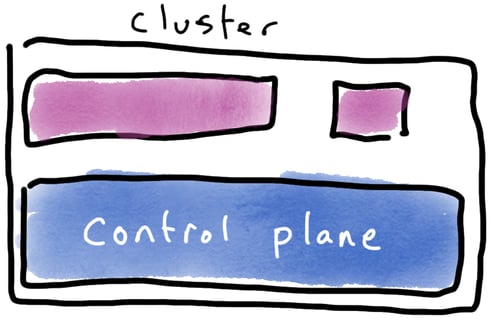 A cluster with good, high, utilisation—but the control plane consumes the majority of the computational resources.
A cluster with good, high, utilisation—but the control plane consumes the majority of the computational resources.
Ideally, instead of shrinking our clusters, we should be pooling resources by sharing our clusters. This is technologically simple, but there’s a barrier. Conway's Law applies to clusters as well as code! Conway's Law says that your architecture replicates your organisational structure. In my experience your cluster topology also ends up mirroring your org chart.
There are a few reasons this happens. One is just the mechanics of communicating across team boundaries about spare capacity and arranging access and IDs. Computers cost money, so teams are reluctant to share unless there’s some chargeback mechanism in place. Measuring cross-team usage takes effort and coordinating the internal transfer of funds can involve ridiculously hard bureaucracy.
Isolation is also a concern. What if we let in a noisy neighbour and they hog all the compute power? What if an unwisely-named resource causes a scope collision? What if they run a corrupt container? Security is a big concern, because a vulnerability in one container compromises all its neighbours, even in other namespaces. Kubernetes namespaces give some isolation, but not nearly enough to overcome the Conway barrier.
Nonetheless, we can do better at multi-tenancy. We should monitor our cluster utilisation, rationalise clusters which aren’t doing enough, and default to sharing, at least for non-prod workloads.
Beware zombies
Let’s imagine we become utilisation experts and pack lots of workloads into each cluster, so that all our clusters are humming away at 90% utilisation. Are we climate heroes?
It all depends what the workloads on those clusters are. If it’s bitcoin mining then, clearly, we are not climate heroes, no matter how great our utilisation is. On the other hand, even though bitcoin is problematic, at least someone, somewhere, benefits from it. Some workloads have no purpose at all, not even profit. These are called zombie workloads and they’re a horrible problem in our industry. They’re applications that were useful at some point, but that purpose ended long ago, and no one decommissioned the application.  Zombies are bad.
Zombies are bad.
This happens all the time. When I was learning Kubernetes, I created a cluster, but I had too much work in progress. I forgot my $1000-a-month cluster for two months. When I re-discovered it it was obvious I should quickly and guiltily shut it down, but sometimes these decisions are trickier. We all have the IKEA cognitive bias, which says that if we make something, we become attached to it. We’re reluctant to shut down servers we make because what if we need them later?
How bad is the zombie problem? One survey of 16,000 machines found that a quarter of them were doing no useful work. The metrics are probably even worse for many clouds. The cloud makes it delightfully easy to provision hardware, but it doesn't, out of the box, give any support for remembering to de-provision that hardware. Cloud providers don’t have any particular incentive to help you reduce your consumption of their product.
WTF can we do?
Solving these problems is hard, but it can be done. For many organisations, the first line of defence against zombies is pleading emails. It's not a particularly effective way of managing zombies. Meetings are often the next resort, but they’re not very effective either.
Getting more sophisticated, many organisations try tags. Tags seem less reactive and more technological than meetings, but they still rely on manual processes. People have to remember to add a tag, they have to select a tag that will mean something to someone else, and someone has to regularly search and delete the things with tags that seem like maybe they're eligible for deletion.
Some teams try to shut the barn door before the zombie horse bolts. This seems sensible in theory, but in practice, it just ends up being an extra layer of innovation-stifling governance. To stop engineers accidentally creating zombie servers, these teams stop engineers creating any servers. Sadly, every zombie server started out life as a server with value. Adding friction at the creation stage doesn’t help smooth things at the deletion stage.
Automation to the rescue
There’s hope that FinOps may be able to help with zombie-detection. Officially, FinOps is a set of practices to help costs flow to the right part of an organisation, in real time. I prefer to think of it as the discipline of figuring out who forgot to turn their servers off in your organisation. Tracking costs creates an incentive to reduce waste, which reduces energy consumption.

GitOps also has zombie-killing potential. GitOps was designed to help with disaster recovery and auditability, not climate change, but energy reduction may be a secondary benefit. Infrastructure as code means infrastructure is disposable. Any server can be trivially spun up, so any server can be trivially spun down. GitOps resolves the IKEA cognitive bias because we get to keep our creation even if we shut down the server.
A while ago I started joking that spinning down clusters was going to be the new lights off. I predicted that in 2021 every evening when we left the office we’d turn out the lights, and then we'd turn off the clusters. It turns out I was incredibly wrong about the “leaving the office” part. On the bright side, I was more right than I knew about turning clusters off – it’s already being done! For example, one team reduced their cloud costs by 37% with some morning-and-evening automation. Reducing cost doesn’t guarantee reduced carbon, but it’s a useful heuristic.
Automation doesn’t have to be complex to make a difference. An IBM colleague was able to halve a bank’s CPU usage by implementing a trivial lease system. When someone provisioned a server, the new server would shut itself down after two weeks. If the engineer wanted to keep the server, they could renew the lease. Tuning our defaults to natural human tendencies (laziness and forgetfulness!) created big efficiencies, for both engineers and energy consumption.

As our industry starts to focus more on this problem, I’m hopeful we will see more automation baked into multicloud management systems. For example, traffic monitoring can flag servers which aren’t talking to the outside world.
The perils of micro-optimisation
Getting rid of waste is sometimes called a no regrets solution, or even a quadruple-win. Optimising our systems feels great, helps users, reduces cost, and saves the planet. However, we need to be careful of micro-optimisation theatre.
Micro-optimisations are optimisations that make you feel like you're making a difference, but they're not actually making a difference. They feel good, but they’re not helping users, or reducing cost, or saving the plant. Micro-optimisation is a well-known anti-pattern in the performance-tuning world, but it happens in many contexts.
Back when we travelled, I used to make a point of avoiding taxis. Unless an airport was completely inaccessible, I would always take public transit. This was hard! It took more time. It took more effort. As a woman traveling alone, it was more dangerous. Because I put so much effort into avoiding taxis, I felt like a climate hero. The problem is that the carbon saving from my non-taxi-ride to the airport was negligible compared to the carbon of the flight I took when I got to the airport.
Doesn’t every little help? Isn’t it better to take public transit than a taxi? Only if there is no opportunity cost. Resources are finite, so if you're spending time optimising something that has a fairly small benefit, that means you’ve lost the time to optimise something with a bigger benefit. The same trade-off also applies to our ‘sacrifice budget’; if we make a painful sacrifice to give up something we really like, we may feel ‘entitled’ to keep another thing. That’s a bad trade if the thing we gave up had a lower carbon footprint than the thing we kept.
As with performance optimisation, the key is to be data-driven. Measure, don't guess. When data isn’t available, push vendors for greater transparency about their carbon footprint. (In the same conversation, you can mention that you care a lot about waste and would like tooling to help you minimise zombie workloads and maximise utilisation, please.)
Problems are opportunities (honest!)
It’s easy to feel demoralised by the enormity of the climate challenge. It’s so big, and so complex, and so scary. Some of the changes that need to happen are fundamental societal ones, like how we measure progress and value. Governments need to change their regulations and incentives. But businesses and individuals also need to change, and this is within our power. Talk to your employer and its suppliers about their carbon footprint. Measure, and reduce.
The final change that needs to happen is that we need new technology. We have to create tools to measure and manage energy utilisation. We need to get better at running our infrastructure with multi-tenancy, on-demand spin-up, and effortless decommissioning. Doing all that will mean inventing new technologies and ways of working - and that’s kind of exciting.
Illustrations by Holly Cummins