
In this article I want to explain a few things about enterprises and their software, based on my experiences, and also describe what needs to be in place to make change come about. Have you ever found yourself saying things like:
- Why are enterprises so slow?
- How do they decide what to buy?
- Why is it so hard to deliver things in an enterprise?
I worked for a large ‘enterprise’ organisation for a few years trying to deliver infrastructure software change, and found myself having to explain these things to developers who worked there, salespeople, external open source engineers, software engineers at enterprise vendors, and many, many other people within the organisation. A few of those people suggested I write these explanations up so that they could pass it on to their fellow salespeople/engineers etc.
Background
Before the enterprise, I worked for a startup that grew from a single room to 700+ people over 15 years. ‘Enterprise’ was a word often thrown at us when rejecting our software, usually in the sentence “your software isn’t enterprise enough”. I had no idea what that meant, but I have a much better idea now. It didn’t help that the people saying it were usually pretty clueless about software engineering. Like many other software developers whose experience was in an unregulated startup environment, I had little respect for the concept of enterprise software. Seems we weren't alone.
When I finally got sick of the startup life I took a job at a huge organisation in financial services over 200 times as large. You don’t get much more ‘enterprise’ than that. But even within that context I was working in the ‘infrastructure team’, the part of the group that got beaten up for being (supposedly) slow to deliver, and then delivering less usable software than was desired. So it was like being in the enterprise, squared. Over the time that I worked there, I got a great insight into the constraints on delivery that cause client frustration, and – worse luck – I was responsible for helping to deliver change within it.
This is quite a long post, so I’ve broken it up into several parts to make it easier to digest:
1. Thought Experiment- What would happen if an enterprise acted like a startup?
- Some ways enterprises reduce risk
- The principle underlying these methods
- Consequences of the culture of risk reduction
- What can be done?
1) Thought experiment
Before we start, let’s imagine a counterfactual situation – imagine an enterprise acted like a startup. Showing how this doesn’t work (and therefore why it generally doesn’t happen) will help illustrate why some of the constraints that cause the slowdowns we see in large organisations exist.
First, let’s look at what a small team might do to change some software. We’ll make it a really simple example, and one you might well do routinely at home – upgrading a Linux distribution. In both cases, the relationship is:
- IT person
- Manager
Here’s how the conversation might go at a really small startup:
‘Lean’ OS upgrade – small company
- Shall we upgrade the OS?
- Yes, ok.
- Oh, I’ve hit a problem. One of the falanges has stopped working.
- OK, do some work to fix the transpondster.
- Might take me a few hours
- OK
- … OK, done. Can you test?
- Yup, looks good.
- Great.
‘Lean’ OS upgrade – enterprise
- Shall we upgrade the OS?
- Yes.
- OK, done.
- Um, you brought down the payments system.
- Whoops. I’ll roll back
- OK.
- Done. We’ll look into it.
- Hi. The regulator called. They saw something on the news about payments being down. They want to know what happened.
- Um, OK. I’ll write something up.
- Thanks.
- …
- They read your write-up and have asked for evidence of who decided what when. They want a timeline.
- I’ll check the emails.
- By the way, you’re going to be audited in a couple of months. We’ll have to cancel all projects until then
- But we’ve got so much technical debt!
- If we don’t get this right, they’ll shut us down and we’ll be fired.
- …
- OK, we have the results of the audit.
- Audit has uncovered 59 other problems you need to solve.
- OK…
- We’ll have to drop other projects, and maybe lose some people.
- Um, OK…
- Oh, and my boss is being hauled in front of the regulator to justify what happened. If it doesn’t go well he’s out of a job and his boss might go to prison if they think something fishy is going on.
Now that’s a bad release… That’s a worst-case scenario, but let’s unpick what these regulated enterprises do to mitigate both the risk and the consequences of the above scenario. Specifically:
- ‘Who owns this?’
- ‘How is this maintained?’
- ‘Who buys it?’
- ‘Who’s signed off the deployment?’
2) Reducing risk
‘Who owns this?’ / ‘One throat to choke’
This is a big one. One of the most commonly-asked questions when architecting a solution within an enterprise is: ‘Who is responsible for that component/service/system?‘ In our enterprise ‘Lean OS Upgrade’ scenario above one of the first questions that will be asked is: ‘Who owns the operating system?’ That group will be identifiable through some internal system that tracks ownership of tools and technologies. Those identified as responsible will be responsible for some or all of the lifecycle management for that technology. This might include:
- Upgrade management
- Support (directly or via a vendor)
- Security patching
- Deciding who can and can’t use it
- Overall policy on usage (expand/deprecate/continue usage)
This ownership results in ‘one throat to choke’ for audit functions. Much like the police will go after the drug dealer rather than the casual user, the audit functions of an enterprise will go after the formally responsible person or team rather than the (potentially thousands of) teams using an outdated version of a particular technology. There’s richer pickings there. From ownership comes responsibility. A lot of the political footwork in an enterprise revolves around trying to not own technologies. Who wants to be responsible for Java usage across a technology function of dozens of thousands of staff, any of whom might be doing crazy stuff? You first, mate.
Enterprises and vendors
This also explains enterprises’ love of vendor software over pure open source. If you’ve paid someone to maintain and support a technical stack, then they become responsible for that whole stack. That doesn’t solve all your problems (you’ll still need to integrate their software with your IT infrastructure, and things get fuzzier the closer you look at the resulting solution), but from a governance point of view you’ve successfully passed the buck.
| What is governance? IT governance is a term that covers all the processes and structures that ensures the IT is appropriately managed in a way that satisfies those that govern the organisation. Being ‘out of governance’ (i.e. not conforming to standards) is considered a dangerous place to be, because you may be forced to spend money to get back ‘in’ to governance. |
‘How is this maintained?’
Another aspect of managing software in an enterprise context is its maintenance. In our idealised startup above ‘Dev’ and ‘Ops’ were the same thing (ie, one person). Lo and behold you have DevOps! Unfortunately, the DevOps slogan ‘you built it, you run it’ doesn’t usually work in an Enterprise context for a few reasons. Partly it’s historical i.e. ‘it’s the way things have been done’ for decades, so there is a strong institutional bias towards not changing this. Jobs and heavily-invested-in processes depend on its persistence. But further bolstering this conservatism is the regulatory framework that governs how software is managed.
Regulations
Regulations are rules created by regulators, who in turn are groups of people with power ultimately derived from government or other controlling authorities. So, effectively, they have the force of law as far as your business is concerned. Regulators are not inclined to embrace fashionable new software deployment methods, and their paradigms are rooted in the experiences of software built in previous decades. What does this mean? If your software is regulated, then it’s likely that your engineering (dev) and operations (ops) teams will be separate groups of people specialising in those roles. The regulations demand a separation to ensure that changes are under some kind of control and oversight. Now, there is (arguably) a loophole here that some have exploited: regulations often talk about ‘separation of roles’ between engineering and operations, and don’t explicitly say that these roles need to be fulfilled by different people. But if you’re a really big enterprise, that might be technically correct but effectively irrelevant. Why? Because, to ‘simplify’ things, these large enterprises often create a set of rules that cover all the regulations that may ever apply to their business across all jurisdictions. And those rules are generally the strictest you can imagine. Added to that, those rules develop a life and culture of their own within the organisation—independent of the regulator—such that they can’t easily be brought into question.
Resistance is futile. Dev and Ops must be separate because that’s what we wrote down years ago.
So you can end up in a situation where you are forced to work in a way prescribed years ago by your internal regulations, which are in turn based on interpretations of regulations which were written years before that! And if you want to change that it will itself likely take years, requiring agreement from multiple parties who are unlikely to want to risk losing their job so you can deliver your app slightly faster.
Obviously, this separation slows things down as engineering must make the code more tolerant to mistakes and failure so that another team can pick it up and carry it through to production. Or you just throw it over the wall and hope for the best. Either way, parties become more resistant to change.
Change control
That’s not the only way in which the speed of change is reduced in an enterprise. In order to ensure that changes to systems can be attributed to responsible individuals, there is usually some kind of system that tracks and audits changes. One person will raise a ‘change record’, which will usually involve filling out an enormous form, and then this change must be ‘signed off’ by one or more other person to ensure that changes don’t happen without due oversight. In theory, the person signing off must carefully examine the change to ensure it is sensible and valid.
In reality, most of the time trust relationships build up between change raiser and change validator which can speed things up. If the change is large and significant, then it is more likely to be closely scrutinised. There might also exist ‘standard changes’ or ‘templated changes’, which codify more routine and lower-risk updates and are pre-authorised. These though must also be signed off before being deployed (usually at a higher level of responsibility, making it harder to achieve). While in theory the change can be signed off in minutes, in reality change requests can take months as obscure fields in forms are filled out wrongly (‘you put the wrong code in field 44B! Start again.’), sign-off deadlines expire, change freezes come and go, and so on. All this makes the effort of making changes far more onerous than it is elsewhere.
Security ‘sign-off’

If you’re working on something significant, such as a new product, or major release of a large-scale product, then it may become necessary to get what most people informally call ‘security sign-off’. Processes around this vary from place to place, but essentially, one or more security experts descend at some point on your project and audit it. I had imagined such reviews to be a very scientific process, but in reality it’s more like a mediaeval trial by ordeal. You get poked and prodded in various ways while questions are asked to determine weaknesses in your story. This might involve a penetration test, a look at your code and documentation, or an interview with the engineers. There will likely be references to various ‘security standards’ you may or may not have read, which in turn are enforced with differing degrees of severity.
The outcome of this is usually some kind of report and a set of risks that have been identified. These risks (depending on their severity – I’ve never heard of there being none) may need to be ‘signed off’ by someone senior so that responsibility lies with them if there is a breach. That process in itself is arduous (especially when the senior doesn’t fully understand the risk) and can be repeated on a regular basis until it is sufficiently ‘mitigated’ through further engineering effort or process controls. After which it’s then re-reviewed. None of this is quick.
Summary: corporate, not individual responsibility
If there’s a common thread to these factors in reducing risk, it is to shift responsibility and power from the individual to the corporate entity. If you’re a regulated, systemically-significant enterprise, then the last thing you or the public wants is for one person to wield too much power, either through knowledge of a system, or ability to alter that system in their own interests. The corollary of this is that it is very hard for one person to make change by themselves. And, as we all know, if a task is given to multiple people to achieve together, then things get complicated and change slows up pretty fast as everyone must keep each other informed as to what everyone else is doing.
Once this principle of corporate responsibility is understood, then many other processes start to make sense. An example of one of these is sourcing (aka procurement: the process of buying software or other IT services).
Example – sourcing
Working for such an enterprise, and before I stopped answering, I would get phoned up by salespeople all the time who seemed to imagine that I had a chequebook ready to sign for any technology I happened to like. The reality could not have been further from the truth. What many people don’t expect is that to prevent a situation where one person could get too much power, technical people often have no direct control over the negotiation (or ‘sourcing process’) at all. What often happens is something close to this:
- You go to senior person to get sign-off for a budget for purpose X
- They agree
- You document at least two options for products that fulfil that purpose
- The ‘sourcing team’ take that document and negotiate with the suppliers
- Some magic happens
- You get told which supplier ‘won’
You can see why this process helps reduce the risk that someone takes a bribe to push a particular vendor solution (there are also often strict rules around accepting so much as a coffee from a potential supplier), which is a good thing. On the other hand, this process can take months or even years… And might need to be repeated if the process takes so long that funding has disappeared or teams have been disbanded. To complicate matters further, sourcing might have its own ‘preferred supplier lists‘ of companies that have been vetted and audited in the past. If your preferred supplier isn’t on that list (and hasn’t made a deal with one on the list), the process could take even longer.
3) Cumulative constraints
What we have learned so far is that enterprises are fundamentally slowed down by attempts to reduce individual power and responsibility in favour of corporate responsibility. This usually results in:
- More onerous change control
- Higher bars for change planning
- Higher bars for buying solutions
- Higher bars for security requirements
- Separation of engineering and ops functions
It’s like entropy. You can fight it, but in the end physics wins. Now we’ll take a step outside these individual constraints to look at what happens when you structure a large scale enterprise organisation where its component groups are all fighting these same challenges.
Dependency constraints
When you try to deliver in an enterprise you will find that your team has dependencies on other teams to provide you IT services. The classic example of this is firewall changes. You, as a developer, decide—in classic agile microservices/’all the shiny’ fashion—to create a new service running on a particular port on a set of hosts. You gulp Coke Zero all night and daub the code together to get a working prototype. To allow connectivity, you need to open up some ports on the firewall. You raise a change, and discover the process involves updating a spreadsheet by hand and then raising a change request which requires at least a week’s notice. Your one night’s development is now going to hang around a week before you can try it out. And that’s assuming you filled everything out correctly and didn’t miss anything. If you did, then you have to go round again…
One of the joyous things about working in an unregulated startup is that if you see a problem in one of your dependencies you have the option of taking it over and running it yourself. Don’t like your cloud provider? Switch. Think your app might work better in Erlang? Rewrite. Fed up with the firewall process? Write a script to do that, and move to GitOps.
So why not do the same in the enterprise? Why not just ‘find your dependencies and eliminate them‘? Some do indeed take this approach, and it costs them dearly. Either they have to spend great sums of money managing the processes required to maintain and stay ‘within governance’ for the technology they’ve decided to own, or they get hit with an audit sooner or later and get found out. At that point, they might go cap in hand to the infrastructure team, whose sympathy to their plight is in proportion to the amount of funding infrastructure is being offered to solve the problems for them…
The reality is that—as I said above—taking responsibility and owning a technology or layer of your stack brings with it real costs and risks that you may not be able to bear and stay in business. So however great you are as a team, your delivery cadence is constrained to a local maxima based on your external dependencies, which are (effectively) non-negotiable. This is a scaling up of the same constraints on individuals in favour of corporate power and responsibility. Just as it is significantly harder for you to make that much difference, it is harder for your team to make much difference, for the same structural reasons.
Cultural constraints
Now that the ingredients for slow delivery are already there in a static, structural sense, let’s look at what happens when you ‘bake’ that structure over decades into the organisation and then try to make change within it.
Calcified paradigms
Reasoning about technology on a corporate scale is hard due to the difficulty of coordination and communication at large scale. Managing change within an enterprise can only work at all, therefore, if there are shared paradigms around which processes and functions can reason. These paradigms become ingrained, and the effort of surfacing and reshaping these conceptual frameworks can be required over and over again across an organisation if you are to successfully make change. The two big examples of this I’ve been aware of are the ‘machine paradigm’ and charging models, but one might add ‘secrets are used manually’ or many others that may also be bubbling under my conscious awareness.
The ‘machine paradigm’
Since von Neumann outlined the architecture of the computer, the view of the fundamental unit of computation as being a single discrete physical entity has held sway. Yes, you can share workloads on a single machine (mainframes still exist, for example, and two applications might use the same physical device), but for the broad mass of applications, the idea of needing a separate physical machine to run on (for performance or security reasons) has underpinned assumptions of applications’ design, build, test, and deploy phases.
Recently (mostly in the last 10 years), this paradigm has been modified by virtual machines, multiples of which sit on one larger machine that runs a hypervisor. Ironically, this has reinforced the ‘machine paradigm’, since for backward compatibility each VM has all the trappings of a physical machine, such as network interfaces, mac addresses, numbers of CPUs and so on. Whether you fill out a form and wait for a physical machine or a virtual machine to be provisioned makes little difference – you’re still in the machine paradigm. Recently, PaaSes, Kubernetes, and cloud computing have overthrown the idea that an application needs to sit on a ‘machine’, but the penetration of this novel (or rediscovered, if you used mainframes) idea, like the future, is unevenly distributed.
Charging models
Another paradigm that’s very hard to get traction on changing is charging models. How money moves around within an enterprise is a huge subject in itself, and has all sorts of secondary effects that are of no small interest to IT. To grossly generalise, IT is moving from a ‘capex’ model to an ‘opex’ model. Instead of buying kit and software and then running it until it wears out (capex), the ‘new’ model is to rent software and services which can be easily scaled up and down as business demand requires.
Now, if you think IT in an enterprise is conservative, then prepare to deal with those that manage and handle the money! For good reason, they are as a rule very disinclined to change payment models within an organisation, since any change in process will result in bugs (old and new) being surfaced, institutional upheaval, and who knows what else. The end result is that moving to these new models can be painful. Trying to cross-charge within an organisation of any size can result in surreal conversations about ‘wooden dollars’ (ie non-existent money exchanged in lieu of real money) or services being charged out to other parts of the business, but never paid for due to conversations that may or may not have been had outside your control.
Learned Helplessness
After decades of these habits of thoughts, you end up with several consequences:
- Those who don’t like the way of working leave
- Those that remain calcify into whole generations of employees
- Those that remain tend to prize and prefer those that agree with their views
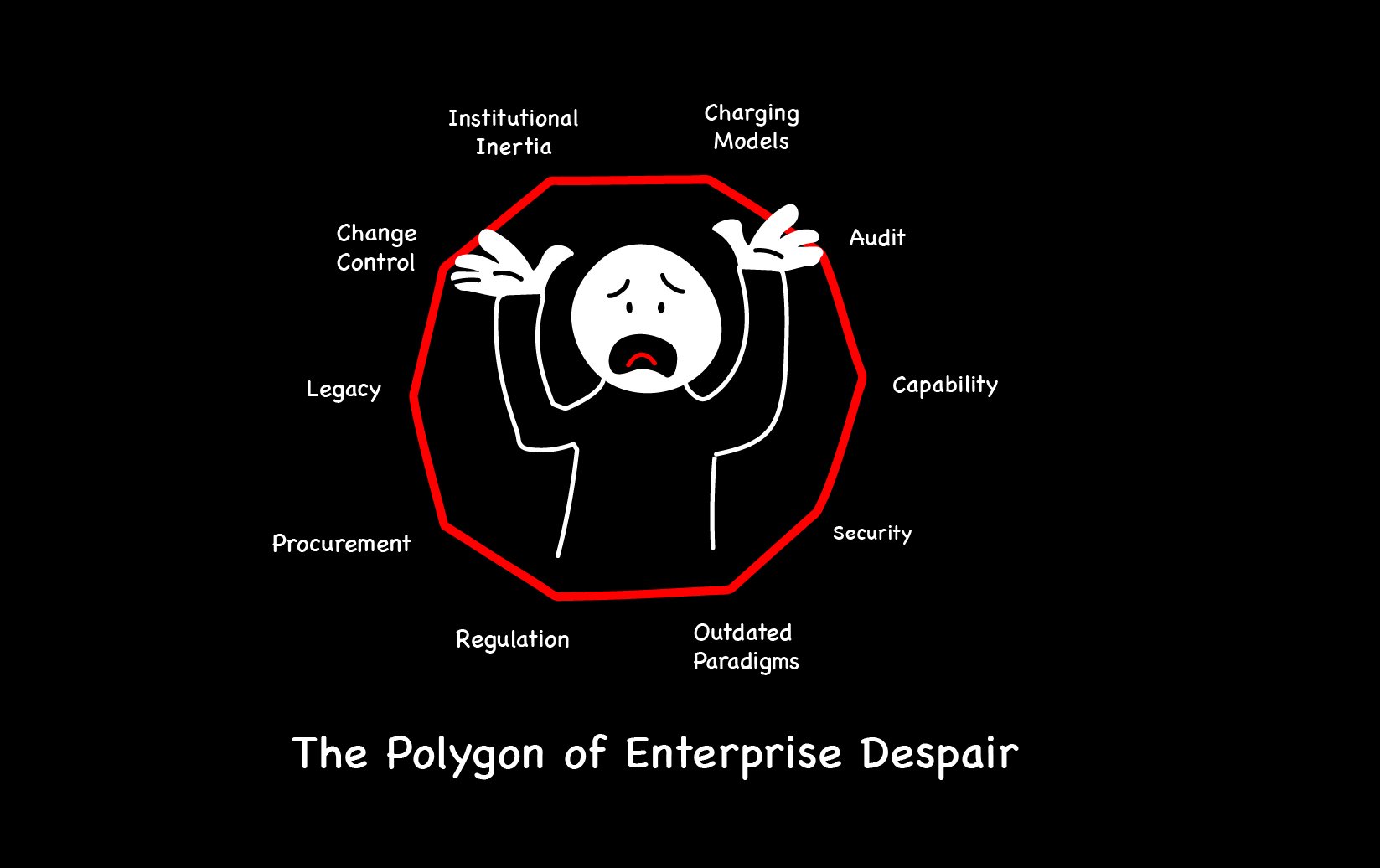
Suggestions of change to these groups of people result in entire generations, nay armies of employees that resist change. The irony is that they are completely right. Most efforts to change do fail, and therefore most efforts to do so are wasted. The reasons are arguably circular, i.e. that change is resisted because it won’t work, and it won’t work because it’s resisted. But it’s also quite rational, since the reasons it won’t work are based on the external constraints that exist as discussed above. But it’s simple game theory to follow the logic. This has previously been described as the ‘square of despair‘:
Although I’d prefer to call it the ‘polygon of despair‘, since these four are fairly arbitrary. You could add to this list, for example:
- Internal charging models
- Change control
- Institutional inertia
- Audit
- Regulation
- Outdated paradigms
all of which have been discussed above.
4) A new hope?
Is it all a lost cause? Is there really no hope for change? Does it always end up looking, at best, like a mass of compromises that feel like failure?

Well, no. But it is bloody hard. Here’s the things I think will stack the deck in your favour:
Senior leadership support
I think this is the big one. If you’re looking to swim against habits of thought, then stiff resolve is required. If senior management aren’t willing to sacrifice anything towards change, and/or aren’t united in favour of it, then all sorts of decisions won’t get made. These include primary decisions made by the leadership, as well as second-guessed decisions made by underlings from different branches of the management tree that have conflicting aims. Almost no-one likes to talk about it, but it helps if people get fired for not constructively working with the changes. That tends to focus the mind. The classic precedent of this is point 6 of Jeff Bezos’s ‘API Mandate’:

Reduce complexity
Talking of pain, you will do yourself favours if you fight tooth and nail to reduce complexity. This may involve taking some risks as you call out that the entire effort may be ruined by compromises that defeat the purpose, or create bureaucratic or technical quicksand that your project will flounder in later. Calling those dangers may get you a reputation, or even cost you your job. As the title of A Seat at the Table (a book I highly recommend on the subject) implies, it’s very close to a poker game.
Cross-functional team
It might sound obvious to those that work in smaller companies, but it’s much easier to achieve change if you have a team of people that span the functions of your organisation working together. The collaboration not only benefits from seeing how things need to be designed to fulfil requirements at an earlier stage, but more creative solutions are found by people who understand their function’s needs better, and the requirements of the project.
If you want to go the skunkworks route, then the representatives of the other functions can tell you where your MVP shortcuts are going to bite you later on. The alternative—and this is almost invariably much, much slower—is to ‘build, then check’. So you might spend several months building your solution before you find it’s fundamentally flawed, based on some corporate rule or principle that can’t be questioned.
Use your cynical old hands
The flip side of those that constitute the ‘institutional inertia’ I described above is that many of those people know the organisation inside out. These people often lose heart regarding change not because they no longer care, but because they believe that when push comes to shove the changes won’t get support. These people can be your biggest asset. The key is to persuade them that it’s possible, and that you need their help. That can be hard for both sides, as your enthusiasm for change hits their brick wall, cemented by their hard-won (or lost) experience. They may give you messages that are hard to hear about how hard it will be. But don’t underestimate the loyalty and resilience you get if they are heard.