

In my previous blog post we set up a Continuous Integration pipeline which created dynamic, ephemeral environments in Kubernetes. This was done exclusively using Kubernetes namespaces.
As mentioned in the previous post this solution leaves some holes, specifically around security. There are some basic questions which quickly arise:
- How do I ensure that my CI server doesn’t accidentally take down my staging environment due to a configuration mistake?
- What if my integration tests starts hitting production services?
- How can I avoid a load test on one environment from using up all the cluster resources affecting all other environments ?
These are all valid concerns, but luckily we have the necessary tools built-in to Kubernetes for handling these. Let’s take a look at each of these questions in turn, the features which are available to address them, and finally add them to our existing setup on GitLab. First up, how can we control access to each environment?
Role Based Access Control
Originally introduced in Kubernetes version 1.6 as beta and since upgraded to ‘stable’ in version 1.8, Role Based Access Control (RBAC) was a major piece needed to get Kubernetes ‘Production Ready’. If we are using namespaces alone to create environments, then there is no control over who has access to which environments, or who can do what. If we are sharing a single physical cluster then by default all external users (e.g. developers) have access and can modify any environment. RBAC solves this problem for us. We can create fine grained control for users of our cluster, and what permissions they have. For example, we can define a role called ‘Developer’ which may have full access to a Developer namespace, but no access (or maybe restricted access) to a Staging namespace.
In order to integrate this with our existing Continuous Integration pipeline we will add a step to our `deploy` stage to configure the necessary Roles and RoleBindings when we create our new namespace:
- sed -e "s/NAMESPACE/$NAMESPACE/g" templates/rbac.yaml | tee ".generated/rbac.yaml"
- kubectl apply -f ./generated/rbac.yaml
The template for the rbac contains both the Role which we apply to the namespace, as well as the RoleBinding:
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1alpha1
metadata:
name: developer
namespace: NAMESPACE
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: developer
namespace: NAMESPACE
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: developer
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: dev-users
Note: the RoleBinding applies to the `Group` `dev-users`. This allows us to attach the role to all developers.
Network Policies
Next we want to ensure only services within the same environment are speaking to each other, we can accomplish this thanks to Network Policies (also improved in version 1.8). With the initial namespace only solution, while pods within a namespace will generally only communicate with other pods in the same namespace, this is not actually enforced. An application in the developer namespace is able to access a pod in the staging namespace simply by prefacing the DNSname with the namespace (e.g. staging.carts). Therefore Network Policies are a great solution for the more security conscious. A Network Policy allows us to restrict which applications can communicate with each other. They are quite flexible: we can control ingress, egress or bi-directional traffic, and specify individual pods or groups of them. For our use case we can also apply these to an entire namespace. With the flexibility provided, we could also poke holes in our internal Kubernetes firewall, for example if we want to run tests from outside the environment.
Note that Network Policies are taken care of by the Pod Network Plugin of your cluster. Not all plugins support this.
Again, we add a few lines to our existing pipeline file to configure the NetworkPolicy:
- sed -e "s/NAMESPACE/$NAMESPACE/g" templates/networkPolicy.yaml | tee ".generated/networkPolicy.yaml"
- kubectl apply -f ./generated/networkPolicy.yaml
One thing we will need to change is to add a label to our new Namespaces, as the namespaceSelector, used in the NetworkPolicy, acts on labels. So let’s move the namespace creation to a file:
apiVersion: v1
kind: Namespace
metadata:
name: NAMESPACE_ENV
labels:
And we use a template which contains the default NetworkPolicy:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: NAMESPACE-isolation-policy
namespace: NAMESPACE
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
dev-env: NAMESPACE
egress:
- to:
- namespaceSelector:
matchLabels:
dev-env: NAMESPACE
Resource Quotas
Finally, a major concern we have with sharing a cluster is ensuring that separate environments don’t affect each other by consuming the shared underlying resources. We can do this by implementing Resource Quotas. The risk of sharing a single cluster with different users and environments is that more resource hungry environments could use up the entire resources of the cluster leaving nothing for other namespaces/environments. The solution here is to use Limits which allows us to restrict an entire namespace to a maximum amount of CPU and Memory. This will require some tweaking before we get the optimal values. A simple Resource Quota, with only limits looks like this:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "3"
limits.cpu: "3"
limits.memory: 3Gi
And we will apply the same Resource Quota to each new namespace which gets created:
- kubectl apply -f ./templates/resourceQuota.yaml -n $NAMESPACE
Thanks to the above above features, we now have a fully robust way of creating ephemeral environments on demand. While the focus here has been on creating environments as part of a CI pipeline, this pattern could easily be extended to many other use cases. We could offer a Kubernetes on demand platform for development teams for example, Using a single cluster and shared resources. The diagram below shows the provided isolation:
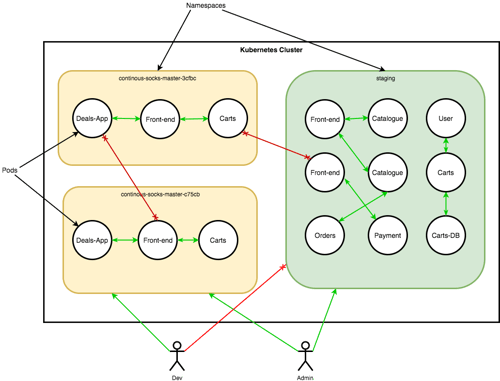
We can take things further if necessary, by using labels and NodeSelectors we can isolate certain environments or applications to a specific set of nodes within our cluster. We can also enforce end-to-end service authentication and encryption via mutual TLS. This however is not available out of the box with Kubernetes, but we can add it via a service mesh, like Linkerd, Istio, or Conduit. How much isolation and security you require between environments will depend on your specific requirements.
One of the benefits of an orchestration platform, such as Kubernetes, is to make efficient use of your compute resources. However, if you spin up an entire cluster for each environment or new project then you will instead end up increasing your resource usage. Kubernetes provides a nice abstraction of the underlying infrastructure, and as we have seen in this post it has the necessary features to create isolated, secure virtual environments within a single cluster. We can extend this pattern to other use cases as well, running multiple distinct projects on a cluster for example, or providing multi-tenant isolation, or event offering virtual clusters ‘on-demand’ to development teams. Using RBAC to control access between namespaces, NetworkPolicies to restrict unwanted traffic and ResourceQuotas to limit resource consumption we can feel confident sharing a single cluster securely.
We have a course about Production Grade Kubernetes. Click on the image to find out more or email us at info@container-solutions.com.
