
In Google’s 5 Principles For Cloud Native Architecture, one of the conclusions is that ‘almost all cloud architectures are based on a microservices architecture’. There are several reasons for that, one of which being that this type of architecture fits Google’s five principles to a T. But there are other reasons, both historical and technical, that we will explore in this post.
A microservices architecture is not a panacea. There are some clear pros and cons to consider.
First, Some History
From the very early days of the Internet, the idea of distributed computing has been part of the conversation. It is only natural: given the capability to connect many computers together, how can it be used to create more powerful applications?
In fact, the whole idea behind one of the predecessors of the Internet, ARPANET, was ‘to make it possible for research institutions to use the processing power of other institutions’ computers when they had large calculations to do that required more power, or when someone else's facility might do the job better’.
By the early 1970s, e-mail had become the most successful application of ARPANET and it is probably the earliest example of a large-scale distributed application. Almost two decades later, another distributed application, the World Wide Web, became the driver of the general adoption of the Internet.
In the meantime, distributed computing became its own field of study, and many well-known, distributed architecture types were described: client-server, three-tier, and peer-to-peer, to name but a few.
Simultaneously, individual computers got more and more powerful, and some of the applications developed for them grew to be vast and complex, and hard to manage and update. The prime example of such an application is the Amazon e-commerce website, circa 2001. Releasing a new version of it required reconciling the in-process changes from hundreds of developers, resolving all the conflicts between them, merging them into a single version, and producing a master version that waited on the queue to be moved into production.
According to Amazon AWS senior manager for product management Rob Brigham, they ‘went through the code, and pulled out functional units that served a single purpose, and we wrapped those with a web service interface. For example, there was a single service that rendered the Buy button on the retailer’s product detail pages. Another had the function of calculating the correct tax during checkout’.
In other words, step by step, Amazon broke up its monolithic website, and replaced it with numerous services that only communicated through their web-based interfaces. These services we would now refer to as ‘microservices’.
In the process, they more-or-less invented cloud computing as we know it now. By providing their cloud services to third parties, they enabled another well-known Internet giant to replace its monolithic architecture with microservices: Netflix. In the world of microservices, Netflix’s transformation project is one of most-discussed, since it can be considered the first example of a cloud-based transformation to microservices.
Interestingly, a number of other internet companies, including Google and eBay, arrived at more-or-less the same architectural style at more-or-less at the same time and for very similar reasons.
OK, But Y Tho?
Amazon uses the following definition of a microservice:
‘With a microservices architecture, an application is built as independent components that run each application process as a service. These services communicate via a well-defined interface using lightweight APIs. Services are built for business capabilities and each service performs a single function. Because they are independently run, each service can be updated, deployed, and scaled to meet demand for specific functions of an application’.
As an aside, the ‘lightweight APIs’ in that quote are usually RESTful ones, in practice. REST has become the de facto standard, because it uses HTTP, and is therefore a good fit for public APIs. However, when designing a microservices architecture, we’re not necessarily dealing with public APIs, so we’re free to choose alternatives, such as GraphQL or gRPC. These may yield much better performance and may fit a given set of operations better.
As we saw in the Amazon example in the previous section, updating a large and complex monolithic application generates a lot of overhead in the shape of coordination work that has nothing to do with the actual functionality. Switching to a microservices-based architecture reduces that overhead: since microservices are loosely coupled, they can be updated without impacting the other parts of the application.
Microservices also provide agility to the development process. A single team that’s working on a microservice can make their own decisions on the coding language, database, and when a new version should be deployed.

Not all aspects of an application experience the same demands. For example, user management may only be used once in a while, but methods that query the database may be called many times a second. With microservices, scaling becomes not only easier, but can also be tailored to the needs of each service.
When one microservice experiences a problem, it will not necessarily impact other microservices, which may continue to work as normal. A well-designed microservices architecture can therefore improve the robustness of the application.
Microservices and Their Trade-Offs
Having said all that, the microservices-based architecture is not a panacea; there are definitely cases where a monolithic application may be a better fit.
Typically, microservices are organised around business capability. A side effect of this is that the architectural style is a poor choice if the problem domain is not well understood. It is still good advice not to start with a microservice; if you need to develop an MVP (minimum viable product) quickly, with a single small team, it makes much more sense to create a monolith that has all the required functionality, evolve it until you are happy, and then move to a microservice architecture when you are hitting team or application scaling challenges.
Microservices come with considerable operational complexity, in effect trading off individual developer productivity against a more complex system.
Microservices only really work for problems that scale well horizontally. Not every problem does.
Given all of this, it is worth taking the time to consider if you really need a microservice approach before you go down this route. There have recently been a few cases of companies discussing the fact that they adopted microservices and then went back to a monolith.
One Does Not Simply Walk into Microservices
In light of the trade-offs, what explains the popularity of the microservices approach? Beyond the Netflix effect, two important factors that have driven adoption of microservices are cloud computing and containerisation. Whilst it’s certainly possible to implement microservices without those, they certainly do seem to be made for the purpose.
As we saw, commercial cloud computing was more-or-less a side effect of Amazon’s transition away from monolithic applications. It’s no surprise, then, that the two paradigms fit each other like hand and glove. Whilst microservices can certainly be run on-premise, horizontal scaling is much easier to do in the cloud.
Another important consideration is cost: if your application experiences peak hours and you run it on-premise, your infrastructure needs to be able to support those peaks, and a lot of it will sit idle at non-peak hours. Using cloud computing, you can scale out to support peaks, and scale back afterwards, leading to considerable savings.
Then, containers. The idea of a container is to have an executable packaged with all its dependencies and configuration, so it can run self-sufficiently. Sound familiar? Isn’t that a lot like a microservice? Yes, it is, and that is why they fit microservices so well.
The use of containers brings another huge advantage to a microservices architecture. There are tools that make it very easy to run, scale, manage (in other words, orchestrate) containers, while abstracting from the underlying hardware. The foremost of these is Kubernetes (or k8s for short). Originally developed at Google, it was open-sourced in 2014, and has more-or-less become the de facto standard. To reiterate, you can have microservices without containers, and you can have containers without Kubernetes, but having these standard options has certainly made the threshold of adopting a microservices architecture a lot lower.
A Sample Use Case
Hopefully, by now, you’re pretty convinced that a microservices architecture is a great idea for a lot of applications. Let’s have a look at a specific use case, in order to solidify the concepts.
Let’s say we are designing a fairly typical e-commerce application, in which orders are taken, inventory and available credit are verified, and shipping is managed. In a monolithic application, the architecture may look like this:
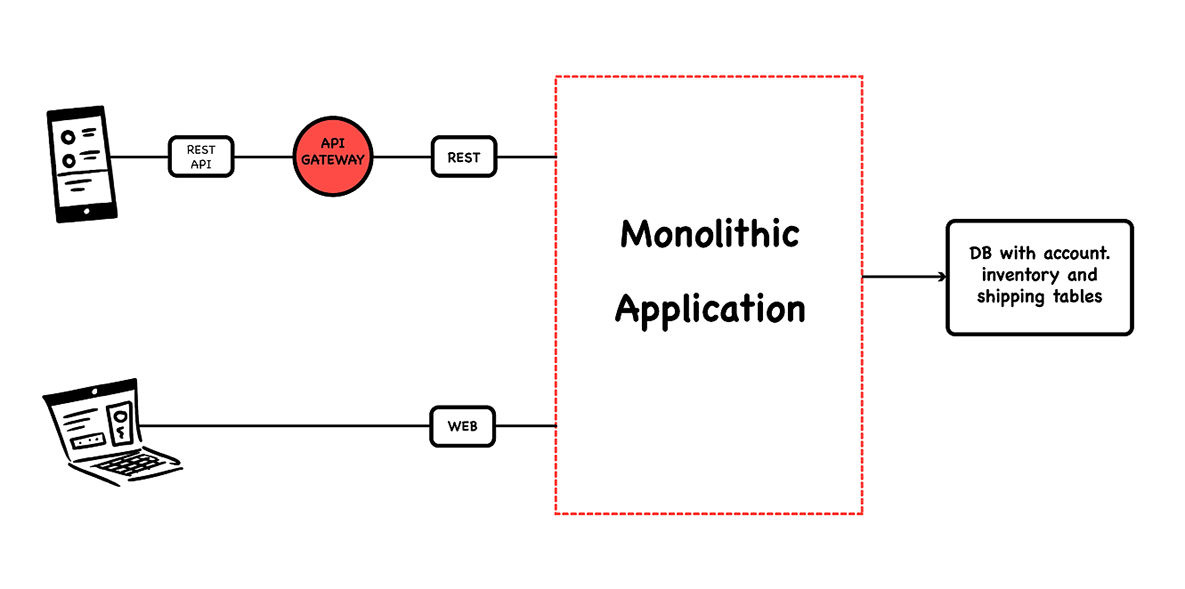
Whereas if we design the application as a set of microservices, it may look like this:
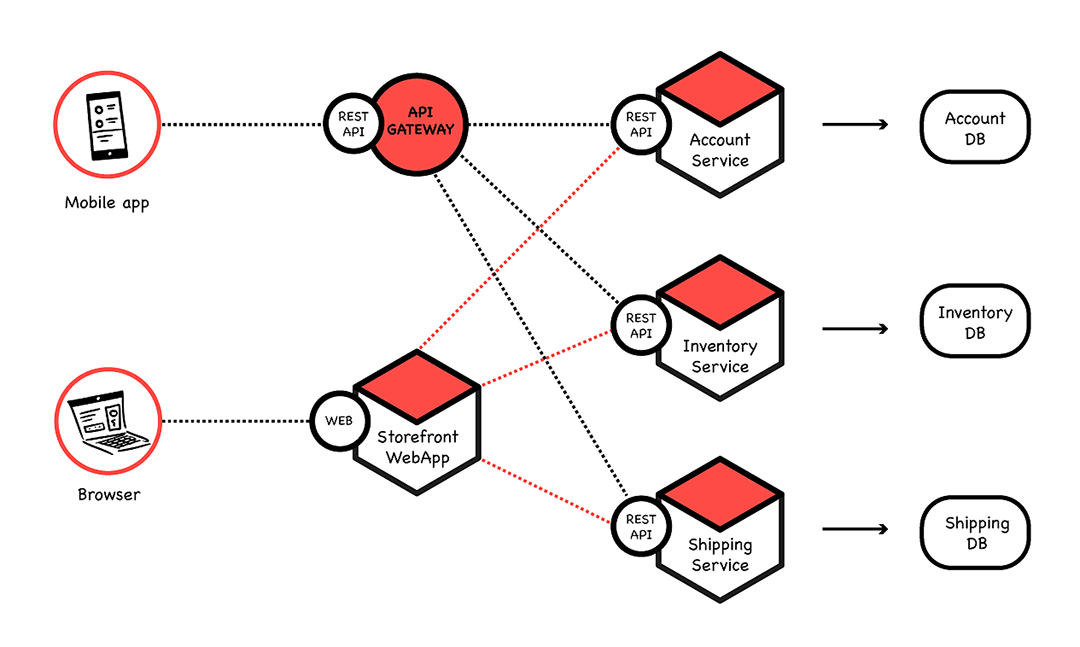
We see that the storefront UI, account management, inventory, and shipping are all implemented as independent services, with their own databases, and communicating via their RESTful API’s.
The advantages are clear:
- Smaller units are easier to:
- Understand
- Maintain
- Test
- Deploy
- Scale
- The application is more fault tolerant, since the failure of one service doesn’t necessarily mean the others will stop working.
- The services are not bound to the same technology stack. There is no reason they couldn’t all be implemented in completely different ways, or migrated separately, as long as they’re able to communicate through their API’s.
- Developer teams can be organised independently around each service, letting developers focus on their area of expertise, and decide on the strategies for deploying, testing, and scaling best suited to their service.
Yet, there are disadvantages, too:
- Each development team will have to work on the API for their service, adding overhead on top of ‘just’ implementing the functionality.
- Testing the application as a whole can become more complex. Integration between the services needs to be part of the testing strategy, as well as the various failure modes in which one or more services become unavailable.
- Potentially, the need for memory and/or storage will increase, compared to the monolithic design.
Conclusion
In this post, we looked at microservices architecture in historical and technical perspectives, considered why it has become so popular, and worked through an example. For further reading, we suggest taking a look at the Cloud Native patterns that are related to what has been discussed here:
Microservices Architecture
To reduce the costs of coordination among teams delivering large monolithic applications, build the software as a suite of modular services that are built, deployed, and operated independently.
Containerized Apps
When an application is packaged in a container with all its necessary dependencies, it does not rely on the underlying runtime environment and so can run agnostically on any platform.
Private Cloud
A private cloud approach, operated either over the Internet or on company-owned, on-premises infrastructure, can offer the benefits of cloud computing services like AWS while restricting access to only select users.
Public Cloud
Instead of using your own hardware, rely on the hardware managed by public cloud vendors whenever possible.
Self Service
In Cloud Native everyone can do their own provisioning and deployment, with no handoffs between teams.
