
GitOps is the latest hot trend in the software delivery space, following (and extending) on older trends such as DevOps, infrastructure as code, and CI/CD. So you’ve read up on GitOps, you’ve bought into it, and you decide to roll it out across your business.
This is where the fun starts. The benefits of GitOps are very easy to identify, such as:
- Fully audited changes for free
- Continuous integration and delivery
- Better control over change management
- The possibility of replacing the joys of ServiceNow with pull requests
However, the reality is that constructing your GitOps pipelines is far from trivial, and involves many big and small decisions that add up to a lot of work to implement. We at Container Solutions call this ‘GitOps Architecture’ and it can result in real challenges in implementation.
The good news is that with a bit of planning and experience you can significantly reduce the pain involved in the transition to a GitOps delivery paradigm.
In this blog post, I want to illustrate some of these challenges by telling the story of a company that adopts GitOps as a small scrappy startup, and grows to a regulated multinational enterprise. While such accelerated growth is rare, it does reflect the experience of many teams in larger organisations as they move from proof of concept, to minimum viable product, to mature system.
'Naive' Startup
If you’re just starting out, the simplest thing to do is create a single Git repository with all your needed code in it. This might include:
- Application code
- A Dockerfile, to build the application image
- Some CI/CD pipeline code (eg GitLab CI/CD, or GitHub Actions)
- Terraform code to provision resources needed to run the application
In addition, all changes are directly made to master, and thus changes go straight to live.
The main benefits of this approach are that you have a single point of reference, and tight integration of all your code. If all of your developers are fully trusted and shipping speed is everything, then this might work for a while.
Unfortunately, as your business grows, the downsides of this approach start to show pretty quickly.
Firstly, as more and more code gets added the ballooning size of the repository can result in confusion among engineers as they come across more conflicts between their changes that must be resolved. If the team grows significantly, then the resultant rebasing and merging leads to further confusion and frustration.

Second, you can run into difficulties if you need to separate the control or cadence of pipeline runs. Sometimes you just want to quickly test a change to the code rather than deploy to live with complete end-to-end delivery. The monolithic aspect of this approach creates more and more problems that need to be resolved, potentially impacting others’ work as these changes are worked through.
Third, as you grow you may want more fine-grained boundaries of responsibilities between engineers and/or teams. While this can be achieved with a single repo (newer features like CODEOWNERS files can make this pretty sophisticated), a repository is often a clearer and cleaner boundary.

Repository Separation
It’s getting heavy. Pipelines are crowded and merges are becoming painful. Your teams are specialising and separating into different areas of responsibility.
So you decide to separate repositories out. This is where you’re first faced with a mountain of decisions to make. What is the right level of separation for repositories? Do you have one repository for application code? Seems sensible, right? And include the Docker build stuff in there with it? Well, there’s not much point separating that.
What about all the team Terraform code? Should that be in one new repository? That sounds sensible. But, oh: the newly-created central ‘platform’ team wants to control access to the core IAM (Identity and Access Management) rule definitions in AWS, and the teams’ RDS provisioning code is in there as well, which the development team want to regularly tweak.
So you decide to separate out the Terraform into two repos: a ‘platform’ one and an ‘application-specific’ one. This creates another challenge, as you now also need to separate the Terraform state files. Not an insurmountable problem, but this isn’t the fast feature delivery you’re used to, so your product manager is going to have to explain why feature requests are taking longer than previously because of these shenanigans. Maybe you should have thought about this more in advance …
Unfortunately there are no established best practices or patterns for these GitOps decisions yet. And, let’s face it, people love to argue about these sorts of things, so even if there were, getting consensus would probably still be difficult!
The problems of separation don’t end there. Whereas before, coordination between components of the build within the pipeline was trivial (as all the required elements were co-located), now you have to orchestrate information flow between repositories. For example: when a new Docker image is built, this may need to trigger a deployment in a centralised platform repository along with passing over the new image name as part of that trigger.
Again, these are not insurmountable engineering challenges, but they’re easier to implement early on in the construction of a GitOps pipeline. Later, when procedures, policy, and process are more established, making changes becomes more difficult to negotiate with your GitOps architecture’s consuming teams.
Distributed vs. Centralised
OK, your business is growing, and you’re building more and more applications and services. It increasingly becomes clear that you need some kind of consistency in structure in terms of how applications are built and deployed. The central platform team tries to start enforcing these standards. Now you get pushback from the development teams who say they were promised more autonomy and control than they had in the ‘bad old days’ of centralised IT before DevOps and GitOps.
If these kinds of challenges ring bells in readers’ heads, it may be because there is an analogy here between GitOps and monolith vs microservices arguments in the application architecture space. Just as you see in those arguments, the tension between distributed and centralised responsibility rears its head more and more as the system matures and grows in size and scope.
On one level, your GitOps flow is just like any other distributed system where poking one part of it may have effects not clearly understood, if you don’t design it well.
Environments
At about the same time as you decide to separate repositories, you realise that you need a consistent way to manage different deployment environments. Going straight to live no longer cuts it, as a series of outages has helped birth a QA team who want to test changes before they go out.
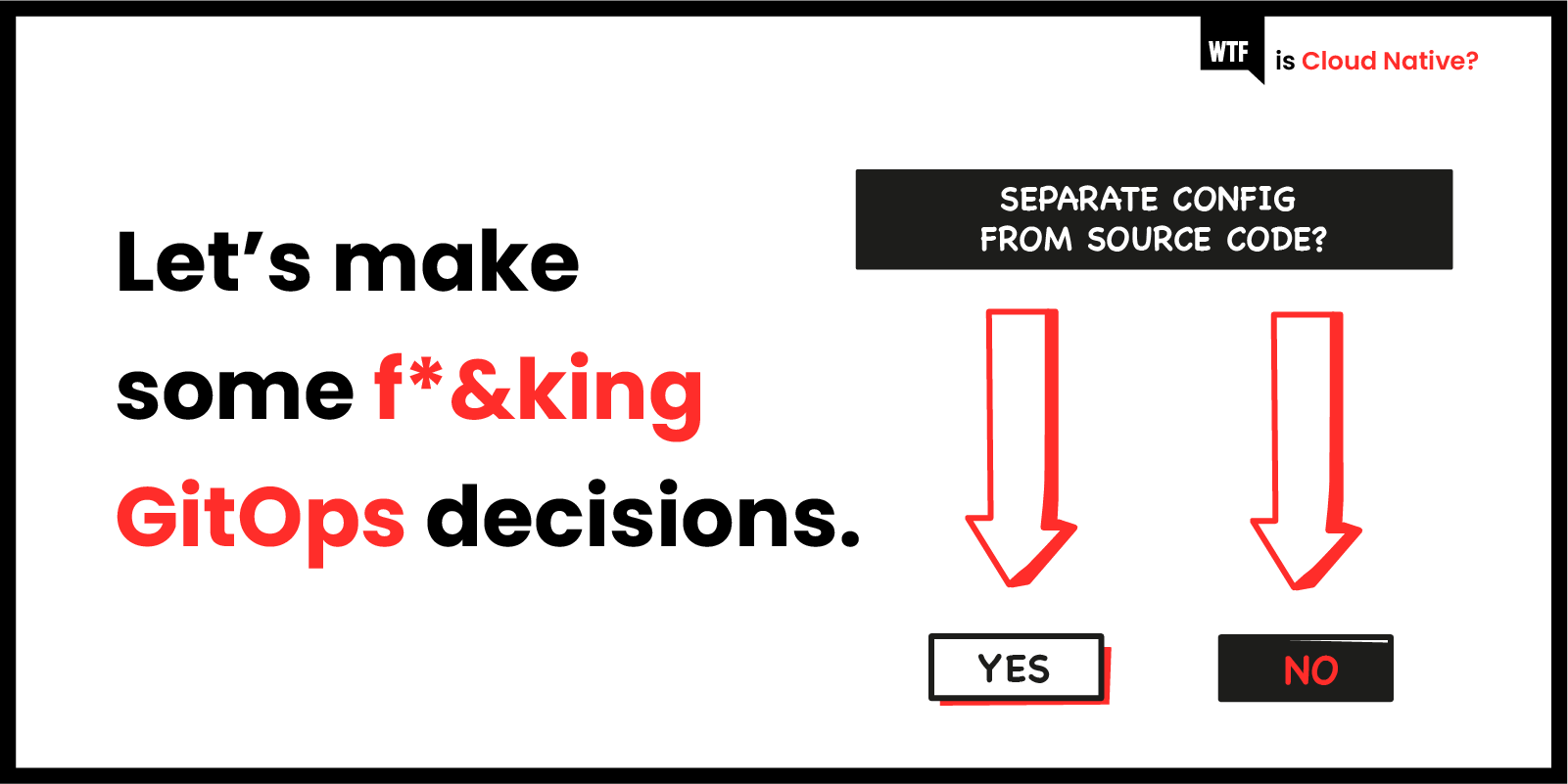
Now you need to specify different Docker tags for your application images in ‘test’ and ‘QA’ environments. You might also want different instance sizes or replication features enabled in different environments. How do you manage the configuration of these different environments in source? A naive way to do this might be to have a separate Git repository per environment (such as: super-app-dev, super-app-qa, super-app-live).
Separating repositories has the ‘clear separation’ benefit that we saw with dividing up the Terraform code above. However, few end up liking this solution, as it can require a level of Git knowledge and discipline most teams don’t have in order to port changes between repositories with potentially differing histories. There will necessarily be a lot of duplicated code between the repositories, and–over time–potentially a lot of drift, too.
If you want to keep things to a single repo, you have (at least) three options:
- A directory per environment
- A branch per environment
- A tag per environment
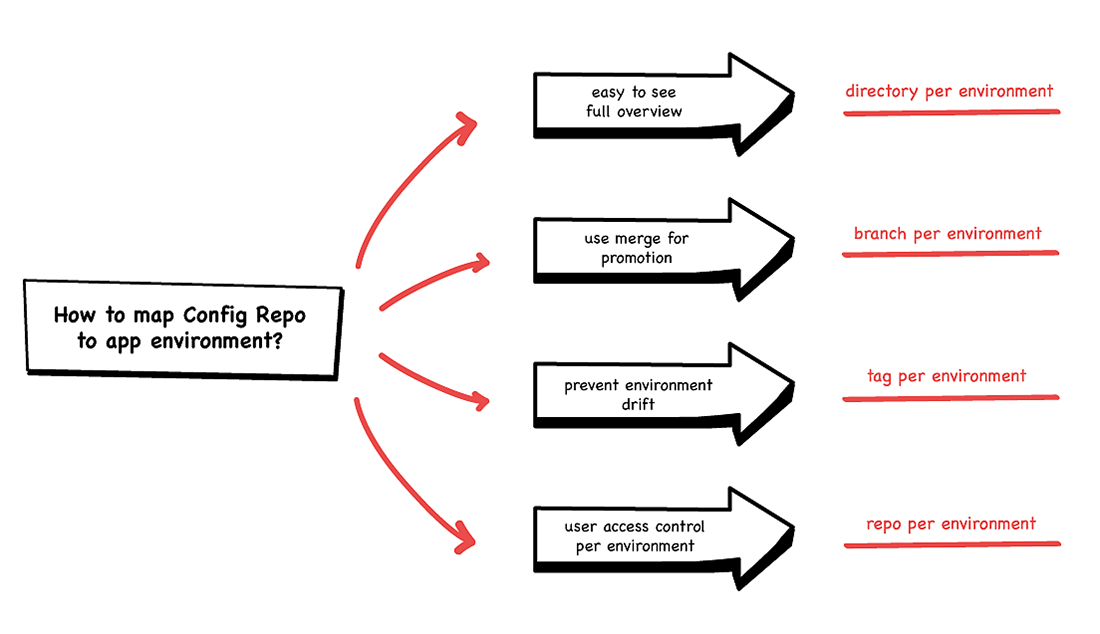
Sync Step Choices
If you rely heavily on a YAML generator or templating tool, then you will likely be nudged more towards one or other choice. Kustomize, for example, strongly encourages a directory-based separation of environments. If you’re using raw YAML, then a branch or tagging approach might make you more comfortable. If you have previous experience with applying one or the other of these approaches using your existing CI tool, then you are more likely to prefer that approach. Whichever choice you make, prepare yourself for much angst and discussion about whether you’ve chosen the right path.
Runtime Environment Granularity
Yet again, in your runtime environments, there are choices to be made on what level of separation you want. At the cluster level, if you’re using Kubernetes, you can choose between:
- One cluster to rule them all
- A cluster per environment
- A cluster per team
At one extreme, you can put all your environments into one cluster. Usually though, there is at least a separate cluster for production in most organisations.
Once you’ve figured out your cluster policy, at the namespace level you can still choose between:
- A namespace per environment
- A namespace per application/service
- A namespace per engineer
- A namespace per build
Platform teams often start with a ‘dev’, ‘test’, ‘prod’ namespace setup, before realising they want more granular separation of teams’ work.
You can also mix and match these options—for example, offering each engineer their own namespace for ‘desk testing’, as well as a namespace per team.
Conclusion
We’ve only scratched the surface here of the areas of decision making required to get a mature GitOps flow going. You might also consider RBAC/IAM and onboarding, for example, as absolute requirements if you do grow to become that multinational enterprise.
Often, rolling out GitOps can feel like a lot of front-loaded work and investment, until you realise that before you did this, less (or even none) of it was encoded at all. Before GitOps, chaos and delays ensued as no one could be sure in what state anything was, or should be. These resulted in secondary costs as auditors did spot checks and outages caused by unexpected and unrecorded changes occupied your most expensive employees’ attention.
As you mature your GitOps flow, the benefits multiply, and your process takes care of many of these challenges. But more often than not, you are under pressure to demonstrate success more quickly than you can build a stable framework.
The biggest challenge with GitOps right now is that there are no established patterns to guide you in your choices. As consultants, we’re often acting as Sherpas, guiding teams towards finding the best solutions for them and nudging them in certain directions based on our experience.
What I’ve observed, though, is that choices avoided early on because they seem ‘too complicated’ are often regretted later. This doesn’t mean that you should jump straight to a namespace per build, and a Kubernetes cluster per team, for two reasons:
- Every time you add complexity to your GitOps architecture, you will end up adding to the cost and time to deliver a working GitOps solution.
- You might genuinely never need that setup anyway.
Until we have accepted, workable standards in this space, getting your GitOps architecture right will always be an art rather than a science.
A version of this post originally appeared on the blog Zwischenzugs.
