
Since first publishing the Monitoring Performance in Microservice Architectures article in a post, I have received many questions, which I am going to address here. I am also going to use this opportunity to discuss other aspects of distributed computing such as scheduling, support, and tracing.
What is Semantic Monitoring if you would try to explain it in the simplest terms?
Semantic Monitoring is a new way of processing monitoring data inspired by physics and biology.
In physics, it’s very common to reduce the complexity of phenomena. If for instance we would try to describe the behavior of a planet by analyzing all the interactions between its atoms, we would be doomed to fail. First, the data would be very chaotic, and second, the computer needed to process the data in real time would probably also need to be of the size of a planet. But when we shift the focus from atoms to the planet itself, understood here as being a spherical object, then understanding its behavior becomes much easier. In biology, we apply a similar approach. For instance, we never monitor the individual cells of the heart, instead we monitor their collective performance - the heartbeat.
The essence of Semantic Monitoring is the application of this principle to software. It requires us to change the way we construct and monitor software, but in return it can reduce the number of alerts that reach the operator.
Some monitoring solutions seem to be very advanced. Are you sure that they do not implement Semantic Monitoring principles?
I am sure that they do not. Let me explain why. Some monitoring tools provide mechanisms for organizing microservices into role-based (i.e. semantic) groups, based on labels, image names, etc. However, these tools need to be manually configured by system operators. This means that the semantic context, even if provided, very quickly becomes outdated, since it’s impossible to keep the changes in the service in sync with updates of the monitoring configuration. In the past it could work, but since we have shifted from monolithic systems to microservices, keeping them in sync is no longer feasible, as long as this is a manual process. So effectively, we are far from Semantic Monitoring.
The reconfiguration of the monitoring must happen automatically. And the only way I can see it happening is if developers become actively involved in monitoring. Not actual monitoring in production, but their knowledge on how the given service should be monitored must “flow” automatically from development into production with every new release of the service.
(To explain this in the article, I used the metaphor of a bridge that connects development with the production environment, which is under construction, but is not there yet.)
It is hard to imagine developers willingly defining the monitoring, nevertheless I strongly believe they will soon become actively involved in this, because only they have the knowledge about what behavior should be considered as normal, and what is an anomaly. For instance, for video transcoders and build servers, high CPU load is expected, but for other services it could indicate a critical malfunction. In fact, the resource consumption pattern is unique for each service, much like a fingerprint.
This leads to another observation. In my opinion, today’s monitoring systems effectively break the abstraction of microservices, due to the fact that they monitor raw resource consumption (memory, CPU, I/O). This information should not leak outside of the microservices, as only each individual microservice can tell how much it needs to operate normally. So I expect that the knowledge of resource consumption will get encapsulated within the microservices, and the only information exposed will be an indicator saying how well they are doing. And truly this is the only thing we care about. Physical resources become increasingly irrelevant as we just need to know if a service has everything it needs to operate efficiently. When this information becomes available, everything will become much simpler. In particular, it will become much easier to find correlations between the performance of various groups of microservices, which is what Semantic Monitoring is about.
The encapsulation (which could be also called the “virtualization”) of monitoring is the natural continuation of the process started with the virtualization of platforms. Later, it will also change scheduling, because today’s scheduling systems also make decisions in terms of raw resources, which causes the microservice abstraction to leak in exactly the same way as it now does through monitoring. So I think that future scheduling and monitoring systems will work together as two opposite forces trying to find the balance. Schedulers will try to reduce the amount of resources a microservice is given up to the point that it starts complaining (by means of its internal monitoring) - “I’m feeling bad”. And this is how the balance (homeostasis) will emerge. The role of developers will be teaching the microservice what “feeling bad” means (supervised learning), so that it may detect and communicate its state in production.
[tweetthis twitter_handles="@containersoluti @lguminski" hidden_hashtags=”#microservice"]"Today's schedulers and monitoring systems cause leaks in microservice abstraction."[/tweetthis]
Summing up, once the two things exist – the way to encapsulate monitoring within microservices, and to automatically update monitoring in production with every release of a microservice – then we will be able to create true Semantic Monitoring tools.
The grouping of microservices seems to be essential for Semantic Monitoring to work. How will the groups be organized?
I believe that our software systems naturally evolve into layered hierarchical systems. Again, I will use physics to explain this. The physical universe we live in could be modelled as a layered hierarchical structure - quarks build subatomic particles, the particles build atoms, atoms build molecules. This continues up to stars, which build galaxies, galaxies build groups of galaxies, and galaxy groups build superclusters.
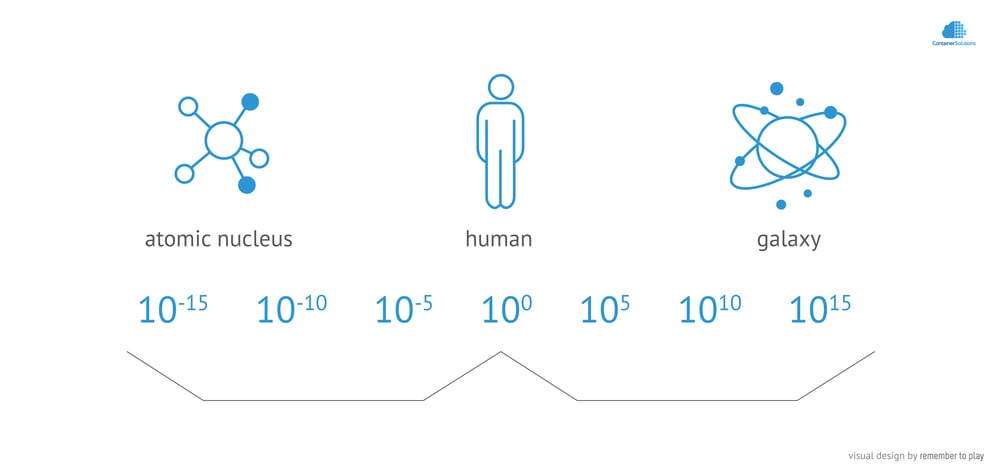
In the same way, individual microservices can be grouped into groups of microservices, groups of groups, groups of groups of groups… Endlessly. The first such bundles (LAMP, MEAN, ELK stack etc.) are already visible.
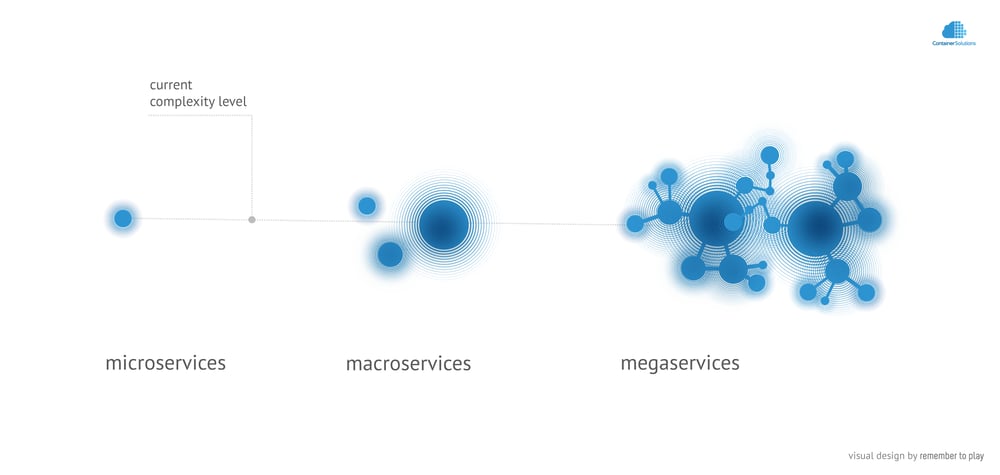
The advantage of grouping is that it reduces the amount of information that reaches the operator. This has been explained earlier by showing how important it is to shift focus from individual atoms to a planet as an entity, in order to understand its behaviour.
The shift of focus has another important effect. Atoms change their state and position so fast that we are even unable to fully follow the movement. But once we shift the observation to higher levels of abstraction, the perceived time starts “slowing” down. In other words, the temporal resolution of changes decreases, which means that anomalies need more time to build up and manifest. That’s why the movement of planets is so predictable to us, and for the same reason it is relatively easy for us to interact with other people (who are similar in size), but hard to follow the movement of a fly (which is small). Simply put, the resolution of perceived time changes with scale (as measured by Healy et al. [1]).
In the software context, microservices are clearly too fast for our human perception. The infrastructure becomes effectively ephemeral as explained in the original article. Martin Fowler coined the term “Serverless Architectures” (FaaS), and Adrian Cockroft uses the term “Monitorless” (I recommend his lecture on Monitoring Challenges at Motorama 2016), and says:
“Monitoring entities only exist during an execution trace" (Adrian Cockroft).
I believe that despite the inability to monitor microservices, we can still effectively monitor mega-services. But for that to work, the ability to group software into bigger and bigger entities is essential. And hierarchies are a very efficient method to that end.
In the original article, you compared energy-generating solar farms with microservices. Is it fair to compare solar plants and microservices? Microservices are ephemeral, and solar plants are fixed.
Solar plants look stable, but their output power is not stable at all. In fact, it is very variable. The variability is caused by every single cloud as it overshadows solar cells underneath. Furthermore, the power production drops to zero every night, which is effectively the same as if solar cells would cease to exist. Luckily, what can be observed is that the bigger the solar farm becomes, the more effectively it can eliminate the noise caused by clouds through the effect of superposition. This is almost as if the collective of solar cells could “see” clear sky. I expect that the same effect can be achieved if we measure the collective behavior of microservices.
How does Semantic Monitoring relate to software tracing?
Tracing is a technique used by developers for development and troubleshooting, whereas Semantic Monitoring is for the vendors of cloud computing platforms (of the next generation). As such, they aim at different purposes and answer different questions. Tracing is for developers who are focused on a specific software system, and Semantic Monitoring is more for those who have a holistic view on an ecosystem hosting many systems. In that sense, I perceive the two techniques as complementary, but orthogonal. More on Specific and Holistic Thinkers in the Dev and Ops in the Time of Clouds blog post.
You finished your paper by describing the 3rd phase (Semantic Monitoring). What comes next? The 4th one?
This is a difficult question. First we need to realize that 99% of the market is still in the phase of Stateful Monitoring, so it probably hasn’t ended yet. If this is the case, then the phase has already lasted for 17 years (counting from 1999, when Nagios appeared, until now, 2016). If the next generations (Syntactic and Semantic) are going to last equally long, we are talking about the perspective of decades. Personally, I hope it won’t take that much time, but this is still quite an intimidating question. So it is hard to answer it, as everything in such a time frame is speculation. But I think I am able to make an educated guess.
First I will start with the opinion of Michel Cotsaftis ([2]), with which I agree:
a new step is now under way to give man made systems more efficiency and autonomy by delegating more “intelligence” to them (…) This new step implies the introduction of “intention” into the system and not to stay as before at simple action level of following prescribed fixed trajectory dictated by classical control. (Michel Cotsaftis ([2])
And I think I know how this could happen.
I think that once we learn to express systems in the form of the hierarchy of layers, an interesting process will start. First, we will stop caring about the lowest level components - microservices. In fact, this has already started happening with the transition from “pets” to “cattle” (see [3]). Then, we will start caring less about groups of microservices. The process will continue up the hierarchy (groups of groups, groups of groups of groups, and so on), which effectively means that the lower levels will gradually gain more and more autonomy, complexity and intelligence - one layer after another. Still though, we will keep control and monitor the overall systems to make sure they comply with the expected behavior - the “intention”, to use Michel Cotsaftis’ term.
The increasing autonomy of software is an unstoppable trend, because it is economically beneficial - every progress on the path reduces the operational cost. So the process will continue until it reaches the top of the hierarchy, i.e. the entire software system. Then we may decide to entirely let go of control over the software entity. This would bring many benefits. I can easily imagine systems that autonomously travel around the ecosystem in order to detect and eliminate anomalies - like leukocytes in our blood.
We don’t have a term to describe this process. Unlike the technological singularity, which is considered to be a one-time globally-unique event, the moment of giving up control over software entities will be gradual. In one of my past blog posts I used an analogy to the process of releasing fish into the ocean, one after another, only in this case the released software entities will be released into a digital space (more on this in the From Microservices To Artificial Intelligence Operating System article).
But for now this is all science fiction. So if I am to return to the original question, I think that after Semantic Monitoring there won’t be a next phase of monitoring. I cannot imagine any additional information (context) which could be used for that. Instead, what will come will be the phase of Autonomy, which does not need monitoring in the sense I used it in the article i.e.:
a monitoring solution becomes functionally complete if it is able to perform two operations: collect information and alert if there is an anomaly.
Autonomous systems simply need no alerting (and thus no monitoring), because they are able to fix their anomalies automatically.
But it will take years to come to that point. For now, let us work on providing monitoring tools with all the information they need (historical, syntactic, and semantic contexts). Then it will take years to learn how to use it properly, in particular how to build in self-regulatory mechanisms into software systems so that they could adapt to a changing environment.
References
[1] Kevin Healy, Luke McNally, Graeme D. Ruxton, Natalie Cooper, Andrew L. Jackson - Metabolic rate and body size are linked with perception of temporal information http://www.sciencedirect.com/science/article/pii/S0003347213003060 (2013)
[2] Michel Cotsaftis, What Makes a System Complex? an Approach to Self-Organization and Emergence http://arxiv.org/pdf/0706.0440.pdf (2007)
[3] Simon Sharwood, Are your servers PETS or CATTLE? http://www.theregister.co.uk/2013/03/18/servers_pets_or_cattle_cern/ (2013)
Graphics designed by remember to play
Copyright 2016 Container Solutions B.V.