

This article is the beginning of a series.
Here’s a bold claim: It’s 2020 and we are in a post-cloud era. Cloud computing adoption has reached such a critical mass that even the most conservative organisations accept Cloud Native as a best practice. Concepts like DevOps methodologies, Infrastructure as Code, and CI/CD are now part of the vocabulary of enterprise developers.
In this series of articles, we will show you how the community is trying to bring the best from Cloud Native to the on-premises world. We will focus on the latest player in this game: Tinkerbell from Packet.

Tinkerbell brings a completely new way of looking at bare-metal provisioning. Even though the IT world has its head ‘in the cloud’, there are still use cases where it is worth building something from scratch on bare metal, especially if you want to learn how things really work. We will walk you through building your own homelab, and discuss what you can use it for. By the end of our journey you should no longer be scared of setting up bare-metal servers!
Cloud computing didn’t obliterate the need for hardware, as many of us might have thought 10 years ago. While cloud computing did deliver on the promise of cutting capex costs, and lowering the barrier to entry for computing resources, it brings challenges. There is always a trade off to be considering in paying your AWS bill and training your staff in cloud services. Once in the cloud, you are in danger of being ‘locked in’ to their relatively closed system, and at the mercy of them increasing prices or changing features at will.
At Container Solutions we see many organisations actively investing in their on-premise workloads. The reality is that there still are—and probably will always be—many use cases that are better suited to being run off the cloud. And many organisations are willing to try running their own infrastructure.
Identifying the underlying causes for this operational pattern is not an easy task, but we can look at the emergence of IoT and Edge computing for clues. Consumers expect amazing interactive experiences and flawless services. Latency-sensitive and data-intensive workloads will inevitably suffer, and computing will again be distributed closer to the source of this data: people and their devices.
On top of this, the public debate about the need to build more environmentally sustainable computing infrastructure continues to intensify.
This means smaller, more power-efficient, distributed platforms are needed. This could be a nightmare for administrators. But 10 years of cloud computing gave us the tools and the knowledge on how to build reliable systems on top of unreliable infrastructure. The big cloud players took care of this infrastructure for us, so we could focus on the upper layers. Kubernetes has effectively lowered the barrier to entry for building highly available distributed systems.
Meanwhile, lower down the stack, innovation and standardisation has been lagging behind. Bare-metal provisioning is a solved problem, but only for big cloud players and very large organisations that can afford capable, system-level engineering teams.
Breathing new life into the bootstrap process and bringing it to everyone on their own hardware is a massive opportunity.
Introducing Tinkerbell
Last December, Packet announced the open-sourcing of its bare-metal provisioning software, Tinkerbell. This is an important milestone for the community because Packet’s core business is bare-metal provisioning; they are very knowledgeable about physical servers and how to run them reliably. Their approach to provisioning bare metal servers is completely different from what we can see nowadays in the data-centre world.
Bare-Metal Provisioning: The Past
Currently if you want to install an operating system without the manual intervention, you would probably follow a process similar to this:
1. Create a golden image using Packer from Hashicorp, or other similar tool. This mostly consists of choosing your favorite OS distribution and defining some kind of kickstart file that does the initial configuration for you. If your operating system needs or hardware are very specific, you might consider building an operating system image by yourself by compiling the kernel, adding all the required packages, and putting them into a bootable image.
2. Ensure your physical server is booting from the network using PXE/iPXE network boot firmware. Once started, PXE will take care of booting up from a downloaded OS image . At a high level, once the machine is powered on, this ‘netbooting’ consist of two steps:
- The machine contacts a DHCP server and receives an IP address and details of the ‘next-server’, which will provide its configuration data.
- Connect to the ‘next-server’ and download the OS image using tftp or http.
If you are interested in this topic, here’s a website with more information and details about netbooting.
3. Configure the host with configuration-management software such as Puppet, Ansible, Chef, or Saltstack.
This approach is imperative and provides little information about why a machine failed to boot up correctly, especially if they occur during the second stage. Was there a hardware failure? A badly compiled kernel with missing drivers? Or something completely different?
Bare-Metal Provisioning: The Future
Tinkerbell from Packet tries to address some of these problems by bringing CI/CD principles to machine booting. More importantly, it closes the gap between creating an OS image and booting a machine with it. The main idea behind Tinkerbell is to divide the boot process into specific tasks and steps, which result in a fully provisioned bare-metal server. Here is an example of workflow execution for provisioning an Ubuntu server (you can download a PDF here for a better view):

Let’s break down Tinkerbell’s components (download a PDF here for a better view):
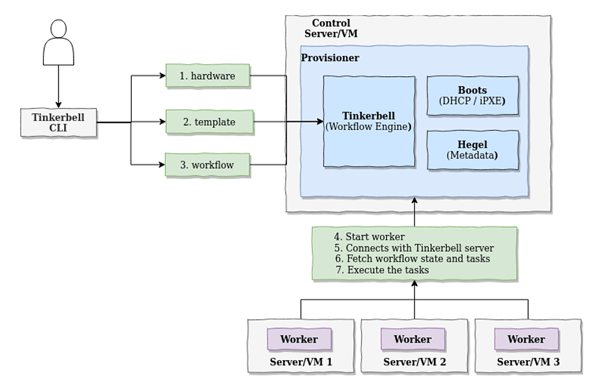
At the core is the provisioner, which consists of three elements:
- Tinkerbell: a workflow engine that oversees the successful execution of the workflow and is responsible for communicating with workers
- Boots: handles DHCP and pxe, ipxe, tftp requests
- Hegel: a metadata service used by workers to gather additional information during workflow execution
Another architectural component is a Worker. Workers are the physical servers targeted for provisioning. During the provisioning phase, the machines are first booted into an in-memory operating system called osie where the worker container executes the workflow.
How Does It All Work?
First of all, you have to define the hardware description of the targeted machine and upload it to Tinkerbell. Among other things, you define:
- the CPU architecture
- the supported pxe mode
- the desired IP address for each network interface
- the layout of the partitions on the hard drive
- the hostname
Once the definition is complete, you create a workflow template. A workflow template is a set of steps to be executed during provisioning. An example workflow might consist of erasing whatever system is already present in the machine, partitioning the disk, installing GRUB and an OS, and (optionally) configuring it.
Here is an example of a definition:
version: '0.1'
name: ubuntu_provisioning
global_timeout: 6000
tasks:
- name: "os-installation"
worker: "{
{.device_1 }}"
volumes:
- /dev:/dev
- /dev/console:/dev/console
- /lib/firmware:/lib/firmware:ro
actions:
- name: "disk-wipe"
image: disk-wipe:v3
timeout: 90
- name: "disk-partition"
image: disk-partition:v3
timeout: 600
environment:
MIRROR_HOST: 192.168.2.2
volumes:
- /statedir:/statedir
- name: "install-root-fs"
image: install-root-fs:v3
timeout: 600
environment:
MIRROR_HOST: 192.168.2.3
- name: "install-grub"
image: install-grub:v3
timeout: 600
environment:
MIRROR_HOST: 192.168.2.3
volumes:
- /statedir:/statedir
Next you need to assign the workflow template to the target machine. Now you can power on your machine and see the provisioning happen.
Provisioning consists of the following steps:
- The machine requests an IP address from DHCP server.
- Boots returns an IP address for the machine, along with the boot image.
- The physical machine boots into osie, which is an alpine-based in-memory environment. This is where the workflow is executed.
- An openrc init system initialises the workflow-helper, which in turn starts the ‘tink-worker’ container responsible for tracking workflow execution.
- Tink-worker runs Docker containers for each step of the workflow task and oversees its execution. On failure, it propagates the logs and error messages to the logging system. Note that each workflow step is actually a Docker container with the logic implemented by the administrator in the language of their choice (Bash, Golang, etc).
- At the time of writing this post, ipmi integration was not ready, but a possible future final step would be to reboot the host into the new OS. Fortunately, there are ways to reboot machines without resorting to the platform-management interface and this step can be part of the workflow task Docker container.
Tinkerbell is making a significant impact to the bare-metal provisioning with its CI/CD-like stages and tasks. More importantly, it opens doors for a declarative approach to traditional machine provisioning. We can imagine all workflows and the target hardware definition being part of a git repository and a single source of truth for both ‘Bootstrap as Code’ and data-centre inventory.
Next: In Part 2 of this series, Adam will explore the Homelab Movement.
