
Rest has become a widely accepted standard for API’s. There are a few reasons for this, it is easy to follow, works very much like a web browser does, and as such uses common tools to digest the service.
But REST brings baggage with it that can create complex, hard to maintain coupling when working in a diverse microservice environment.
URLs
URLs are one of the biggest issues with REST in microservices. URL schemes for REST and HATEAOS have a way of drawing services together into a monolithic system.
Context
URLs bring context to your service, meaning for a service to return properly formatted HATEOAS in its payload it needs to know where it stands in the entire architecture. The service needs to know that it resides at a URL.
http://foo.com/bar/12345
If all your services need to be aware of their surroundings you inch closer and closer to a monolith and further from a microservice infrastructure.
A better option is to abandon the idea of a service as an endpoint but instead embrace the idea of service as reference. It is better to reference your service as domain:service:method:1234
This means we do not need to know where or if the service is running, we just need to know this resource originated from this service reference. If we need to find the service we let the backend route it for us by reference and not by address. This allows your services to reside as endpoints on a router, as consumers of a queue, as a lambda fired after a DynamoDB insert, or as a subscriber to an SNS service.
It is the difference between entering in the address for the Starbucks you want to go to or searching in Google maps for the closest one. At any point in time the Starbucks you knew could be gone or most likely is not the closest one, and tomorrow the quickest method may be home delivery.
Routing
With REST, your routing and RESTful service become tied to each other, because of the mix of parameters and endpoints. As an example, given the url
foo.com/bar/1234
Your bar service is directly mapped to /bar if at some point you wish to reposition bar you will need to reconfigure your router and then refactor your service. This also becomes problematic when you want to break up your service, such as
foo.com/bar/12345/bar2/678
If you wanted to split bar and bar2 into two separate services, you will now need to start parsing your urls on the router level to ensure each service receives the correct parameters. In addition even though bar2 maybe accepting calls at
/
it needs to know the API is expecting it at
/bar/{id}/bar2
Or conversely you have it accept calls at bar/{id}/bar2, either way you have tied your routing to your service or your service to the router. It starts to look more and more monolithic, or even worse you end up with an ESB as the centerpiece of your infrastructure.
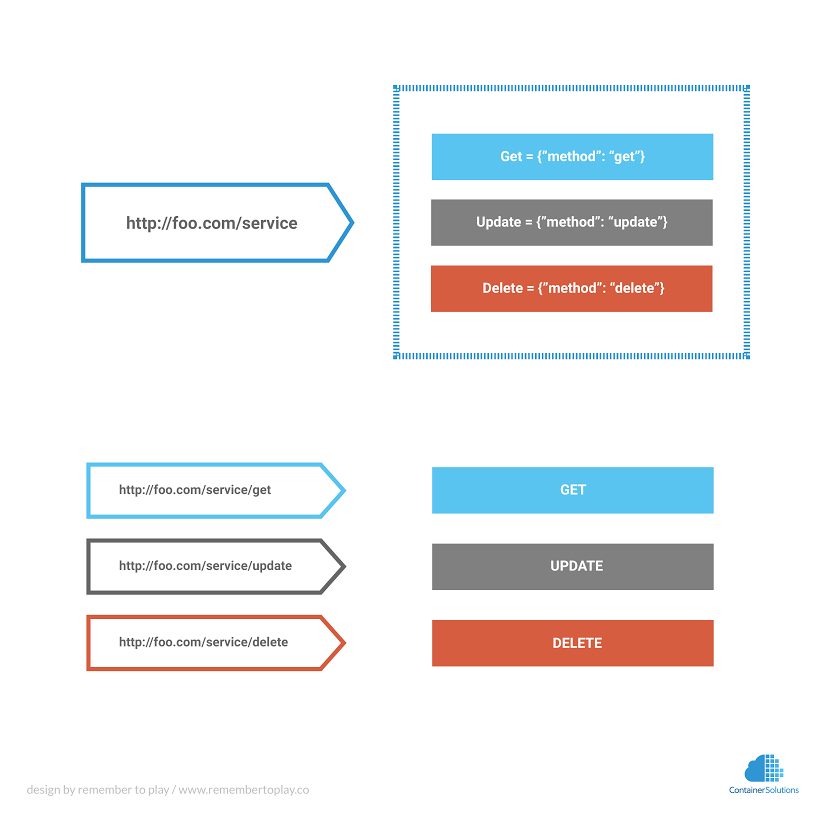
A better option if you were to use http is to map your services directly to endpoints that have no url parameters, so then any URL can become a service and every service serves from
/
HTTP
HTTP is a perfectly fine protocol for communication of microservices in certain scenarios, but tying your system to the protocol as REST is defined is problematic.
Looking at a typical GET request we have this
GET /bar/12345?filter1=value1&filter2=value2 HTTP/1.1 Host: foo.com
Breaking this down we have
A Method on the service
A service
An ID
Random parameters
First and foremost we have to be clear that within your service your Random parameters and your ID, are just parameters on some sort of method. They will be consumed by a “getter” together to determine the return. So internally GET must be somewhere of the form get(id, filter1, filter2), or get(id, arrayOfFilters[]), unless you are invoking globals... Yet we have spread them across several different locations as if they were mutually independent.
To follow, how does this translate to other protocols. What if we want to send this request to an RPC via websockets or gRPC. How do requests interpret? Let’s have a look.
Fortunately someone has already demonstrated how this would have to work.
gRPC gateway is a tool to transform REST to gRPC calls. Let’s look at the graphic they provide.
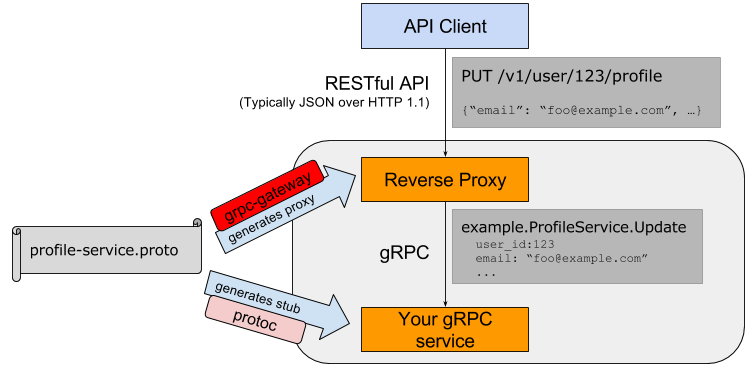
Let’s review what this router has to map.
Method = host/url path + http.Verb
Parameters = maybe url, maybe body, maybe url query…., maybe headers...
As we can see in this example the gateway takes what we already knew to be parameters (id and email) and maps PUT/Profile two different values from two completely different locations in the http request to one endpoint/RPC location that accepts a serialized blob of data. Some people also consider query parameters in the URL for POST/PUT as completely valid RESTful, so we can assume those are more values to be added to a request
As the graphic demonstrates, if we would have passed a serialized request directly in the body of the http request, there would not have to be any transformation, aside from one form of serialization to another.
Now the gRPC gateway was built explicitly to transform REST to gRPC. What happens when we start bringing in open source tools into our infrastructure that do not use gRPC? Or what do you do when your interpretation of proper REST may differ from someone else’s idea of REST? Well you can start hacking away at the router.
Let’s look at an IOT scenario where the client is attached to a Websocket Reverse Proxy in front of RESTful microservices. In this scenario the Websockets have RPCs that are invoked by some device in the cloud (cell phone?). Would the Reverse Proxy have to deserialize each and every request and then assemble each RESTful request for the backend? This seems very costly for a router to perform. Does the RPC respond with HATEAOS links embedded? What would those mean to this Websocket client?
The better answer is routing whole services, with their own method of routing performed internally, based on a method defined in the serialized request, or direct method endpoint mapping like gRPC. Using this model, things become way more portable, and sensible. An HTTP Body is much easier to move between serialization methods than to dissect a full HTTP request.
The Conclusion
Making a system based on microservices, one where you can move your parts around, fail, try again and redeploy and reconfigure, requires a different approach. We need to build applications that make no assumptions about where they will reside at any point within the infrastructure.
With the multiple methods for synchronous and asynchronous communication, and ephemerality of services, we need to abandon a paradigm built on old assumptions of a purely request response paradigm.
If we do not we will develop heavy coupling, and even though our microservices are mutually independent, they will be so tied to each other we will undermine the benefits of a microservice architecture. Which in turn will lead to frustration over the complexity microservices bring while seeing little of the benefit.
A microservice architecture already brings it’s own level of complexity, it does not need yet another level, that also enforces heavy coupling. REST is good for many things but a microservice infrastructure is not one of those.