
Agility is usually defined as the ability to ‘respond to change’. So it's worth looking at where the change drivers are in the value chain of the software delivery lifecycle:
This over-simplified picture shows product managers coming up with ideas, that then go through a design and development phase and are finally delivered to be enjoyed by end users.
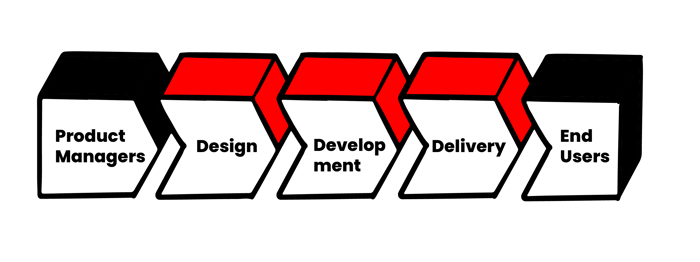
During the inception of Agile in the ‘90s, change was driven mainly from the left side of the value chain as input from product managers, or other business stakeholders, inside the company.
Delivery cycles were long: in the case of ‘shrink-wrap software’, sometimes even years for a new version of an office suite. While end-user feedback would be incorporated into the next major version, it was usually indirect, filtered and translated by business stakeholders.
Early Agile
Agile methods tried to maximise the value that could be created in such multi-month projects during the design and development phases. They achieved this by subdividing projects into smaller cycles, and having cross-functional teams of business representatives, developers, testers and designers working together on a daily basis.
Agile eliminated the need for large-scale, up-front design and requirements gathering. Business stakeholders could validate the progress every few weeks, allowing frequent course corrections by adding new, removing existing, and re-prioritising features and tweaking their designs.
The delivery phase—or, quite literally, ‘shipping’ the software—was not yet a major bottleneck; collaboration during development was. Software delivery and operations functions were therefore often externalised, as these were not regarded as core skills of the business.
DevOps
The advent of e-commerce, the social web, and also the app economy started to change this picture. The interaction of end users with the software started to have a more direct effect on the value chain: be it through reviews in app stores, or real-time analytics that teams started to employ to analyse how their software was used. Whereas, in the old days, companies could mandate how their product should be used (‘best viewed with Netscape 4 on 1024x768’), new usage patterns and new devices now needed to be addressed every few weeks—or customers went elsewhere.
The direct change drivers were slowly shifting towards the right-hand side of the value chain, to the end user.
The delivery phase now became the bottleneck. While well-honed Agile development practices would ensure that these new and more frequent change drivers could be translated into software, the delivery practices were not designed for that increased change cadence—especially if they involved additions or changes to IT infrastructure. The term ‘potentially shippable product’, often used in Agile frameworks, did not consider infrastructure as part of the product.
IT organisations responded to this trend by re-integrating operations functions into product teams. This became commonly known as ‘DevOps’ and meant a reorganisation for most companies. Large companies are often still in the process of reversing some of the externalisation efforts that made so much sense in the 2000s.
A central theme in Agile implementations is breaking down silos between specialist groups like business analysts/subject matter experts, architects, designers, back- and front-end developers, etc., and instead forming cross-functional teams that can take full ownership of their product.
DevOps was the missing piece that enabled teams to take responsibility for the whole lifecycle of their product—from design to delivery. This finally allowed teams to work like mini-startups within an organisation.
The Limits of DevOps
A core tenet of Agile teams is their cross-functionality. This is not the same as a team containing a broad range of dedicated specialists. Instead, Agile teams value members with so-called T-shaped skill sets, i.e., deep knowledge in one (or a few) specific fields and general understanding of many others.
Acquiring generalist skills in all the areas commonly needed in an Agile team is already challenging for employees. If you were a developer, ‘early Agile’ mostly required you to learn additionally about testing. Later, UX was added: front-end and back-end development had become separate disciplines due to increased complexity. Then mobile platforms came and new data stores appeared, displacing classic DBA roles. Add to that the required domain knowledge about the product itself, and the mental capacity to maintain any specialist knowledge (the pillar of your ‘T’) becomes quite limited.
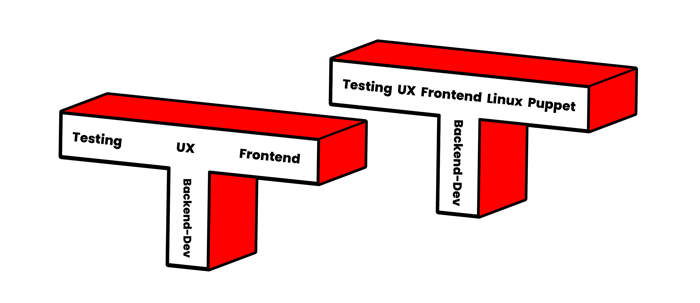
DevOps upped that game once again. IT operations and system engineering is a very broad field, and in many ways quite different from software development. Teaching developers the intricacies of the Linux kernel, firewalls, and load-balancers often proved challenging. Especially as mistakes made to production systems could easily be fatal, whereas a badly designed unit test or a botched stylesheet usually doesn’t have an irreversible and immediate impact.
That often led to the very bad pattern of having one poor person on the team to be ‘the Ops guy/gal’, often a former sysadmin of the former ops organisation. He/she would do all the deployments, patching all the servers and configuring all the networking gear. A guaranteed road to frustration and burnout, and a great risk for the team if that person left (‘the bus factor’, as in, ‘What will we do if so-and-so gets hit by a bus?’).
Automation
Advanced teams therefore invested in automation, especially in configuration management (CM) tools like Ansible, Chef, or Puppet. Expressing infrastructure with code allowed for common ground between Dev- and Ops-minded team members. Their abstractions also allowed less Oops-savvy developers to implement infrastructure changes. Specialised testing frameworks even allowed us to employ a modern development cycle with continuous integration of configuration changes for servers.
But CM tools also came with challenges: feedback cycles for tests were often frustratingly slow, as complete virtual machines had to be provisioned to test each change, and changes often involved downloading and installing large software packages. Abstractions were sometimes leaky, and without knowing how the CM system implemented them, could lead to unexpected results.
Idempotence was another big problem: ensuring that applying the same tool repeatedly would not lead to different outcomes, or that updated versions of other parts of the infrastructure would not break the tools, became more difficult the larger the codebase grew.
Also, aside from configuring machines, the setup and configuration of the rest of the infrastructure, like load balancers, storage systems, and firewalls was still notoriously hard to automate— especially in a safe way with working rollback mechanisms.
Therefore, many teams never ventured beyond the configuration of their servers, leaving the rest of the infrastructure to expert teams or outsourcing partners, resulting in slow, manual, and frictious interactions with those groups through email or ticketing systems.
Unfortunately, an increasing number of changes required broader capabilities to manipulate infrastructure from within the team:
- Running multiple versions of your product for A/B testing often required changes to the load balancer.
- Setting up a new testing environment for a new feature required the ability to launch machines and configure network devices and firewalls.
- The incorporation of a new database technology or new search engine required working with storage systems.
This whole problem was magnified by the trend to break down large software products into smaller services, to be able to give individual teams full responsibility over a set of services that they could evolve on their own (‘microservices’).
From PaaS to Containers
These problems were recognised by early Platform-as-a-Service (PaaS) providers, the first one being Heroku. The result were platforms, where code written for popular programming languages and frameworks would run without complex system-level configuration. Conventions would make sure load balancers were configured and updated automatically, and instances that needed to be replaced because of maintenance of the underlying servers would be restarted elsewhere without user intervention
But applications had to adhere to certain conventions to function properly—popularised as ‘12 Factor Applications’. The most restrictive properties were statelessness and disposability of individual application instances. Also, testing of applications that consisted of multiple services proved challenging: early PaaS were either too heavyweight or not available for developer workstations, requiring a round trip to the cloud for each testing cycle, or other workarounds.
Together with being restricted to certain programming frameworks, this made PaaS mostly suitable for greenfield development, as porting existing projects or legacy software onto the PaaS model could be prohibitively complex.
Going Cloud Native
However, the core concepts around PaaS, especially containerisation and orchestration, were sound. So when Docker and Kubernetes arrived, their value was immediately obvious and a rapid adoption of these tools happened and a new industry grew around them.
Containers proved useful beyond delivery and operation of software: testing and development cycles benefited greatly from the easy way to package, share and run applications with all their dependencies.
Another great property of containers was that it demarcated the—until now—blurry line between infrastructure operation and application management. Infrastructure teams would now manage everything up to the container daemon, and product teams could concentrate on what was running inside the containers.
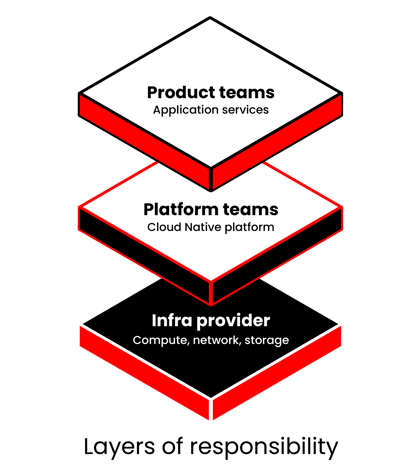
Combined with orchestration and observability of the Cloud Native toolbelt, and the architectural principles that evolved from the original 12-Factor App, this finally resulted in the right level of abstraction to give Agile teams complete autonomy.
With the addition of Cloud Native, developers can use familiar APIs to safely manipulate all aspects of their applications environment, including the commissioning and decommissioning of resources for A/B tests or new testing environments, as well as load-balancing or security settings.
Frictionless deployments, rollbacks, failure-handling, central debug logs and application traces, as well as easily correlated business- and system-level metrics, are all core concepts of a Cloud Native platform and don’t need to be reinvented by every team.
Finally, one team can focus on efficiently operating the platform, which product teams then run their application services on. This allows for clear separation of responsibilities and a continual improvement of the platform, benefitting all teams equally, and even makes it possible to introduce Cloud Native operations following SRE (Site Reliability Engineering) principles; being data driven with clearly defined SLOs (service-level objectives) and error budgets linked to business objectives, and balancing the need for new features against overall system health.
In conversations between the SREs and the product owner or product manager, a decision shouldn’t be about the SLO and the nines provided—the decision should be about the error budget. It is more about what to do with the budget and how it can be best used.
Ideally, the error budget should be used for innovation and testing new ideas, which often have an impact on availability and reliability. It can also be used to increase velocity. In traditional organisations, there is no way to just release something to see what happens -. There are a lot of gates and processes that will hold the team back from innovating whilst still keeping its promises. Typically operations engineers are resistant to changes, as most outages are caused by changes, such as software releases.
The point is that with SRE, the error budget guides the decision. When there is a budget available, the product developers can take more risks, and are even encouraged to do so. When the budget is almost exhausted, the product developers themselves will push for more testing or slower push velocity, as they don’t want to risk using up the budget.
Related Cloud Native Patterns
Balance proficiency and innovation by building a separate time for each into your development cycle.
Build-Run Teams (Cloud Native DevOps)
Dev teams have full authority over the services they build, not only creating but also deploying and supporting them.
The SRE (Site Reliability Engineering) team helps the development teams to maintain and improve the application (not the platform or infrastructure)
More Cloud Native patterns can be found here.
