
The move from monolithic architectures to microservices requires communication between the different services that make up applications. Service instances are typically processes that need to communicate with each other somehow, and this is where inter-process communication (IPC)— sometimes called inter-service communication (ISC)—comes in.
The IPC mechanism that tends to come to mind is RESTful APIs, as this is still the most widely used, but other options have emerged that might be a better fit for specific use cases. In this article, along with REST we consider three other popular choices: GraphQL, gRPC, and Messaging. But, to set the scene, when figuring out which communication type might be best for you, there are a few categories to consider.
Synchronous or asynchronous
Synchronous communication means that the microservice or client is blocked while waiting for the response to a request, whereas asynchronous communication is able to continue before receiving a response (which might come later or never).
Point-to-point or multipoint
Are the services going to communicate 1:1 (known as point-to-point), where each request is processed by one other service? Then the options are to go for synchronous request/response communication or just simple asynchronous one-way notifications.
If requests are meant to reach multiple other services (1:n, aka multipoint), asynchronous publish/subscribe interactions are better. These are often implemented using message brokers: that way a request still only needs to be sent once to be processed by multiple services. Popular open-source broker options include RabbitMQ and Apache Kafka, whilst the major vendor offerings include IBM’s venerable MQ, originally launched in 1993, and TIBCO’s JMS-based Enterprise Message Service.
Message formats
If the data being sent will be examined by people, you might want to choose a message format they can read (like JSON or XML). Otherwise, a binary format (like protocol buffers or Apache Avro) is more efficient.
The role of APIs
APIs generally act as contracts between services, or between services and clients. For communication between internal microservices the recommendation is often not to use synchronous (and therefore blocking) protocols, but these are still the norm for public- or client-facing APIs.
Depending on the architecture and the intended interaction between microservices, different mechanisms are available. Looking at the options for inter-process communication, each comes with its own set of pros and cons, and has different optimal use cases. Here are some examples of IPC options in a microservices architecture.
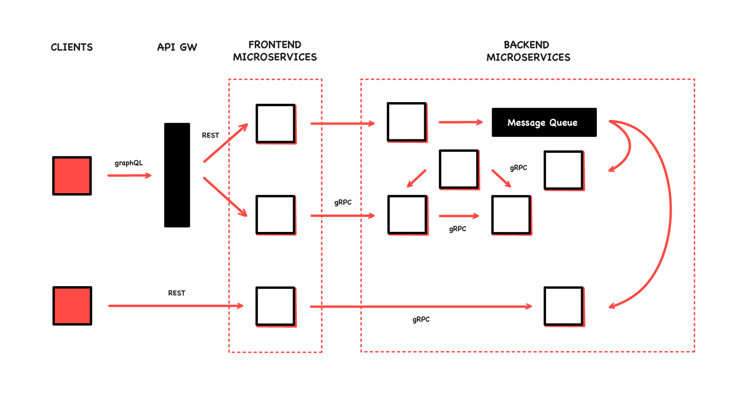
REST
RESTful APIs are the de facto industry standard of communicating with services. They are defined by three parts: a URI, standard HTTP methods like GET and PUT, and a media type. Data is represented in resources—for example, a customer or another business object.
Using REST has a few advantages:
- Simple interfaces, easy to get started
- Well known and mature
- Firewall friendly (as it is using the HTTP/S ports)
- Testing with a browser or simple curl commands
There are a few drawbacks as well:
- Usually synchronous request/response interactions
→ Alternative: messaging - URIs must be known by clients—requires service discovery
- Endpoints are defined by resources, making it difficult to get data from multiple resources in one request, which can result in requests like:
GET /customers/customer_id?expand=orderswhen trying to get both a customer and an order resource.
→ Alternative: GraphQL - Reliance on HTTP verbs leads to more complicated URI endpoint structures (for example, an update request is difficult to map to PUT, when an update is not idempotent)
→ Alternative: gRPC - No intermediate buffer, so both the requesting and responding services need to be running during the exchange
(If you are viewing this blog post on mobile, you can download a PDF of the following table for easier reading.)

GraphQL
Unlike REST, GraphQL queries define exactly what data they want and receive only that.
They don’t just target one resource per request, but follow references between them to allow for faster data retrieval with a single request. This is done by working with types and fields instead of multiple resource endpoints.
GraphQL was originally invented and used by Facebook in 2012, before becoming open source in 2015. Similar projects co-evolved at around the same time, including Netflix’s Falcor, but did not see as much adoption, and Netflix itself has started to shift towards GraphQL. Other large companies that have adopted GraphQL include Airbnb, Coursera, and GitHub. GraphQL works over HTTP but, like REST, can also be used with other protocols, including RSocket.
When using HTTP you can use a variety of tools to query a GraphQL API, for example:
curl -X POST \
-H "Content-Type: application/json" \
--data ‘{ “query”: “ { hero { name friends { name } } }” }’ \
<GraphQL endpoint>
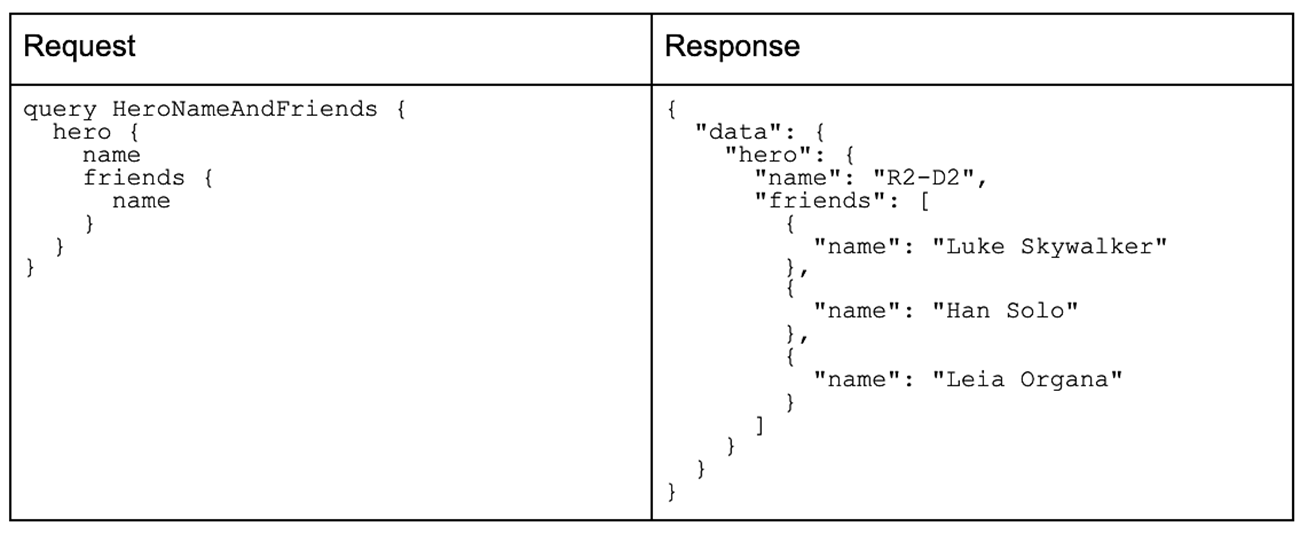
(If you are viewing this blog post on mobile, you can download a PDF of the above table for easier reading.)
GraphQL reduces request complexity by needing fewer requests than REST and transmitting only the requested data without other fields. It also uses a single endpoint, so service discovery isn’t necessary. If a single graph becomes overly complex and monolithic, it is possible to divide the graph's implementation across multiple composable services with Apollo Federation.
Multiple sources can be aggregated into one, acting as a consumer-driven API gateway to either add functionality or hide complexity from the consumer.
GraphQL provides an alternative to the difficulties of API versioning by adding or deprecating fields, but that comes with its own set challenges. Netflix has a whole schema working group and a data architect overseeing any changes to the graph.
The Query Language structure causes some issues as well. For example, caching is more effective with REST, error handling and GraphQL specific resources add more complexity, and rate limiting is harder to implement. Some of what GraphQL does can also be done by REST with some additional work using fields and libraries.
Typical use cases for GraphQL are architectures with very low bandwidth or the need for fast and precise responses—enabled by receiving only the data requested. Another good reason to go for GraphQL is when you need to combine multiple data sources, such as other API endpoints and databases. However it doesn’t solve performance issues with cross-region calls.
gRPC
gRPC is an open-source, high-performance Remote Procedure Call (RPC) framework initially developed at Google in 2015, and is widely used with microservice infrastructures. It uses the HTTP/2 Application Protocol for transport, and is up to 25 times more performant than REST.
You get four types of APIs with gRPC:
- Unary (similar to the REST Request and Response approach)
- Server streaming
- Client streaming
- Bi-directional streaming
On HTTP/1.1, every request you make opens a new TCP connection. What HTTP/2 allows with multiplexing is the ability to make multiple requests over the same TCP connection. gRPC takes full advantage of this. It offers a lower resource consumption communication solution across your systems. Other highlights of HTTP/2 features that gRPC leverages: server push, header compression, and binary data format.
The data gRPC sends in requests is converted to binary. It results in smaller sized data being sent between your microservices. Machines can understand binary, and therefore it is less costly (resource wise) to work with at the machine level.
In common with REST and GraphQL, gRPC is language agnostic: a Java microservice can communicate with a Python microservice, which can then communicate with a Go microservice, which can communicate with a Node.js microservice, etc.
gRPC uses protocol buffers to encode the data. Protocol buffers address changing data structures on large scaling systems. As more and more microservices get added to a system, the data will evolve and some systems could become unmaintained. Protocol buffers offer reliability to the data structures used across evolving microservice-style architectures.
Protocol buffers are also strongly typed, which leads to a more consistent interface for the data. Protocol buffers aim to help with both forwards and backwards compatibility. Services can define how they want to receive data and what format, and services who want to engage with that service have to stick to the required format.
Pros and Cons
Advantages of using gRPC APIs:
- Language agnostic: you can write a gRPC API in almost any popular language used for creating microservices.
- Uses protocol buffers and serialises data into binary data, so data being transferred across networks is smaller (in comparison to text based message systems.
- Strongly typed data structures, leading to more stable communication structures between the services.
- Aims to help with both forward and backward compatibility of its implementation in services.
Drawbacks of using gRPC:
- Learning curve can be steep. You need to learn about protocol buffers and gRPC.
- Because all the data is converted into binary format, it can be more difficult to debug.
- You have to use generators to generate your gRPC code.
An example of Unary (Request and Response) gRPC API
Protocol Buffer example:
syntax = "proto3";
package heroes;
option go_package="./heroes/heroespb";
message Friend {
string name = 1;
}
message Hero {
string name = 1;
repeated Friend friends = 2;
}
message HeroRequest {
}
message HeroResponse {
Hero hero = 1;
}
service HeroService{
rpc Hero(HeroRequest) returns (HeroResponse) {};
}
Server example in Go:
package mainimport ("context""fmt""log""net""github.com/cariza/grpc-example/heroes/heroespb""google.golang.org/grpc")type server struct {}func (*server) Hero(ctx context.Context, req *heroespb.HeroRequest) (*heroespb.HeroResponse, error) {fmt.Printf("Requesting hero data")res := &heroespb.HeroResponse{Hero: &heroespb.Hero{Name: "R2-D2",Friends: []*heroespb.Friend{{Name: "Luke Skywalker"},{Name: "Han Solo"},{Name: "Leia Organa"},},},}return res, nil}func main() {lis, err := net.Listen("tcp", "0.0.0.0:50051")if err != nil {log.Fatalf("Failed to listen: %v", err)}s := grpc.NewServer()heroespb.RegisterHeroServiceServer(s, &server{})if err := s.Serve(lis); err != nil {log.Fatalf("Failed to server: %v", err)}}
Client example in Go:
package main
import (
"context"
"log"
"github.com/cariza/grpc-example/heroes/heroespb"
"google.golang.org/grpc"
)
func main() {
cc, err := grpc.Dial("localhost:50051", grpc.WithInsecure())
if err != nil {
log.Fatalf("Could not connect: %v", err)
}
defer cc.Close()
c := heroespb.NewHeroServiceClient(cc)
doUnary(c)
}
func doUnary(c heroespb.HeroServiceClient) {
req := &heroespb.HeroRequest{}
res, err := c.Hero(context.Background(), req)
if err != nil {
log.Fatalf("Error while calling Greet RPC: %v", err)
}
log.Printf("Response from Greet: %v", res.Hero)
}
(If you are viewing this blog post on mobile, you can download a PDF of the following table for easier reading.)

Messaging
REST and RPC are not great with large amounts of data and high throughput, which is where messaging comes in.
Services communicating via asynchronous messages often use a message broker internally, such as RabbitMQ or Apache Kafka. Brokers allow for looser coupling between services and message buffering but they can also act as a performance bottleneck and single point of failure.
The use of multiple queues and sharding can help avoid that.
The alternative is brokerless communication (like ZeroMQ), where each service talks to the others directly. While not having to manage a broker is simpler, brokerless requires both services to be available at the same time and have a kind of service discovery mechanism (as the services are not talking to the single point a broker provides).
Messages can be just text, commands to other services, or events. Depending on the microservices, these are instructions on how a service should react.
Apache Kafka is a streaming platform intended for large amounts of data and high throughput, while storing messages for an extended period of time. This is great for re-sending events or analysing streaming, both historical or real time, and also is a good option when data needs to be kept for auditing purposes.
The original use case was for tracking website activity such as page views, searches, uploads or other user interactions. Apache Kafka only supports 1:n communication, but that can be adapted to 1:1 by having only one service subscribe to a topic (equivalent to parts of a message queue).
RabbitMQ is an open-source message broker that works with different protocols like AMQP, MQTT or STOMP to provide a simple way of creating queues for sending and receiving messages.
RabbitMQ is easily usable with different programming languages—for example, Java and many other JVM languages, .NET, Ruby, Python, JavaScript/Node.js, Swift, and Rust.
After starting a RabbitMQ server these snippets of code in Python let you send a message from one process to another:
send.py
#!/usr/bin/env python3
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost"))
channel = connection.channel()
channel.queue_declare(queue="hello")
channel.basic_publish(exchange="", routing_key="hello", body="Hello World!")
print(" [x] Sent 'Hello World!'")
connection.close()receive.py
#!/usr/bin/env python3
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost"))
channel = connection.channel()
channel.queue_declare(queue="hello")
print(" [*] Waiting for messages. To exit press Ctrl+C")
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(queue="hello", on_message_callback=callback)
channel.start_consuming()Other than simple 1:1 queues where one producer service passes a message through a queue to a consumer service, RabbitMQ also supports more advanced patterns including complex RPC emulation or topics, where messages are received based on patterns.These patterns make RabbitMQ especially appropriate for more complex routing use cases, which Kafka doesn’t give you without additional work. Often messaging is seen as a “fire and forget” type of communication, but in use cases where you need replies or acknowledgement you will most likely need to add custom logic to deal with that, making it more complex.
Common use cases are order handling in web shops, or just simple communication where message order and retention are not important. RabbitMQ also allows for message prioritisation via specific queues, while Kafka events arrive in the order they were received.
Conclusion
Which IPC is right for a specific group of microservices depends on how the services need to interact, what kind of messages are being transmitted, how large they are and, of course, which SDKs are supported by the languages used in those microservices.
The choice of communication type between public facing services and internal ones often comes down to usability versus speed. Another factor is the learning curve; sometimes in the interest of time it works out better to start with what everyone on the team is comfortable with. Message brokers are better for broadcasting or persisting messages.
Each of the mechanisms discussed in this article has strengths that can be at least partially emulated by the others, but perform best for their own use cases.
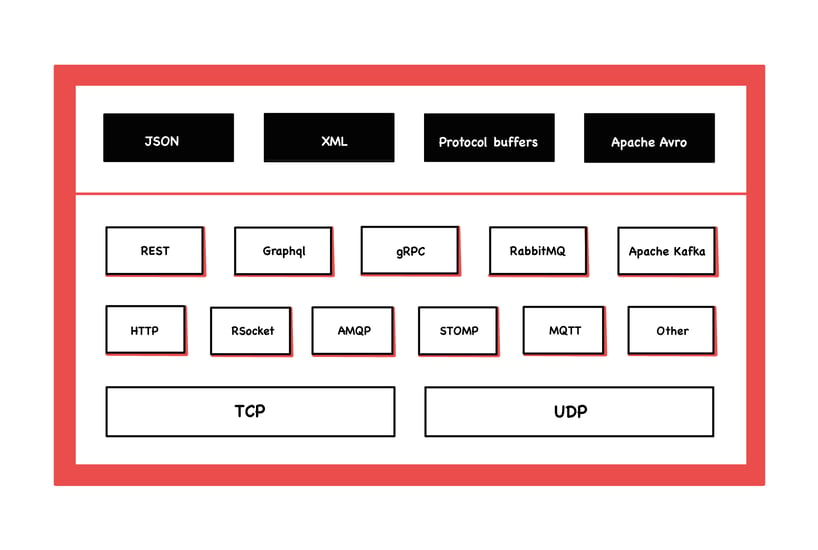
The first row shows different serialisation formats for messages, from human readable to binary. The lower rows show which communication types there are and what application and transport protocols they are based on.
Choosing the right IPC for a given architecture is not trivial. Hopefully you now have a better understanding of when to use which one.
