

Those of us who make a living producing software or managing software teams are ultimately getting paid to improve business processes, be it making cars autonomous to improve safety, save people time driving and reduce costs; optimising industrial processes for higher production rates; or automating manual tasks.
Most of us do this by writing “classical” programs that solve problems in a highly traceable manner, but even these can become very complex very quickly. Just think back to all the software projects you were part of that went over the originally allocated time or, even worse, got completely cancelled as their complexity no longer justified the benefit they would have brought. Over time we have added a lot of different methodologies atop the development process, as Container Solutions co-founder Jamie Dobson explores elsewhere on WTF, some with more and some with less success. “DevOps”, a central part of Cloud Native culture, is one of them, focussing particularly on continuous delivery and high code quality via shorter feedback loops.
As if this isn’t complex enough, let’s add another layer of complexity: machine learning systems rely on code that is stochastically extracting information from the data it is fed with, making the decision making process effectively untraceable.
To begin with, you need to generate a labeled dataset. Additionally, you need to gather a lot more compute resources and make them accessible to your data scientists. Then you report your results on the test dataset and, all being well, people want it brought into production.
Now your problems really start, as it turns out the actual AI code is often the smallest part of the whole project. You need to expand your already complex DevOps pipeline to ship not only code but also stochastic black boxes. In this process however, you also need to have some guarantees and auditability on what the black boxes and the code are doing - or at least be able to stop them early when issues occur or rollback to an older, stable version of the model. At this point you will be at roughly the same point Google was when they wrote their infamous paper “Hidden Technical Debt in Machine Learning Systems”.
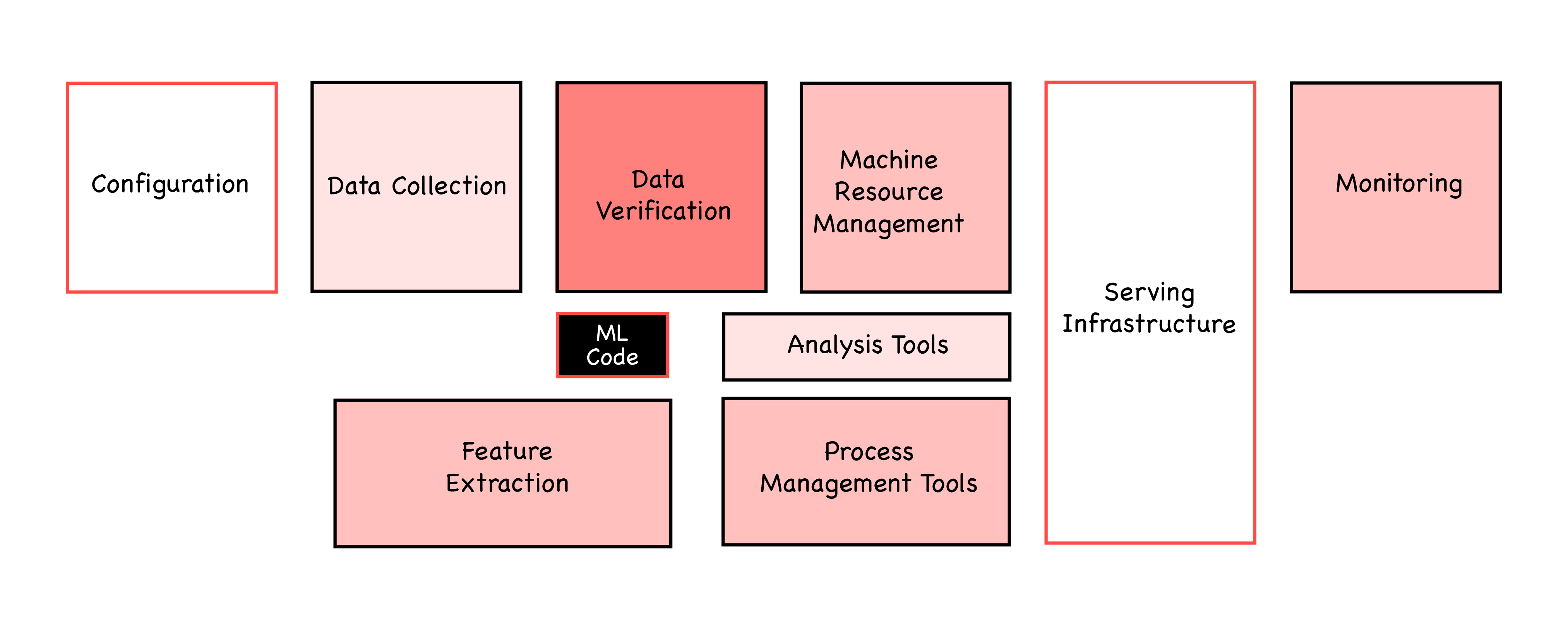
- Versioning and searchability of data
- Testing, reusing and versioning of models
- Service Level Indicators (SLIs) for model predictions and inflowing data
- The ability to visualise impact
Versioning and searchability of data
All our AI models derive business logic from data. Every project starts with a request like: “Can you predict our power consumption? It would significantly reduce costs. If this is the first time anyone has looked at power consumption you will now start talking to all of the relevant people in your company trying to find out what influences it. This gets very intractable very quickly, so it is a good habit to document available datasets, tag them, and make them searchable. The next person doing anything remotely related to company power consumption will thank you.
When we have beautifully sorted data, we face our next obstacle. Two models trained on different datasets will rarely yield the same results given the same inputs, so the results of different models always need to be compared using the same dataset. Just imagine one of your data scientists appearing on your doorstep saying: “I achieved 99% accuracy on the MNIST dataset and person B only 90% on the CIFAR-10 dataset. My model is way better.” You would certainly question this statement even though it could potentially be right. If we documented our own datasets well enough this should not arise.
The example above is straightforward since we have two completely different datasets with different targets, but the same problem occurs for datasets with different versions, such as the PASCAL VOC dataset. If a model reaches a high accuracy on VOC 2007, it is a good indicator that it will also do so on the 2012 version, but there is no guarantee.
Because of this, it is imperative that we version our datasets and keep track of the version used for each particular training. This becomes even more important if your model continuously serves requests and receives ground truths for them. Let’s consider the following example: You deploy a model to detect whether an image contains a cat or a dog and have a button to let the user indicate if the model was right or not. After a while you want to retrain your model with the newly annotated data. If you just take your new data and do a random train test split, your test set would be different from the previous training run making your results not comparable. It would instead be better to just add the new examples to your training data and use the same test set. This way you can validate if the model gets better with the new data, or if people just got up to some shenanigans and misannotated your data.
Testing, reusing and versioning of models
Code reuse via common functions and libraries is a standard part of every software developer's toolkit, which ties very much into the DevOps practice of testing and DRY (don’t repeat yourself).
The picture is less good for AI though. As an example consider the data transforms we use all the time, such as returning the day of the week for a given date.
It would be great if we didn’t all need to write our own functions for these sorts of things. We are getting better at this in the AI field. In particular scikit-learn and its transformer-based API have helped a lot when it comes to tabular data. You should support a similar approach when transforming data within your company. You don’t want your data scientists spending time rewriting code that already exists. An important beneficial side effect of this is that you are using code that has already been properly tested: nobody likes to spend time debugging other people's code. Additionally, having test cases documents how the individual transformer should be used and what kind of cases it can actually tackle.
However, this is just one example of DRY in AI. We’re also seeing the growing availability and use of pre-trained models elsewhere, such as Apple’s Core ML, translation services from DeepL and Google, and captioning services for videos.
Additionally, more and more models use transfer learning heavily, allowing them to take trained pieces from a different neural network and reuse them. This started with ImageNet in image recognition and expanded to Natural Language Processing (NLP), first with word embeddings and nowadays with models like BERT and all its successors. A great example is the hugging face library which allows you to reuse parts of pre-trained NLP models in your own.
However, using parts of models requires even more faith in other people’s effort than reusing transformers. You don’t only assume that the provided code works, but also that the model was trained in a sensible manner and that the API always returns you the same model. Also remember that you are reusing some values from neurons in the middle of someone else’s neural network and feeding this into your own. The other person does not care that you do so, rather like using a private property of a class. It is there and you can use it... but it might change completely, as the developer only guarantees you the public API.
Let’s elaborate on this. Word embeddings can be trained by predicting the words around them. An example of this can be seen in the upper left figure. This will yield two things: an overall accuracy in predicting words, and embeddings (figure at the top left) that will be close for related words.
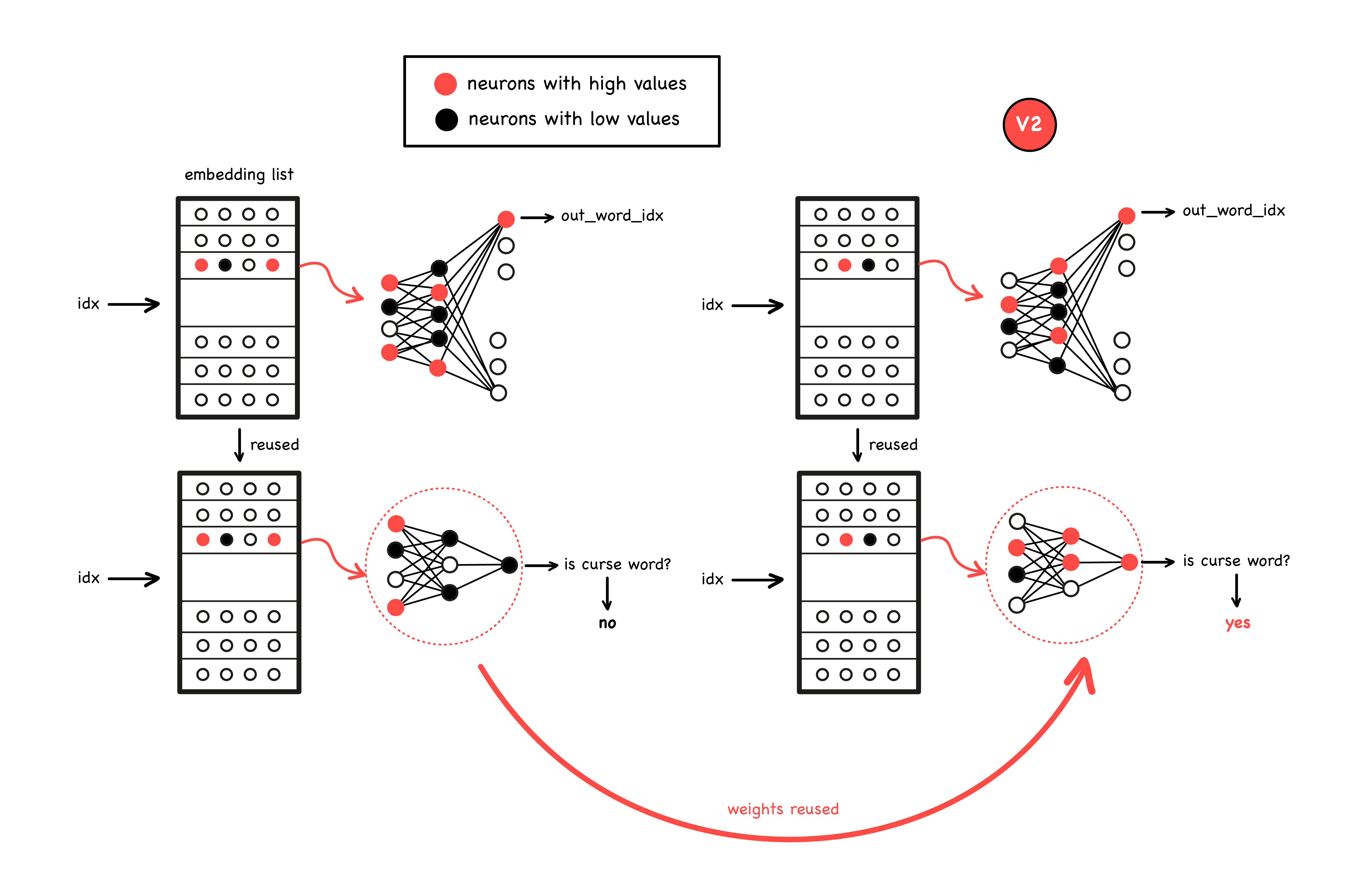
You can take these embeddings and use them for another task e.g. to predict whether a word is curse word or not (figure at the bottom left). Your model will greatly benefit from the embeddings as curse words will probably have embeddings that are close to each other. Now imagine someone trains new word embeddings: curse words are still likely to be close together, but the dimensions can easily be shuffled and the values can vary a lot as well (figure top right). As an example, have a look at the figure below. It plots the first 20 dimensions of the word vectors for “WTF” in two versions 3.1.1 and 2.3.7. Just by eye-balling it you can see that they are very different.
This is why you need to ensure you get the same model version every time: your model would otherwise give wrong predictions if its weights are frozen (figure bottom right). This is one reason why you should version your models, but there is another one. If you develop a new model and deploy it into production, and then realise it handles edge cases way worse than the previous one or takes too long to reply to requests, you’ll want to revert to the previous one. But obviously in order to do that you need to have it somewhere and be able to easily identify it.
SLIs for model predictions and the inflowing data
Similar to normal DevOps procedures, we should monitor our models in production. They will fail eventually and if that happens we want to be alerted. Therefore, we should define Service Level Indicators and alerting rules for when these are not met. As in DevOps, monitoring response times is essential to guarantee a good customer experience, but ML models have some additional pitfalls.
As discussed in Google’s article about testing ML in production, we need to keep track of schema and feature skew, and also model aging:
Schema skew refers to your schema changing between training and serving in production. The easiest example is that your training data had four columns, but in production only three are handed to the model. This will certainly lead to issues in your predictions.
Feature skew occurs when features are differently engineered in production vs training. Let’s look at an example for this: Your model needs the number of customers in the last 24 hours. In the training database the number of customers is aggregated by customers per hour. In production this could simply be an array, where entries are dropped whenever the record is 24 hours old. Building the sum over both will yield different results as the sum in the training database will drop all customers from an hour at once, while in production they will be dropped more gradually. This can again yield different predictions from your model.
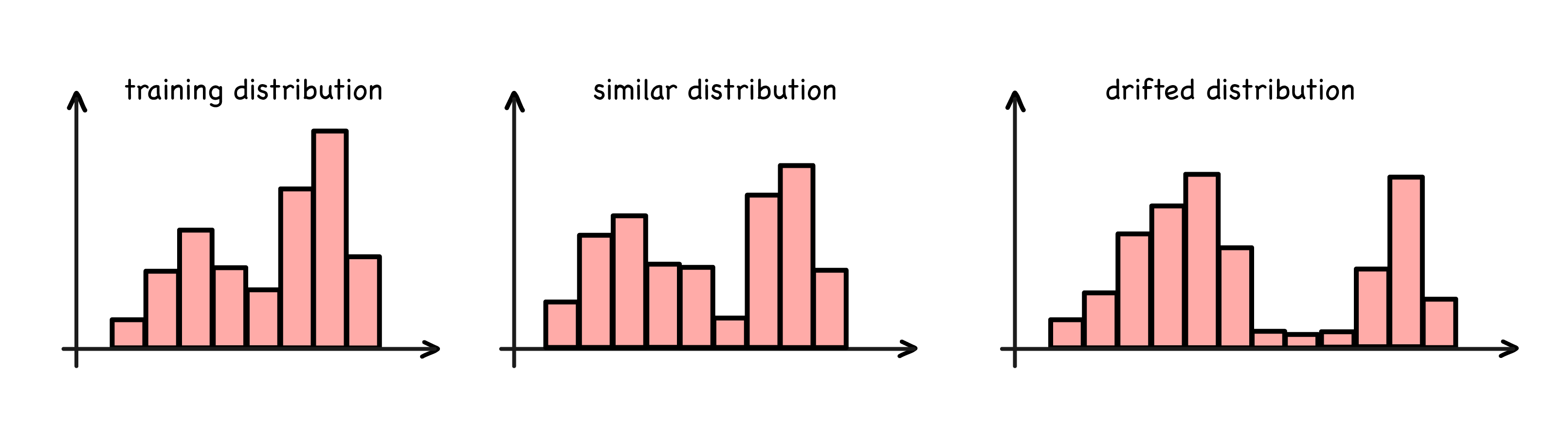
Finally we need to accept that our model is aging. Most of our input data is produced by humans and their behaviour changes over time. As the model can only capture the behaviour available in its training data, this needs to be updated or the model’s predictions and the actual outcome will deviate further over time. Just imagine you trained a model that predicted the consumption of facial masks in November 2019. Its predictions would probably not be accurate for long, even though it did not break. It simply cannot predict the rise in consumption given its training data. Techniques that can help detect such issues are drift detection (see figure below) and outlier detection, such as those provided by Seldon Core, and open source alternatives.
Visualising Impact
With nearly every software product comes a front end of some kind to visualise its impact. After all, the impact is what your customer is paying for. Given traditional software this can already be a complex task. However, with an AI you get an additional point you need to explain: false predictions. As an AI is probabilistic, it will make mistakes. Sometimes you can argue that a mistake can be fixed by retraining the model. You can do this once or twice, but then people start questioning whether an AI is really the way to go, given the number of mistakes it makes.
To avoid this, it is important to set expectations early enough so customers understand that errors will occur and what kind of benefit they will get in exchange. Agree on an acceptable error budget for the application and the expected benefit. Visualise both continuously and you will save yourself from a lot of discussions, as people can easily see what they have gained from using an AI.
Conclusion
To put it in a nutshell, AI is still a comparatively young field and many things programmers in other disciplines take for granted are by no means a given in the field of AI. This includes but is not limited to version control, SLIs and code reuse. However, as AI is being used in more and more production environments the field is catching up to other branches of computer science. I also expect to see a lot of tools that will automate at least parts of AIOps and will eventually lead to low- or no-code solutions that leverage already written transformers and AIs.