
Google is quietly releasing increasing amounts of projects dedicated to data science. One such project that was recently pointed out to me is called Kubeflow. In its essence, it is not terribly complicated. But when considered as part of the adoption of data science (and Google’s strategy), the project is of utmost importance.
Kubeflow is a mashup of Jupyter Hub and Tensorflow. It exposes two components from the Tensorflow ecosystem: Tensorflow on Kubernetes (k8s) and a Tensorflow model server.
Jupyter Hub
Jupyter Hub is a project that provides multi-tenant Jupyter Notebooks. For those that do not know, Jupyter Notebooks have taken the data science world by storm by providing a document-style format that allows you to embed both code and markdown in the same file. But it is not just for data science, it works with many languages. This is useful due to the visibility it provides; developers can observe and tinker with the research and development process. Much like showing your working when doing your maths exam, Jupyter notebooks encourage you to show your assumptions, models and data engineering processes for others to observe and critique.
.gif?width=540&name=Jupyter%20Hub_Example%20(2).gif)
Tensorflow
Tensorflow is a general purpose graph-based computation engine. It abstracts hardware concerns; you use the same code irrespective of whether you are running on a CPU or GPU. And the most common use case is for implementing deep learning models. This is achieved through an application programming interface (API) that has bindings in a range of languages. You would construct your model using the API then execute the model using a Tensorflow session.
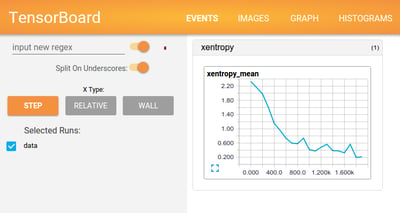 Image 2 - Tensorflow comes with a bundled webapp called Tensorboard. Data Scientists use this to debug their models.
Image 2 - Tensorflow comes with a bundled webapp called Tensorboard. Data Scientists use this to debug their models.
Tensorflow Serving
Once models have been designed and the parameters have been chosen, through a process known as training, the models can be stored then served by Tensorflow. This is part of the core Tensorflow project. Kubeflow provides a Dockerfile that bundles the dependencies for the serving part of Tensorflow. This container will serve your model to clients. It is similar to the Dockerfile example provided by Tensorflow. Note that it doesn't bundle other common Python libraries or other serving mechanisms.
Tensorflow on Kubernetes
Since the serving component is bundled into a container, it is perfectly suited to be deployed on k8s. Indeed, a project already exists called Tensorflow on Kubernetes that does just this. The trickiest part of deploying on k8s is setting up GPU support and architecting batch (i.e. training) and serving jobs. Thankfully Tensorflow on k8s provides us with the k8s manifests that correctly setup GPU support and Kubeflow adds the serving component.
What This Means
When we put all of this together, as Kubeflow has done, we have the ability to deploy both training and deployment jobs to k8s. We also have an environment to perform research and development using Jupyter Notebooks. In short, this allows engineers to investigate, develop, train and deploy deep learning-focused models on a single scalable platform. Best of all, because Kubernetes and Docker abstracts the underlying resources, the same deployment works on your laptop, your on-premise hardware, and your cloud cluster.
Make no mistake, this is remarkable. For decades data scientists have developed their algorithms in complete isolation. They used esoteric, proprietary systems and languages (Matlab, Mathematica, SAS, SPSS, et al.). It was (and still is in many businesses) a wall. This project marks the beginning of the end of the data scientist and/or software engineer as disparate roles. Like DevOps has merged operations and development, DataDevOps will consume data science.
When You Should Not Use Kubeflow
However, a word of warning. Data Science is all about minimalism. Much like software engineering, you do not want to write unnecessary code or produce overly-complex models. This results in higher maintenance costs, more bugs, makes hiring more difficult and promotes overfitting, the scourge of production data science.
Because Tensorflow is inherently complex - it has new APIs, new theoretical requirements, new data science requirements (i.e. deep learning) - it is probably overkill for your project. You can usually get away with much simpler models using standard tools and libraries. But the Kubeflow project has a goal to support many different ML frameworks (Scikit Learn, XGBoost, Pytorch and CNTK already have issues in their backlog), so hopefully we will be able to use simpler models soon.
Four Questions to Check If You Are Ready for Kubeflow
So, if you are thinking about using Kubeflow or Tensorflow in your project ask yourself the following questions:
- I have lots of data (i.e. greater than tens of thousands of labelled examples, preferably millions).
- Our engineers are trained in data science and have experience developing complex deep learning models.
- We know we could achieve better performance if we had a more complex model.
- We are proficient using Kubernetes.
If you answer is no to any of those questions, then I would recommend delaying the introduction of Tensorflow on k8s. First, ask us for help. Our training fixes the knowledge-based limitations. Second, you might need to spend time and money investing in data. And finally, we are here to help. We have implemented complex k8s-based data science systems for a number of clients. Get in touch.