

In the announcement video, Adam Jacobs, the CTO and co-founder of Chef, claims that for companies who want to move towards a devops organization, everything depends on how people in an organization work together, and how their tools enable them to have an efficient build, deploy and manage process. If the tools are insufficient, your tech stack will fight you and devops will be just a nice idea that you can’t execute. Our CEO, Jamie Dobson, calls poor infrastructure the "dark centre" that kills an organization's ability to think and act strategically, and spoke about this at GOTO Stockholm this year.
Habitat is Chef’s new solution for building, deploying and managing applications in a production environment. The main goal is to allow users to get applications to production as fast as possible, for which they have taken inspiration from how the big “web companies”, like Google and Facebook, run their apps. However, these companies have full control over what they’re running, whilst most enterprise companies have a variety of services and applications running bought from different vendors, that have each different requirements on their environments. Therefore, Habitat also has support to wrap around these legacy applications, whilst still allowing these legacy apps to be managed by Habitat.
Habitat consists of the following logical components:
- Habitat Studio: Builder of packages
- Depot: Storage of packages
- Supervisor: Runtime support for applications
At Container Solutions, we have in depth knowledge of Docker, ContainerPilot, an implementation of the AutoPilot pattern by Joyent and Nix. It appears that Habitat is a mix of these three technologies.
Habitat Studio
Habitat’s build system is inspired by Nix. It even uses the PatchELF utility that has been created for Nix. Habitat allows you to explicitly specify your build dependencies, like the GCC compiler, and runtime dependencies, such as glibc or a JRE. These dependencies are 'packages', that can be shared by multiple applications. Compared to Docker, this results in smaller artifacts for deployment; only the packages that are needed for the deployment itself are transferred to the application server, whereas in Docker, it is still quite customary to also ship the build system in a container, since it doesn’t offer an intuitive difference between buildtime and runtime dependencies. Packages built with Habitat Studio depend only on packages managed by habitat.This effectively introduces yet-another-linux-distribution, which is a potential security issue. Patching the hosts glibc to resolve a security problem won’t fix the application, since it depends on a version provided by a Habitat core package. Of course, this same argument also applies to containers.
Depot
Habitat has the notion of a central depot, which stores the build artifact. This is analogous to a Docker Registry, but instead of storing image layers, it stores packages. Authentication is on the level of a complete depot, and is only possible via GitHub at the time of writing.
Supervisor
Runtime support comes in the form of a templating engine for configuration files and a supervisor. The templating engine is similar to HashiCorp's consul-template. It also uses the Handlebars templating language. Default configuration values can be provided in a TOML file, and overridden when the application is started via environmental variables. Multiple supervisors can be linked together to form a "ring". The supervisors use a gossiping protocol with eventual consistent semantics to communicate with each other. The supervisor offers an HTTP endpoint to expose information about the state of the application, that for example could be used by a load balancer, and offers a mechanism to modify configuration values for the application via the gossiping protocol.
An interesting feature of the supervisor, is that it supports starting multiple instances of an application in a topology. The stand alone, leader-follower and initializer topologies are implemented. In a leader-follower topology, the applications are not started until the supervisors have elected a leader. The initializer topology offers applications to set up an initialization task, before it is brought up. Information about the topology is also exposed to the templating language, make it easy to generate configuration files for e.g. a mysql replication setup. If an application (and/or it’s supervisor) dies, the other supervisors will perform a re-election in the case of the leader-follower topology.
This side of the supervisor reminds me a bit of the AutoPilot pattern. In ContainerPilot, there is no build-in support for these standard topologies. Programmers have to implement these themselves, which is error prone and takes time.
Exporting packages
Habitat can export packages to docker images, ACI images and “marathon applications”, which makes it easy to start using it, if an organization has a infrastructure set up that uses one of these systems.
How it fits in the market
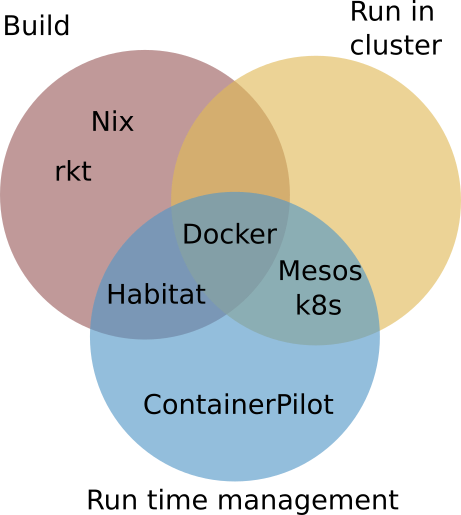
I think that Habitat fills a space that is not yet filled, see the figure. Docker offers both support to build applications and run them in a cluster with some run time management (rolling upgrades) via Docker Swarm, whereas both Mesos and Kubernetes focus on running containers in a cluster, and having run time management. ContainerPilot is just concerned with runtime management of an application. Both Nix and rkt only provide reproducible builds. Habitat focusses on building software and runtime configuration, but leaves the running of an application to a cluster system.
Conclusion
All of this looks quite interesting, however I do have some reservations about Habitat.
It appears to be positioned as a competitor of Docker-without-swarm by Chef, with a better build system than Docker, and some useful support from a supervisor.
Having some experience with Nix myself, I don’t understand why Habitat did not just adopt Nix, or at least replicate its core features and strengths of reproducibility and automatic caching of builds. They could have taken the same route as GNU Guix, which replaces the Nix language with a Scheme DSL, but still utilizes the build machinery of Nix.
In Adam’s introduction talk, he states that sometimes it’s just not possible to get some application to run, except on CentOS 6 and that Habitat allows the end user to depend on the host operating system in those cases. This breaks their claim of reproducibility and isolation completely! Docker and Nix do a better job here, by enforcing isolation between the host system and that which is to be built.
Furthermore, Habitat, packages are uniquely identified by an origin (basically the URL of the depot), name, version and a time stamp. If you would build the same application twice, it would generate a different unique name; the build time is different. In Nix, building the application for the second time will result in a no-op. It assumes that the build process is deterministic (enough) to conclude that recompiling does not result in any meaningful difference, and will just return the cached version.
The support of the supervisor for different topologies is very interesting. I agree that most applications do not need any more topologies than the ones provided.
One thing that bugs me about the supervisors, is that it still needs some external system to bootstrap information about the peer nodes. This implies that Habitat still needs help from a cluster scheduler or something like ContainerPilot to properly register and discover applications in a global service registry.
In any case, the route taken by Habitat is an interesting one, and I’m looking forward to how Habitat is going to evolve over time.