
In Kubernetes there are a few different ways to release an application, it is necessary to choose the right strategy to make your infrastructure reliable during an application update.

Choosing the right deployment procedure depends on the needs, we listed below some of the possible strategies to adopt:
- recreate: terminate the old version and release the new one
- ramped: release a new version on a rolling update fashion, one after the other
- blue/green: release a new version alongside the old version then switch traffic
- canary: release a new version to a subset of users, then proceed to a full rollout
- a/b testing: release a new version to a subset of users in a precise way (HTTP headers, cookie, weight, etc.). A/B testing is really a technique for making business decisions based on statistics but we will briefly describe the process. This doesn’t come out of the box with Kubernetes, it implies extra work to setup a more advanced infrastructure (Istio, Linkerd, Traefik, custom nginx/haproxy, etc).
You can experiment with each of these strategies using Minikube, the manifests and steps to follow are explained in this repository: https://github.com/ContainerSolutions/k8s-deployment-strategies
Let’s take a look at each strategy and see what type of application would fit best for it.

Recreate - best for development environment
A deployment defined with a strategy of type Recreate will terminate all the running instances then recreate them with the newer version.
spec:
replicas: 3
strategy:
type: Recreate
A full example and steps to deploy can be found at https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/recreate
Pro:
- application state entirely renewed
Cons:
- downtime that depends on both shutdown and boot duration of the application
Ramped - slow rollout
A ramped deployment updates pods in a rolling update fashion, a secondary ReplicaSet is created with the new version of the application, then the number of replicas of the old version is decreased and the new version is increased until the correct number of replicas is reached.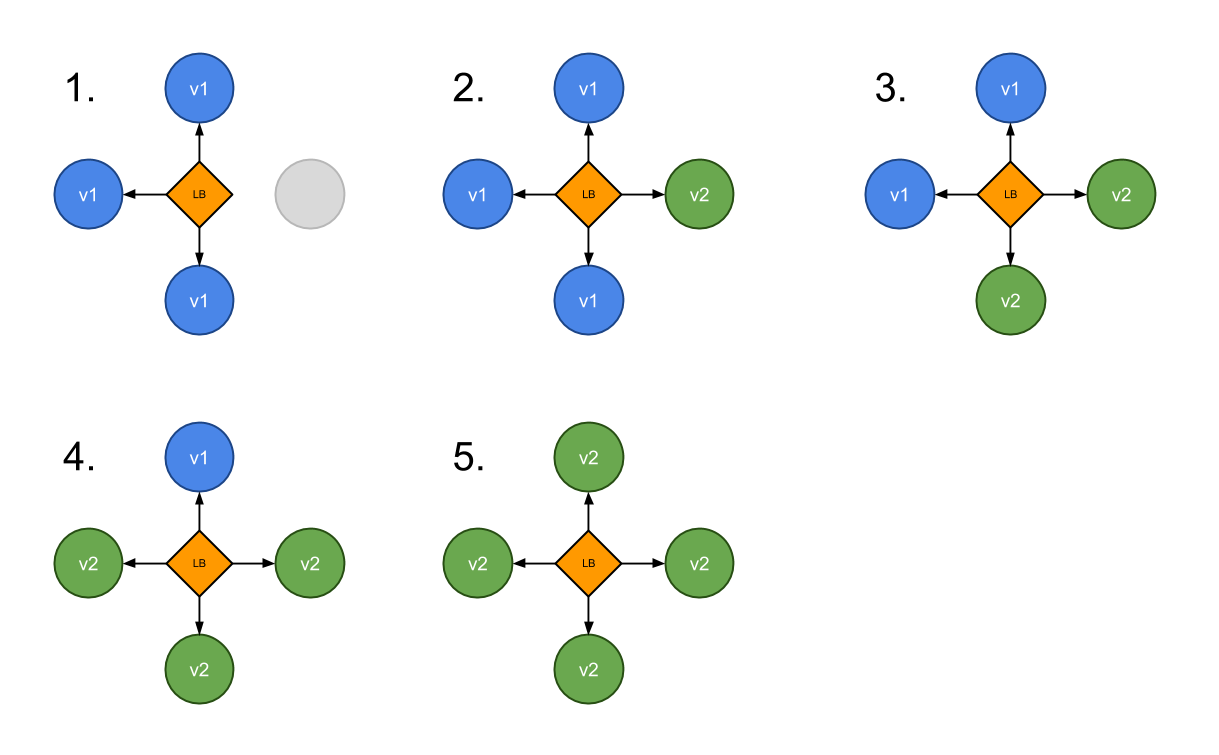
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2 # how many pods we can add at a time
maxUnavailable: 0 # maxUnavailable define how many pods can be unavailable
# during the rolling update
A full example and steps to deploy can be found at https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/ramped
When setup together with horizontal pod autoscaling it can be handy to use a percentage based value instead of a number for maxSurge and maxUnavailable.
If you trigger a deployment while an existing rollout is in progress, the deployment will pause the rollout and proceed to a new release by overriding the rollout.
Pro:
- version is slowly released across instances
- convenient for stateful applications that can handle rebalancing of the data
Cons:
- rollout/rollback can take time
- supporting multiple APIs is hard
- no control over traffic
Blue/Green - best to avoid API versioning issues
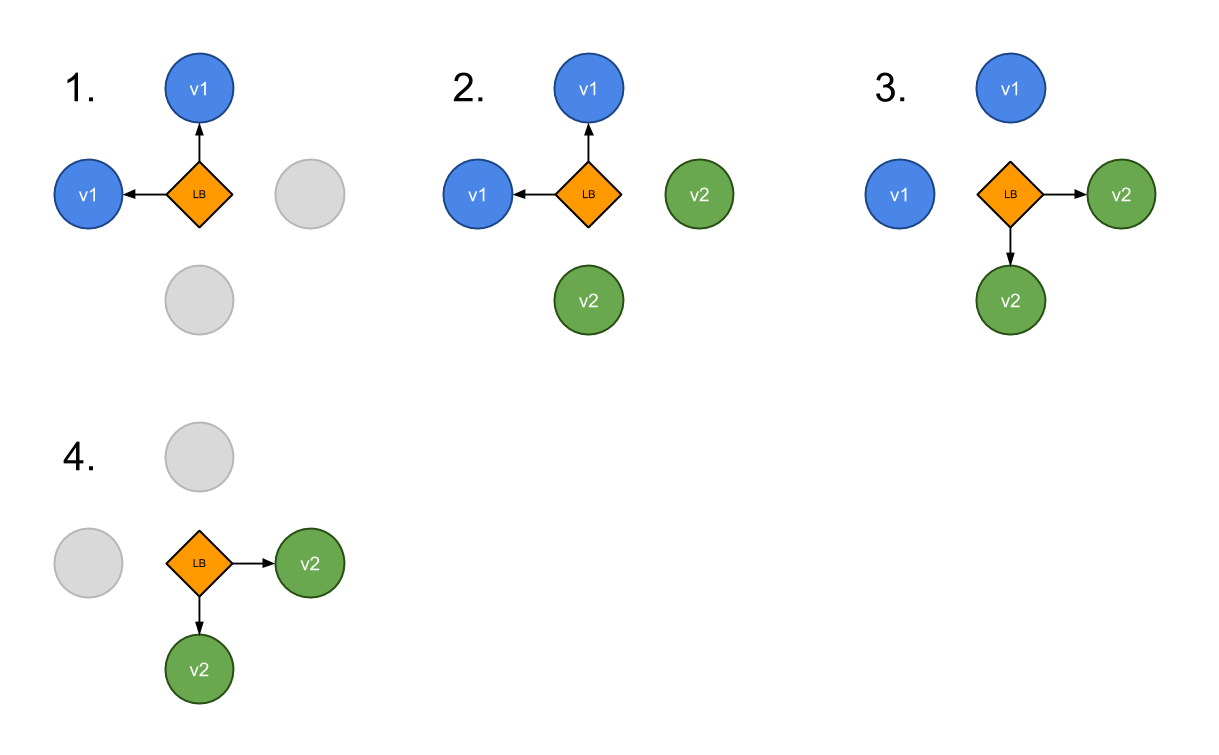
A blue/green deployment differs from a ramped deployment because the "green" version of the application is deployed alongside the "blue" version. After testing that the new version meets the requirements, we update the Kubernetes Service object that plays the role of load balancer to send traffic to the new version by replacing the version label in the selector field.
apiVersion: v1
kind: Service
metadata:
name: my-app
labels:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 8080
targetPort: 8080
# Note here that we match both the app and the version.
# When switching traffic, we update the label “version” with
# the appropriate value, ie: v2.0.0
selector:
app: my-app
version: v1.0.0
A full example and steps to deploy can be found at https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/blue-green
Pro:
- instant rollout/rollback
- avoid versioning issue, change the entire cluster state in one go
Cons:
- requires double the resources
- proper test of the entire platform should be done before releasing to production
- handling stateful applications can be hard
Canary - let the consumer do the testing
A canary deployment consists of routing a subset of users to a new functionality. In Kubernetes, a canary deployment can be done using two Deployments with common pod labels. One replica of the new version is released alongside the old version. Then after some time and if no error is detected, scale up the number of replicas of the new version and delete the old deployment.
Using this ReplicaSet technique requires spinning-up as many pods as necessary to get the right percentage of traffic. That said, if you want to send 1% of traffic to version B, you need to have one pod running with version B and 99 pods running with version A. This can be pretty inconvenient to manage so if you are looking for a better managed traffic distribution, look at load balancers such as HAProxy or service meshes like Linkerd, which provide greater controls over traffic.
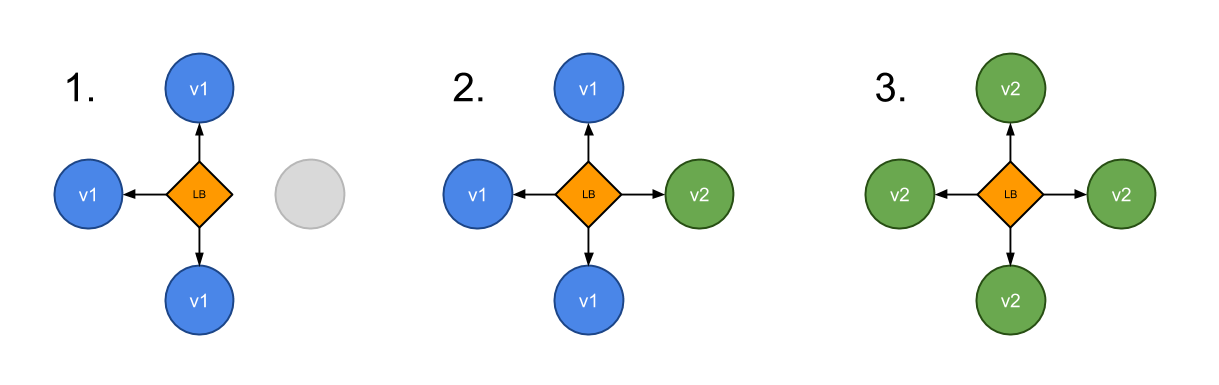
In the following example we use two ReplicaSets side by side, version A with three replicas (75% of the traffic), version B with one replica (25% of the traffic).
Truncated deployment manifest version A:
spec:
replicas: 3
Truncated deployment manifest version B, note that we only start one replica of the application:
spec:
replicas: 1
A full example and steps to deploy can be found at https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/canary
Pro:
- version released for a subset of users
- convenient for error rate and performance monitoring
- fast rollback
Cons:
- slow rollout
- fine tuned traffic distribution can be expensive (99% A/ 1%B = 99 pod A, 1 pod B)
The procedure used above is Kubernetes native, we adjust the number of replicas managed by a ReplicaSet to distribute the traffic amongst the versions.
If you are not confident about the impact that the release of a new feature might have on the stability of the platform, a canary release strategy is suggested.
A/B testing - best for feature testing on a subset of users
A/B testing is really a technique for making business decisions based on statistics, rather than a deployment strategy. However, it is related and can be implemented using a canary deployment so we will briefly discuss it here.
In addition to distributing traffic amongst versions based on weight, you can precisely target a given pool of users based on a few parameters (cookie, user agent, etc.). This technique is widely used to test conversion of a given feature and only rollout the version that converts the most.
Istio, like other service meshes, provides a finer-grained way to subdivide service instances with dynamic request routing based on weights and/or HTTP headers.
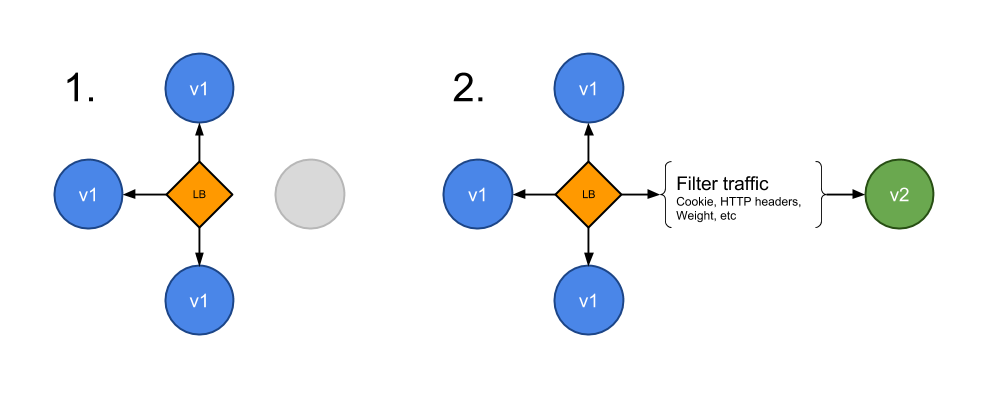
Below is an example of rules setup using Istio, as Istio is still in heavy development the following example rule may change in the future:
route:
- tags:
version: v1.0.0
weight: 90
- tags:
version: v2.0.0
weight: 10
A full example and steps to deploy can be found at https://github.com/ContainerSolutions/k8s-deployment-strategies/tree/master/ab-testing
Other tools like Linkerd, Traefik, NGINX, HAProxy, also allow you to do this.
Pro:
- requires intelligent load balancer
- several versions run in parallel
- full control over the traffic distribution
Cons:
- hard to troubleshoot errors for a given session, distributed tracing becomes mandatory
- not straightforward, you need to setup additional tools
To sum up
There are different ways to deploy an application, when releasing to development/staging environments, a recreate or ramped deployment is usually a good choice. When it comes to production, a ramped or blue/green deployment is usually a good fit, but proper testing of the new platform is necessary. If you are not confident with the stability of the platform and what could be the impact of releasing a new software version, then a canary release should be the way to go. By doing so, you let the consumer test the application and its integration to the platform. Last but not least, if your business requires testing of a new feature amongst a specific pool of users, for example all users accessing the application using a mobile phone are sent to version A, all users accessing via desktop go to version B. Then you may want to use the A/B testing technique which, by using a Kubernetes service mesh or a custom server configuration lets you target where a user should be routed depending on some parameters.
I hope this was useful, if you have any questions/feedback feel free to comment below.
