
Why should we try to make incident reports engaging?
Over the past several years as the DevOps and the SRE movements have taken root in software, it has become standard practice to conduct incident reviews in the wake of customer-impacting outages or problems. This is a positive development: incidents are events that can teach us things about our systems and our organisations that we didn’t know before. If we don’t pay attention to incidents, then we pass up valuable learning opportunities that can help us to make our systems more robust and resilient.
But there’s more to it than simply having a meeting and filling out an incident review template. It’s very easy—and very common—to rush through and end up with a very thin analysis of the incident that doesn’t really tell us anything that we didn’t already know, and that doesn’t have any medium or long term impact on the organisation.
On the other hand, it is also possible to create incident writeups that engineers choose to read, that clearly describe and highlight difficult and poorly-understood aspects of our systems, and that become part of the organisation’s collective understanding. The most successful written incident reports can become a long-term store of knowledge, and often a key part of onboarding for new engineers, and eventually pass into a sort of organisational folklore. Text is an ideal medium for this kind of knowledge dissemination and storage: it is searchable, accessible, and it can encourage deep engagement and reflection.
The best incident reviews and reports are a way to share knowledge and context about systems, including between teams—which is always a challenge. They can help make a case to prioritise reliability work. They are a tool to encourage thoughtful reflection about our work. They can help to disseminate valuable insights about the strengths and sharp edges of SaaS and OSS tools through the entire industry.
Richard Cook wrote in ‘How Complex Systems Fail’ that:
Complex systems require substantial human expertise in their operation and management. This expertise changes in character as technology changes but it also changes because of the need to replace experts who leave. In every case, training and refinement of skill and expertise is one part of the function of the system itself. At any moment, therefore, a given complex system will contain practitioners and trainees with varying degrees of expertise. Critical issues related to expertise arise from (1) the need to use scarce expertise as a resource for the most difficult or demanding production needs and (2) the need to develop expertise for future use.
As Cook points out, expertise is critical to reliable operations: and it is a resource that your organisation is constantly losing. Therefore, we also need to constantly rebuild expertise. Incident write-ups are not the only tool for building expertise, but they are a very important one, because they explicitly link the structure of systems with how things can go wrong—or right. Incident writeups teach us not only the form and function of our systems, but about the many constraints that shape that form.
This article distils what I know about writing incident write-ups that people want to read, whether public or internal-only. It isn’t an exhaustive description of how to go about conducting a post-incident review—for detail on all the steps, including gathering information and interviewing participants, see the Howie guide to post-incident investigations.
It is worth saying now that what I propose doing in this article is not a lightweight process. Creating an incident writeup of enduring value takes time and focus. It is neither feasible nor worthwhile to do deep sense-making and writing work for every single incident your organisation encounters. But it is almost certainly worth it for some subset of your incidents: the incidents that surprise you, that puzzle you. The incidents that happen in the dark and scary haunted graveyards. The ones that were difficult to handle for some reason. The ones that seem to form part of a larger story; that seem to ask for deeper analysis. I believe it is better to focus much of your time and energy on these incidents, rather than trying to give equal attention and treatment to every single production glitch.
Focus on narrative, not metadata
The cardinal crime we commit against our incident writeups is turning them into forms. We take what are often fascinating tales, full of mystery and excitement… and we make them into something that’s about as fun to read as a tax return.
Many organisations which do incident reviews or postmortems have a detailed template, covering information such as the impact start and end times, services affected, number of customers affected, what triggered the incident, and so on.
Templates have value: they ensure that standardised information is collected and can feed into tooling, they can help authors get started without having to conquer the empty page, and they provide a structure for readers.
However, there is a dark side to the use of templates. As with any form, they tend to encourage writers to speed through filling the template out. Templates do not normally distinguish between elements that should be short—such as metadata—and elements which may be long and complex, such as describing the trigger. Separating elements such as the trigger, contributing factors, resolution, and detection can also lead to a very confused and fragmented account of the event, which is difficult for readers to make sense of unless they already have significant context about the systems in question.
Consider Jurassic Park (the iconic Spielberg movie) as a template-based incident review:
- Incident Number: JP-001
- Impact: 5 human deaths, facilities on island a total loss, significant reputational damage.
- Summary: Dinosaurs escaped from enclosures. Some deaths resulted.
- Resolution: Costa Rican military bombed the island, killing all dinosaurs.
- Trigger: Operator disabled electric fences.
- Root Cause: Internal processes failed to detect a corrupt employee who engaged in bribery.
- How We Got Lucky: Several staff and visitors escaped via helicopter.
[todo re-format as table?]
It is safe to say that in this form, this is not material for a riveting Hollywood blockbuster. Nor is it easy to follow.
Template-based writeups tend to be low on detail, especially about what the people in the incident were thinking and how they understood the circumstances and what was difficult or confusing—and that’s an really important aspect of incident review, because one of the most important things we’re trying to get out of this is learning: helping engineers’ expertise keep up with the complexity of the system, and having our tooling support human sense-making.
This makes template incident writeups often less than useful for learning, and more an exercise in bureaucracy. Instead, it is best to start with a long-form narrative that describes the incident, and to make that the heart of your incident writeup. People love a good story: so tell a story.
A story has a cast of characters, and a beginning, a middle, and an end. So do incidents. Many great incident narratives take the form of a mystery or a detective story (or sometimes a disaster story or a comedy!). Reddit’s Kubernetes cluster upgrade on March 14 2023 is a very good example of the genre.
First, present the puzzle: how did the incident begin? How was it detected? What did the responders know at this point? Were there preceding events (such as in the case of the Reddit outage)? This part of the narrative piques the reader’s interest and leaves them wanting to know more.
Now, the peril: how did the responders react? What was tried and failed? How did they go about making sense of the incident? What made it difficult to handle—did they have missing or misleading monitoring? Were there risky tradeoffs to balance? This part of the narrative builds suspense, helps to put the reader into the responders’ shoes, and begins to add more detail about what was happening during the incident. This part of the narrative is also valuable for engineers who might subsequently face similar incidents as it lets us mentally rehearse the kinds of decisions we might later need to make under pressure.
Finally, we have the resolution and the explanation. How was the incident resolved? What was happening? What triggered it? This is where the deep systems explanations often come in. Sometimes the explanation can cover years of history of a system’s evolution.
This narrative structure takes your readers on a journey which is both fun and informative. Making it interesting makes your readers more likely to read it closely. Presenting a puzzle means that your readers will want to know the answer: they will pay more attention to a write-up structured in this way than they will a dry account of the incident mechanism. If we want to promote learning then this is a worthwhile investment of time.
Another great example of narrative writeup is Christian Holler’s account of the Firefox outage on January 13th 2022. A GCP config change enabling HTTP/3 triggered a latent bug in Firefox Rust HTTP/3 handling code that caused an infinite loop, blocking all network access. Christian writes that “we quickly discovered that the client was hanging inside a network request to one of the Firefox internal services. However, at this point we neither had an explanation for why this would trigger just now, nor what the scope of the problem was.” Christian is presenting a mystery, and showing the reader what the responders knew and didn’t know. Here’s another example of describing the investigators’ mindset: “Although we couldn’t see it, we suspected that there had been some kind of “invisible” change rolled out by one of our cloud providers that somehow modified load balancer behaviour.”
Devin Sylva’s account of the Consul outage that never happened is an absolutely riveting account of an incident in which GitLab discovered that the self-signed certs that their Consul cluster was using to communicate with itself had expired and couldn’t be replaced because the CA key had been lost. Sylva writes: “Effectively, we were in the middle of an outage that had already started, but hadn't yet gotten to the point of taking down the site. [...] We all held our breath, and watched the database for signs of distress. Six minutes is a long time to think: ‘It's 4am in Europe, so they won't notice’ and ‘It's dinner time on the US west coast, maybe they won't notice’.”
These accounts are memorable: and memorable stories encourage durable learning.
Support your readers
Another weakness of template-based incident write-ups is that they often do a poor job of supporting the reader. Supporting the reader means helping the reader to make sense of the incident. If a reader has to stop and puzzle through something, then it breaks the flow of the narrative, meaning that readers are less likely to stick with reading the writeup, and will miss opportunities for learning.
The place to start is by writing your incident report for any engineer to be able to read. The engineer shouldn’t need detailed knowledge of the specific systems being described: your account should explain what is necessary to understand the outage.
This means avoiding or explaining jargon and internal system names. It also means explaining the purpose of each system or component: what does it do? Who uses it and why?
It is best to weave concise explanations into the narrative as needed, and to link out to more detailed documentation where appropriate. There is no sense in rewriting detailed documentation that exists elsewhere, but it is also not easy on readers to require them to jump between different documents to understand the flow of your narrative.
David Cramer’s 2015 writeup of a Sentry outage is a nice example of weaving background information into a report while linking to authoritative information elsewhere. The issue was caused by Postgres transaction ID wraparound. Cramer writes:
The first time a transaction manipulates rows in the database (typically via an INSERT, UPDATE, or DELETE statement) the database’s XID counter is incremented. This counter is used to determine row visibility. The best human-readable description we’ve found is Heroku’s topic on the MVCC and concurrency.
Eventually, that database is going to reach a situation where the XID counter has reached its maximum value. […] Since there are no longer any unique XID values available to identify new transactions, the database must halt to prevent XID re-use — otherwise, transactions that occurred in the past could suddenly appear to be in the future, leading to all kinds of strange and undesirable behavior.
You don’t need to jump out to the linked documentation to make sense of Cramer’s narrative: but it’s there for readers who do want to go deeper.
Ben Wheatley’s account of GoCardless’s outage on October 25 2020 is another example of deftly weaving supporting information about how and why they use Hashicorp’s Vault into an incident narrative:
At GoCardless we aim to keep velocity high by ensuring that [...] secret data can be managed by the engineers building these services, rather than relying on an operational team to make changes. To this end, we've implemented a system based on Hashicorp's Vault product.
We run an instance of Vault that all engineers can authenticate with, using their Google identity, and have the permissions to write secrets into, but not read the secret data out of. We additionally have policies configured in Vault that ensure our applications, authenticated via their Kubernetes service account token, can read secret data belonging to that application only.
You can read these short paragraphs and understand exactly what Vault is used for at GoCardless—without having to go and read documentation about Vault and puzzle it out, breaking the flow of Wheatley’s tale.
Be visual
A picture is worth a thousand words, and diagrams and visualisations have never been easier to create, thanks to the plethora of tools such as LucidCharts, Miro, and Excalidraw that make it very simple to create quite sophisticated images.
Visuals break up walls of text, making it easier for readers to orient themselves towards these important ‘landmarks’. This helps particularly with rereading or finding particular passages in a long write-up. Images also help to support the reader, by reinforcing complex flows, structures, or relationships which are described in your text. You can include all kinds of visual elements: graphs, architecture diagrams, sequence diagrams, topologies, flowcharts, timelines—you can also be creative and build your own custom visualisations.
Cloudflare produces many excellent incident writeups, and are particularly strong in their use of visuals. Tom Strickx and Jeremy Hartman’s report of the Cloudflare outage on June 21 2022 includes this graphic that helps to explain how BGP policies work, and how reordering terms can inadvertently cause withdrawal of routes to an IP space: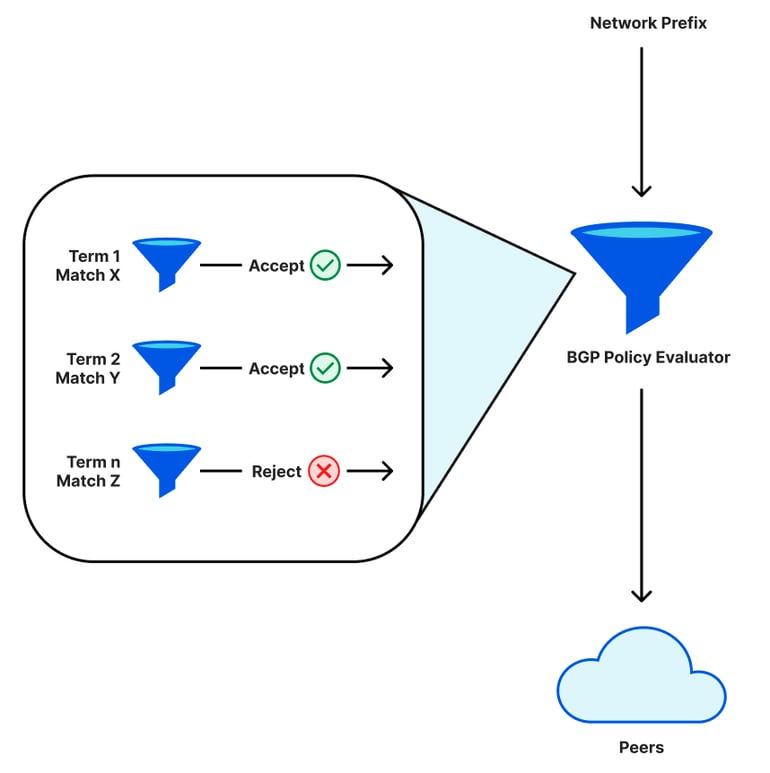
Honeycomb’s lengthy report ‘Do You Remember, the Twenty Fires of September’ deals with a sequence of incidents that Honeycomb experienced in 2021. Again, they use a custom visualisation to help to explain a particularly complex point, to do with how a sharding scheme created hotspotting in one of their services.
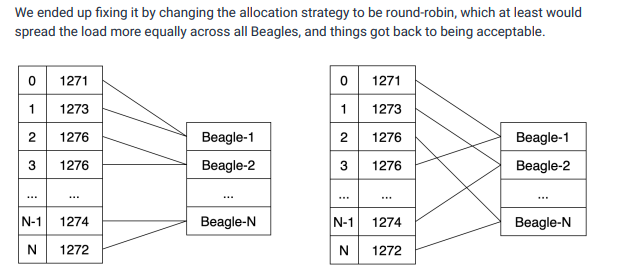
Fig 2: Honeycomb’s illustration of two sharding strategies
Rafael Elvira’s writeup for Slack of ‘The Case of the Recursive Resolvers’ includes this graphic which summarises a very complex DNS migration timeline, involving several domain names and multiple successful changes and rollbacks.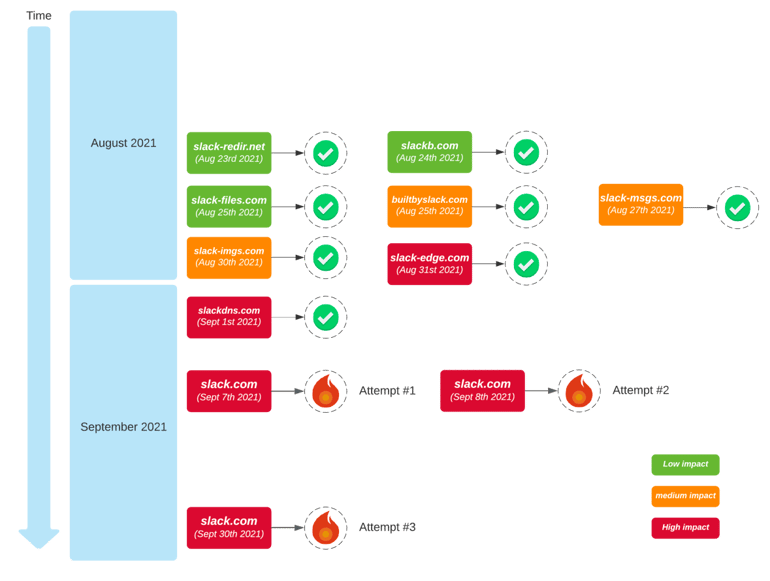
Fig 3: Slack’s complex DNS migration timeline
Visuals are one area where there really are no rules, and no constraints except for time and creativity. Engineers have used diagrams of many kinds for as long as engineering has existed: they are an incredible tool for sharing knowledge about complex systems and situations.
Don’t be afraid of analysis
Many incident write-ups focus primarily on events and action items. However, If an incident write-up is a story, the analysis is the moral of the story. Sharing analysis is by far the most satisfying way to wrap up an IR, creating a feeling of resolution.
Performing analysis—and sharing your analyses—also helps us to spot recurring patterns, both in our organisations and more broadly in the entire software industry. Patterns help us to think, as David Woods and co-authors write in their white paper ‘Patterns in How People Think and Work’: we can recognise situations as specific cases of more general patterns.
Devin Sylva’s the Consul outage that never happened provides a good example of an analysis:
Every once in a while we get into a situation that all of the fancy management tools just can't fix. In these types of situations there is no shortcut around thinking things through methodically. In this case, there were no tools or technologies that could solve the problem. Even in this new world of infrastructure as code, site reliability engineering, and cloud automation, there is still room for old fashioned system administrator tricks. There is just no substitute for understanding how everything works.
Maybe we won’t face Sylva’s exact problem, but many of us will face problems where we need to use ingenuity to improvise ways out of situations that our modern infrastructure tools cannot handle. This is a pattern.
Honeycomb’s ‘Do You Remember, the Twenty Fires of September’ includes this analysis:
If we operate too far from the edge, we lose sight of it, stop knowing where it is, and can’t anticipate when corrective work should be emphasized. But if we operate too close to it, then we are constantly stuck in high-stake risky situations and firefighting.
This gets exhausting and we lose the capacity, both in terms of time and cognitive space, to be able study, tweak, and adjust behavior of the system. This points towards a dynamic, tricky balance to strike between being too close to the boundary and too far from it, seeking some sort of Goldilocks operational zone.
Again, we may not find ourselves in Honeycomb’s exact circumstances, but this tension between being too safe and losing touch with how our systems behave at the boundaries versus the potential burnout that results from too many incidents is certainly familiar to most software operations practitioners.
Patterns can exist at every level of our stack, from these sociotechnical examples to the purely technical, such as Cramer’s account of postgres transaction ID wraparound, a technical pattern which has recurred in many production systems.
Analysis is valuable because it deals with the relationships between elements, helping to uncover durable lessons that we can apply not only in this specific situation but in other situations that include similar kinds of elements or relationships. Facebook’s Nathan Bronson authored a report of an incident involving custom MySQL connection pools becoming overloaded. It contains the following analysis:
Facebook collocates many of a user’s nodes and edges in the social graph. That means that when somebody logs in after a while and their data isn’t in the cache, we might suddenly perform 50 or 100 database queries to a single database to load their data. This starts a race among those queries. The queries that go over a congested link will lose the race reliably, even if only by a few milliseconds. That loss makes them the most recently used when they are put back in the pool. The effect is that during a query burst we stack the deck against ourselves, putting all of the congested connections at the top of the deck.
Bronson’s conclusion here is valuable because it applies not only to this specific situation, but can be broadly applied to connection-pooling situations. Many incidents can provide this kind of insight, if we take the time to uncover them. This is the work that makes us better engineers.
More than anything else, stories help us to grasp the complexities of the systems - human and technical - that we must navigate every day. As Jean Luc Godard said, "Sometimes reality is too complex. Stories give it form."
