

In this series of blog posts, I will highlight some strategies and tips when adopting Kubernetes. The goal is to provide practical examples based on usages of other companies who have already gone down this road.

When adopting a new technology, such as Kubernetes, we often plug it in, use the basic features, and continue our development process as usual. However, in many cases we can leverage the features of these new technologies to solve our old problems in better, more efficient ways. Deploying Kubernetes to run and manage our applications is a good start, but we can go further, looking for ways to improve our whole development cycle.
The problem I will focus on here is managing multiple environments. Most organizations have a variety of different environments, such as production, staging, testing, development etc. They generally come either with strict access and security controls in terms of who can deploy what where, or else on the other end of the spectrum, they are wide open, with all users given free reign. I have worked in both of these types of organisations and neither is ideal. In the former case, the rigidity and controls put in place result in many wasted hours by developers who need to submit requests to a Configuration Management or Deployment team. And in the latter case, the environments tend towards becoming a mystery as to which versions of which services are running on them.
There are several challenges around creating and maintaining these environments, the first is that we want them to be as close as possible to mimicking production. This way as we develop and test new features we can feel more confident that things will behave the same way once we go live. The longer these environments hang around the more likely they are to diverge from our production setup. On top of this, maintaining several environments at a one-to-one parity with production can be far too costly in terms of resources.
How can we leverage an orchestration platform to solve this for us? We can take the idea of immutable infrastructure and apply it one level higher, creating dynamic environments on demand. If we don’t need these environments up all the time, then why not just bring them up on demand.
There are some features in Kubernetes which make it easy for us to do just this. The two main ideas for this setup are sharing infrastructure, not just the servers, but the kubernetes cluster itself, and second, creating and then deleting environments on the fly.
The main feature we can use to support this is namespaces. The documentation states: “Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces.”. Because they are virtual clusters, namespaces are very quick to create and also to clean up. Deleting a Kubernetes namespace will also delete all the resources within the namespace.
Let’s see how we can incorporate this idea into an existing Continuous Integration Pipeline: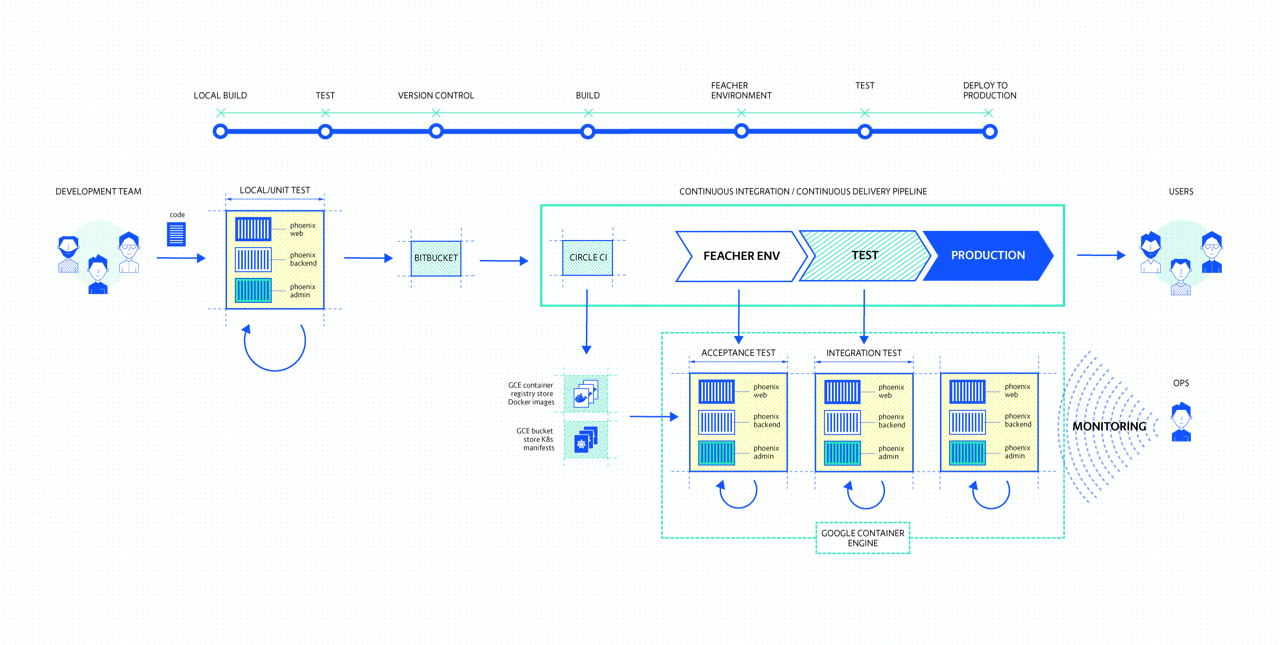
For the sake of a demo we will use the Sock Shop (https://microservices-demo.github.io) reference application. We’ll create a CI pipeline to build our own service, and then deploy it along with the Sock Shop application into a dynamically created namespace in our Kubernetes cluster. We’ll verify the build by running some integration tests, and when successful, throw away the entire environment (namespace).
You can find the service and build and deploy scripts in the following repo: https://gitlab.com/iandcrosby/continous-socks
The pipeline is defined inside the .gitlab-ci.yml file, it defines some variables and the stages of our pipeline:
variables:
IMAGE_NAME: "${CI_REGISTRY}/iandcrosby/${CI_PROJECT_NAME}"
NAMESPACE: "${CI_PROJECT_NAME}-${CI_BUILD_REF_NAME}-${CI_BUILD_REF}"
stages:
- build
- deploy
- test
- cleanup
The first stage is the build, where we build our docker image based on the latest commit, we will tag our image with the build info and push it to our registry:
build:
image: docker:latest
services:
- docker:dind
stage: build
script:
- echo "$KUBE_URL"
- docker login -u gitlab-ci-token -p "$CI_BUILD_TOKEN" "$CI_REGISTRY"
- docker build -t "$IMAGE_NAME:${CI_BUILD_REF_NAME}-${CI_BUILD_REF}" .
- docker push "$IMAGE_NAME:${CI_BUILD_REF_NAME}-${CI_BUILD_REF}"
(Note: The KUBE_* variables are made available via the GitLab Kubernetes integration.)
The deploy stage will create a new namespace based on the project name and the build (this guarantees each namespace to be unique), we then create a deployment config for our newly built image from a template and deploy it to the new namespace. We also deploy any dependencies we need for running our integration tests, in this case we deploy a subset of the Sock Shop.
deploy:
stage: deploy
image: registry.gitlab.com/gitlab-examples/kubernetes-deploy
script:
- ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN
- kubectl create ns $NAMESPACE
- kubectl create secret -n $NAMESPACE docker-registry gitlab-registry --docker-server="$CI_REGISTRY" --docker-username="$CI_REGISTRY_USER" --docker-password="$CI_REGISTRY_PASSWORD" --docker-email="$GITLAB_USER_EMAIL"
- mkdir .generated
- echo "$CI_BUILD_REF_NAME-$CI_BUILD_REF"
- sed -e "s/TAG/$CI_BUILD_REF_NAME-$CI_BUILD_REF/g" templates/deals.yaml | tee ".generated/deals.yaml"
- kubectl apply --namespace $NAMESPACE -f .generated/deals.yaml
- kubectl apply --namespace $NAMESPACE -f templates/my-sock-shop.yaml
environment:
name: test-for-ci
Next, the test stage will first wait until all pods are in a Ready state, and then runs our tests against the new namespace.
test:
stage: test
image: registry.gitlab.com/gitlab-examples/kubernetes-deploy
script:
- ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN
# Verify all pods are up
- until kubectl get pods -o=jsonpath='{.items[?(@.metadata.labels.name=="deals")].status.conditions[*].status}' -n $NAMESPACE | grep -v False; do sleep 5; done
# Run tests
- echo "testing"
- ./runTests.sh $NAMESPACE
environment:
name: test-for-ci
Finally, there is a clean up stage which simply deletes the namespace. This removes all resources which we have deployed in that namespace.
cleanup:
stage: cleanup
image: registry.gitlab.com/gitlab-examples/kubernetes-deploy
script:
- echo "Removing Kubernetes namespace $NAMESPACE"
- ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN
- kubectl delete ns $NAMESPACE
environment:
name: test-for-ci
when: always
Since multiple stages need to connect to the cluster, I’ve pulled these steps out into their own script (configureCluster.sh).
#!/bin/bash
KUBE_CA_PEM_FILE=$1
KUBE_URL=$2
KUBE_TOKEN=$3
kubectl config set-cluster ci-demo --server="$KUBE_URL" --certificate-authority="$KUBE_CA_PEM_FILE"
kubectl config set-credentials ci-demo --token="$KUBE_TOKEN" --certificate-authority="$KUBE_CA_PEM_FILE"
kubectl config set-context ci-demo --cluster=ci-demo --user=ci-demo
kubectl config use-context ci-demo
kubectl version
Putting this all together, we get the following pipeline:
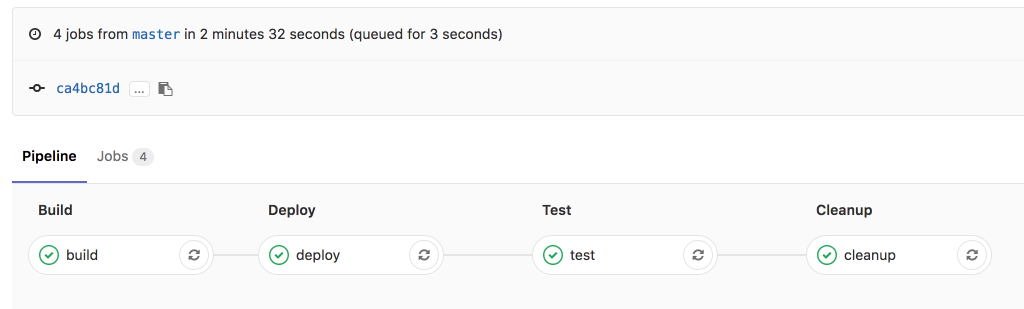
With such a solution, we remove the need for a classical ‘Integration environment’. Which is not only a waste of resources (keeping it up and available 24/7) but also, these environments tend to diverge further from the source of truth (production) the longer they live. Since our short lived environments are created on demand, from the same sources we use to create our production setup, we can be confident we are running a near-production like system.
*In order to properly benefit in terms of cost savings, you will need to have auto scaling setup on your cluster. As we usually pay by the instance, our cluster needs to add and remove machines as needed.*
The above example is only a demo meant to show how this functionality can be used. I have worked with several organizations who have implemented similar setups. This is just the first step, the questions that usually come next surround access control and security. How can we limit access to certain environments? How can we ensure some memory hungry applications on one environment do not impact the rest? In the following blog post I will take the above example and address these concerns by leveraging RBAC, Network Policies and Limits.
Want to learn more? Read the whitepaper from Ian Crosby: