

Java (and its other JDK-based siblings) is the most widely used programming language in large companies. Java developers are backend focused and used to building complex distributed systems. Yet these developers’ potential is rarely used when it comes to programmable infrastructure challenges.
Developers collaborating with operations engineers is at the heart of the DevOps movement, and Kubernetes operators provide a perfect way for developers to contribute to infrastructure automation.
In this blog post, I will:
- Explain the rationale for building Kubernetes operators in Java.
- Present a use-case for building your own Kubernetes operator.
- Show how to implement the business logic of the operator.
- Show how to deploy the operator to Kubernetes.
Why Kubernetes Operators?
Operators are a design pattern to automate the operation of more complex applications or pieces of infrastructure by creating a pod (container) that runs on Kubernetes and has the management logic embedded inside. This logic is called the control loop.
The control loop can be implemented using Java or any other general purpose programming language that can talk to the Kubernetes API. The input for the control loop are objects created in the Kubernetes API server, which supports custom schemas for these objects. They are called Custom Resources.

The MySQLSchema Operator
A common scenario for infrastructure automation is the provisioning of databases for applications. This process is usually implemented by developers sending an email to operations, which is a costly manual process. Let’s see how we can automate it!
In this example, we will be provisioning MySQL databases. Individual databases in a MySQL server are called schemas. We don’t want to spin up a new database server for each application, rather, we want to create a new schema.
To do this we will need two things:
- Create a new Custom Resource Definition called MySQLSchema to allow Kubernetes users to create new Custom Resources of this type.
- Implement the logic which will watch the Kubernetes API for new MySQLSchema objects and create the actual schema in MySQL, or delete it when needed.
Language of Choice: Java
Operators have been booming in the past few years and you can find an operator for many popular applications on operatorhub.io. The default tool kit used for implementing operators is the Golang-based operator-sdk.
However, Golang is not the only language that can be used to build operators. As an operator is just a normal pod running on the cluster, it can be implemented in any language. As Java is one of the most popular languages, it’s a good choice for implementing operators. It has a mature client library (fabric8) for interacting with the Kubernetes API server. This is a critical piece of the puzzle, as an operator will make heavy use of the API—watching resources for changes and updating them.
Now you might be wondering, why not just go with the pack and learn some Go to build your first operator? While that’s a perfectly reasonable choice, we would like to offer a few arguments about why you might want to go with Java, assuming it’s the language you use in your daily work.
- It’s much easier to learn how to implement an operator than it is to learn how to code in Golang. While Golang is touted as a simple language, it still has its whole ecosystem of libraries, dependency management, design patterns, and best practices.
- If the application the operator manages is written in Java, why would the operator be built using a whole different stack, putting extra cognitive load on the whole team that has to maintain it?
- If your company is a Java shop, introducing Go into the toolchain without a strong reason might create more harm than good.
 Implementing the MySQLSchema Operator
Implementing the MySQLSchema Operator
Our MySQLSchemaOperator will need to do the following:
- Listen to changes to any MySQLSchema resources from the API server using Fabric8.
- Map MySQLSchema resources to a set of Java classes.
- Reconcile the state of MySQLSchema resources with the actual state in the MySQL database cluster. If a resource named ‘mydb’ exists in Kubernetes, the operator has to make sure a schema is created.
- Update the Custom Resource with the URL of the newly created database schema to indicate a successful schema creation.
- Create a ConfigMap and a Secret with the URL and credentials to access the database. These can then be mapped to the application, which uses the database as environment variables or volumes.
What does a MySQLSchema resource look like? It is very simple, because we want it to be simple. We don’t want to give our users much flexibility. Essentially, it’s just the name of the schema and the default table encoding.
apiVersion: "mysql.sample.javaoperatorsdk/v1"
kind: MySQLSchema
metadata:
name: mydb
spec:
encoding: utf8
Introducing the java-operator-sdk
We would like Java developers to have the same streamlined experience as the Golang folks do, and that’s why we created the java-operator-sdk.
The heart of the java-operator-sdk is the operator-framework. The operator-framework:
- Wraps fabric8 and configures it for listening to changes on the specified Custom Resources, thus hiding the boilerplate code required for this.
- Provides a clean interface to implement the reconciliation loop for a particular resource type.
- Schedules change events to be executed in an efficient manner. Filtering obsolete events and executing unrelated events in parallel.
- Retry failed reconciliation attempts.
With this in mind, we can present a full picture of the stack:
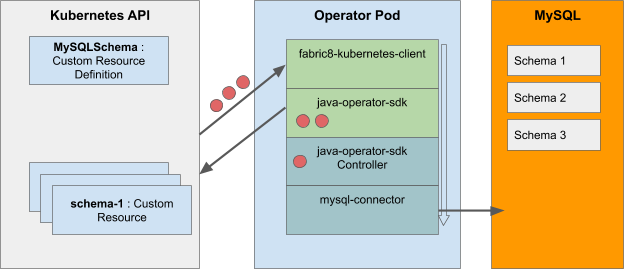
The fabric8 client will be handling the communication with the Kubernetes API. The operator-framework handles management of events received by fabric8 and calls into the controller logic. This is the heart of the operator, where our MySQLSchema provisioning business logic will live. Our logic in turn will use the mysql-connector library to talk to the MySQL server.

Custom Resource Definition
With the java-operator-sdk in our toolbelt, we can jump in to implement the logic. For those who want to jump ahead and just read the code, you can find it among the examples in the SDK.
First we have to tell Kubernetes about our new Custom Resource. This is done using a Custom Resource Definition (CRD):
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: schemas.mysql.sample.javaoperatorsdk
spec:
group: mysql.sample.javaoperatorsdk
version: v1
scope: Namespaced
names:
plural: schemas
singular: schema
kind: MySQLSchema
validation:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
encoding:
type: stringKubernetes only cares about the name to be registered, but you can optionally provide an OpenAPI v3 schema to make sure clients can only create Custom Resources with the correct format. This will be verified during resource updates.
You can register the CRD with Kubernetes using a simple apply command with a yaml file containing the above definition:
kubectl apply -f crd.yaml
Java Classes Mapping the Custom Resource
The next step is to map Custom Resource to Java classes:
import io.fabric8.kubernetes.client.CustomResource;
public class Schema extends CustomResource {
private SchemaSpec spec;
private SchemaStatus status;
//getters and setters
}
public class SchemaSpec {
private String encoding;
//getters and setters
}
public class SchemaStatus {
private String url;
private String status;
//getters and setters
}
The data from the Custom Resource will be mapped to objects of these classes. Fabric8 uses the Jackson object mapper library in the background for this. Notice that this is a point where we are interfacing with the fabric8 library by extending the CustomResource class. This doesn’t mean much for our code but is a requirement for fabric8.
Implementing the Control Loop
At this point, we are ready to implement the control loop. To do this, we have to implement the ResourceController interface, which only has two methods:
public interface ResourceController<R extends CustomResource> {
UpdateControl createOrUpdateResource(R resource, Context<R> context);
boolean deleteResource(R resource);
}
These methods are where the reconciliation logic will live. The job of the operator-framework is to call these methods whenever a Custom Resource object in the Kubernetes API gets created, updated, or deleted.
package com.github.containersolutions.operator.sample;
import com.github.containersolutions.operator.api.Context;
import com.github.containersolutions.operator.api.Controller;
import com.github.containersolutions.operator.api.ResourceController;
import com.github.containersolutions.operator.api.UpdateControl;
import io.fabric8.kubernetes.api.model.Secret;
import io.fabric8.kubernetes.api.model.SecretBuilder;
import io.fabric8.kubernetes.client.KubernetesClient;
import org.apache.commons.lang3.RandomStringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Base64;
import static java.lang.String.format;
@Controller(
crdName = "schemas.mysql.sample.javaoperatorsdk",
customResourceClass = Schema.class)
public class SchemaController implements ResourceController<Schema> {
static final String USERNAME_FORMAT = "%s-user";
static final String SECRET_FORMAT = "%s-secret";
private final Logger log = LoggerFactory.getLogger(getClass());
private final KubernetesClient kubernetesClient;
public SchemaController(KubernetesClient kubernetesClient) {
this.kubernetesClient = kubernetesClient;
}
@Override
public UpdateControl<Schema> createOrUpdateResource(Schema schema, Context<Schema> context) {
try (Connection connection = getConnection()) {
if (!schemaExists(connection, schema.getMetadata().getName())) {
connection.createStatement().execute(format("CREATE SCHEMA `%1$s` DEFAULT CHARACTER SET %2$s",
schema.getMetadata().getName(),
schema.getSpec().getEncoding()));
String password = RandomStringUtils.randomAlphanumeric(16);
String userName = String.format(USERNAME_FORMAT,
schema.getMetadata().getName());
String secretName = String.format(SECRET_FORMAT,
schema.getMetadata().getName());
connection.createStatement().execute(format(
"CREATE USER '%1$s' IDENTIFIED BY '%2$s'",
userName, password));
connection.createStatement().execute(format(
"GRANT ALL ON `%1$s`.* TO '%2$s'",
schema.getMetadata().getName(), userName));
Secret credentialsSecret = new SecretBuilder()
.withNewMetadata().withName(secretName).endMetadata()
.addToData("MYSQL_USERNAME", Base64.getEncoder().encodeToString(userName.getBytes()))
.addToData("MYSQL_PASSWORD", Base64.getEncoder().encodeToString(password.getBytes()))
.build();
this.kubernetesClient.secrets()
.inNamespace(schema.getMetadata().getNamespace())
.create(credentialsSecret);
SchemaStatus status = new SchemaStatus();
status.setUrl(format("jdbc:mysql://%1$s/%2$s",
System.getenv("MYSQL_HOST"),
schema.getMetadata().getName()));
status.setUserName(userName);
status.setSecretName(secretName);
status.setStatus("CREATED");
schema.setStatus(status);
log.info("Schema {} created - updating CR status", schema.getMetadata().getName());
return UpdateControl.updateStatusSubResource(schema);
}
return UpdateControl.noUpdate();
} catch (SQLException e) {
log.error("Error while creating Schema", e);
SchemaStatus status = new SchemaStatus();
status.setUrl(null);
status.setUserName(null);
status.setSecretName(null);
status.setStatus("ERROR");
schema.setStatus(status);
return UpdateControl.updateCustomResource(schema);
}
}
@Override
public boolean deleteResource(Schema schema, Context<Schema> context) {
log.info("Execution deleteResource for: {}", schema.getMetadata().getName());
try (Connection connection = getConnection()) {
if (schemaExists(connection, schema.getMetadata().getName())) {
connection.createStatement().execute("DROP DATABASE `" + schema.getMetadata().getName() + "`");
log.info("Deleted Schema '{}'", schema.getMetadata().getName());
if (userExists(connection, schema.getStatus().getUserName())) {
connection.createStatement().execute("DROP USER '" + schema.getStatus().getUserName() + "'");
log.info("Deleted User '{}'", schema.getStatus().getUserName());
}
this.kubernetesClient.secrets()
.inNamespace(schema.getMetadata().getNamespace())
.withName(schema.getStatus().getSecretName())
.delete();
} else {
log.info("Delete event ignored for schema '{}', real schema doesn't exist",
schema.getMetadata().getName());
}
return true;
} catch (SQLException e) {
log.error("Error while trying to delete Schema", e);
return false;
}
}
private Connection getConnection() throws SQLException {
return DriverManager.getConnection(format("jdbc:mysql://%1$s:%2$s?user=%3$s&password=%4$s",
System.getenv("MYSQL_HOST"),
System.getenv("MYSQL_PORT") != null ? System.getenv("MYSQL_PORT") : "3306",
System.getenv("MYSQL_USER"),
System.getenv("MYSQL_PASSWORD")));
}
private boolean schemaExists(Connection connection, String schemaName) throws SQLException {
ResultSet resultSet = connection.createStatement().executeQuery(
format("SELECT schema_name FROM information_schema.schemata WHERE schema_name = \"%1$s\"",
schemaName));
return resultSet.first();
}
private boolean userExists(Connection connection, String userName) throws SQLException {
ResultSet resultSet = connection.createStatement().executeQuery(
format("SELECT User FROM mysql.user WHERE User='%1$s'", userName)
);
return resultSet.first();
}
}You can see that this logic is all about managing MySQL using the current version of the schema Custom Resource as input. This is the point of the java-operator-sdk: letting you focus on the business logic of your operator.
When the Custom Resource gets created or updated the operator will:
-
Verify if the database schema already exists.
-
Create the schema if it doesn’t exist in the Mysql database.
-
Update the status field of the Custom Resource with the database url and set the status to CREATED.
-
Create the ConfigMap and Secret, which can be mounted to the application using the database.
Notice that we don’t act based on the type of event (create/update). We don’t even get that information as input, so instead we always check if the schema is created in Mysql.
This is an important point in the operator approach to provisioning: Always check the real state of your resources. Don’t make assumptions. Operators deal with state, which is hard to control and can be changed by different processes, so they have to make very few assumptions in order to be robust.
In our case, we check if the schema exists and create it if not. No other manipulation is necessary, as we don’t support updating an existing schema.
As you can see in the example above, deletion of resources is handled in another method. These are handled in a special way using finalizers in the background, but again the user of the framework doesn’t have to know about that. If you are interested, you can read more about how the framework uses finalizers here.
After the controller class is ready we just need to do a bit of initialisation: Create an operator object and add any controllers to it. Usually we run a single controller in an operator, but it’s possible to pack several of them into a single Java Virtual Machine (JVM) process.
public class MySQLSchemaOperator {
private static final Logger log = LoggerFactory.getLogger(MySQLSchemaOperator.class);
public static void main(String[] args) throws IOException {
log.info("MySQL Schema Operator starting");
Config config = new ConfigBuilder().withNamespace(null).build();
Operator operator = new Operator(new DefaultKubernetesClient(config));
operator.registerControllerForAllNamespaces(new SchemaController());
new FtBasic(
new TkFork(new FkRegex("/health", "ALL GOOD!")), 8080
).start(Exit.NEVER);
}
}
Here I’m using a small library to expose an HTTP endpoint with a health check. This is important when deploying the operator to Kubernetes, so Kubernetes knows how to verify if it’s fully up and running.
Deploying the Operator
To build and deploy our Operator to Kubernetes we need to take the following steps:
-
Configure docker-registry property in
~/.m2/settings.xml -
Build Docker image and push it to the remote registry:
mvn package dockerfile:build dockerfile:push -
Create CustomResourceDefinition on the cluster:
kubectl apply -f crd.yaml -
Create RBAC objects:
kubectl apply -f rbac.yaml -
Deploy the operator:
kubectl apply -f operator-deployment.yaml
Building the Docker Image
The SDK currently doesn’t help with building a Docker image out of your code, but the sample contains a fully functional build using the dockerfile-maven-plugin. You will have to define the docker-registry property either in your settings.xml. I used eu.gcr.io for pushing to the Google Cloud Container Registry.
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.4.12</version>
<configuration>
<repository>${docker-registry}/mysql-schema-operator</repository>
<tag>${project.version}</tag>
<buildArgs>
<JAR_FILE>${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
The plugin needs an actual Dockerfile (and Docker installed), which it will use to execute the Docker build. It will provide the JAR_FILE argument to Docker.
FROM openjdk:12-alpine
ENTRYPOINT ["java", "-jar", "/usr/share/operator/operator.jar"]
ARG JAR_FILE
ADD target/${JAR_FILE} /usr/share/operator/operator.jar
This build also assumes that the artifact produced by maven package is an executable jar file. In the example pom file I use the shader plugin, but you can also use Spring Boot or a number of other methods to do this.
The Deployment Resource: Running the Operator
Our operator will be deployed as a normal deployment on Kubernetes. This will ensure there is always a single instance of the operator running. The ’Recreate’ upgrade strategy will make sure that the old version gets shut down first before a new version starts up during an upgrade.
apiVersion: v1
kind: Namespace
metadata:
name: mysql-schema-operator
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-schema-operator
namespace: mysql-schema-operator
spec:
selector:
matchLabels:
app: mysql-schema-operator
replicas: 1 # we always run a single replica of the operator to avoid duplicate handling of events
strategy:
type: Recreate # during an upgrade the operator will shut down before the new version comes up to prevent two instances running at the same time
template:
metadata:
labels:
app: mysql-schema-operator
spec:
serviceAccount: mysql-schema-operator # specify the ServiceAccount under which's RBAC persmissions the operator will be executed under
containers:
- name: operator
image: ${DOCKER_REGISTRY}/mysql-schema-operator:${OPERATOR_VERSION}
imagePullPolicy: Always
ports:
- containerPort: 80
env:
- name: MYSQL_HOST
value: mysql.mysql # assuming the MySQL server runs in a namespace called "mysql" on Kubernetes
- name: MYSQL_USER
value: root
- name: MYSQL_PASSWORD
value: password # sample-level security
readinessProbe:
httpGet:
path: /health # when this returns 200 the operator is considered up and running
port: 8080
initialDelaySeconds: 1
timeoutSeconds: 1
livenessProbe:
httpGet:
path: /health # when this endpoint doesn't return 200 the operator is considered broken and get's restarted
port: 8080
initialDelaySeconds: 30
timeoutSeconds: 1The connection to the MySQL database server is configured using environment variables. Please don’t use this setup in production! The ‘mysql.mysql’ hostname refers to a Mysql database running on Kubernetes in the mysql namespace.
If you want to run MySQL in this namespace on Kubernetes, apply the yaml file provided with the example. Please note that this MySQL will only have ephemeral storage assigned, so it will lose all data when the pod is killed.
kubectl apply -f k8s/mysql.yamlPermissions to Access the Kubernetes API
Most applications running on Kubernetes don’t need access to the Kubernetes API. However, operators— by definition— do, because they work with resources defined and updated in the API. It is unavoidable to deal with the Kubernetes RBAC (Role Based Access Control) mechanism.
The ClusterRole resource defines a group of permissions. It gives access to do all operations on MySQLSchema resources as well as listing and getting CustomResourceDefinitions. The Operator will of course need to watch all schema resources on the cluster as well as update them when the status changes. As for the CustomResourceDefinitions, the operator needs to get it’s own CRD on startup to get some metadata. This might not be necessary in a future release of the SDK.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: mysql-schema-operator
rules:
- apiGroups:
- mysql.sample.javaoperatorsdk
resources:
- schemas
verbs:
- "*"
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- "get"
- "list"
This is the ServiceAccount under which the operator will be executing. It’s just a name that connects the running pod of the operator to the permissions it has to the API server.
apiVersion: v1
kind: ServiceAccount
metadata:
name: mysql-schema-operator
namespace: mysql-schema-operator
Finally, the ClusterRoleBinding connects the ServiceAccount to the ClusterRole. This way any pod running under ServiceAccount mysql-schema-operator will assume the ClusterRole of the same name and the permissions described above.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: operator-admin
subjects:
- kind: ServiceAccount
name: mysql-schema-operator
namespace: mysql-schema-operator
roleRef:
kind: ClusterRole
name: mysql-schema-operator
apiGroup: ""
Here is a diagram explaining the relationships between different RBAC objects:

Create a MySQL Schema using the Operator
Once it’s deployed, you can verify if the Operator is running correctly by listing the running Pods:
kubectl get pods -n mysql-schema-operator
You should see 1/1 ready Pods:

You can also tail the logs of the Operator with:
kubectl logs -f -n mysql-schema-operator mysql-schema-operator-957bd9d6d-h9tqn
Finally you can create the MySQLSchema Custom Resource by applying the appropriate yaml file. You can edit it to set the schema name.
kubectl apply -f k8s/example.yaml
Once the MySQLSchema resource is created, the operator should connect the MySQL server and create the real schema and a database user that can access it. It should create a Kubernetes Secret with the credentials for accessing the database, which you can mount into your application deployment. Go here for more details.
TL;DR
A flexible and fully automated process to provision databases is a must-have for any modern company with multiple development teams. In this example, we have shown how to implement such a process using the operator pattern on Kubernetes, writing the logic in Java. Supported by fabric8 and the java-operator-sdk, writing Kubernetes operators becomes easy for anyone familiar with Java programming.
Resources
- A deep dive into the java-operator-sdk
- MySQL Schema operator sample
- More about Kubernetes operators in general
Photo by Museums Victoria on Unsplash
