

The finance team at CS has recently automated a bunch of repetitive manual work with the aid of some custom Python, Apache Beam, and Google Cloud Functions. But how did we get here?
Jobs in finance can be relatively tedious, as your workload tends to be repetitive. Each month you need to invoice clients, capture expenses, generate reports and chase people to submit timesheets. Whilst there is a certain charm in knowing what you are going to do each month, some jobs are just boring, i.e. copying data between spreadsheets. It is also error prone if you lose concentration; something that is easy to do with dull work.
Working within an engineering-led company gives you a unique perspective. It's always fascinating to see how iterative and repetitive processes can generally be automated. Unlike humans, computers are good at endlessly doing repetitive tasks. Why are finance teams not approaching their work in the same way? For 10 Euros on Udemy you can gain enough knowledge to write a bit of Python. This is where the story starts.
Couldn’t you just have used an add-on?
Container Solutions has been using Google Workspace since inception but uses Microsoft Business Central Dynamics 365 (BC365) in the finance team. This is the “Source Of Truth”, where all financial transactions are logged and reports are generated.
BC365 has an extensive add-ons marketplace, and there was the option for finance to use one of these to connect BC365 to Excel. However, the majority of the finance team use Macs and the MacOS version of Excel did not support this particular add-on.
A second approach we considered was to use the on-line Excel version with this add-on. A challenge for us here, however, is that Container Solutions has branches in multiple countries which operate as separate legal entities. In BC365 we define these as separate companies. The on-line Excel approach did work, but it uses a connection/workbook per company and most of our reporting is done with an aggregation across these multiple companies. It quickly got complex and unwieldy.
In addition, whilst Microsoft does have reporting tools, the rest of the company does not use BC365 except for timesheet submissions and prefers to have their reports in Google Sheets. The aim was to empower employees to be data aware, not force new tooling onto them.
Due to the nature of Microsoft integrations and the looming problem of Container Solutions potentially needing to pull data from sources outside of the Microsoft ecosystem, it made sense to start looking into a Data Mesh architecture where all the data is extrapolated to a single data warehouse. This meant aggregations could be made across different datasets allowing Container Solutions to remain data driven.
Implementation
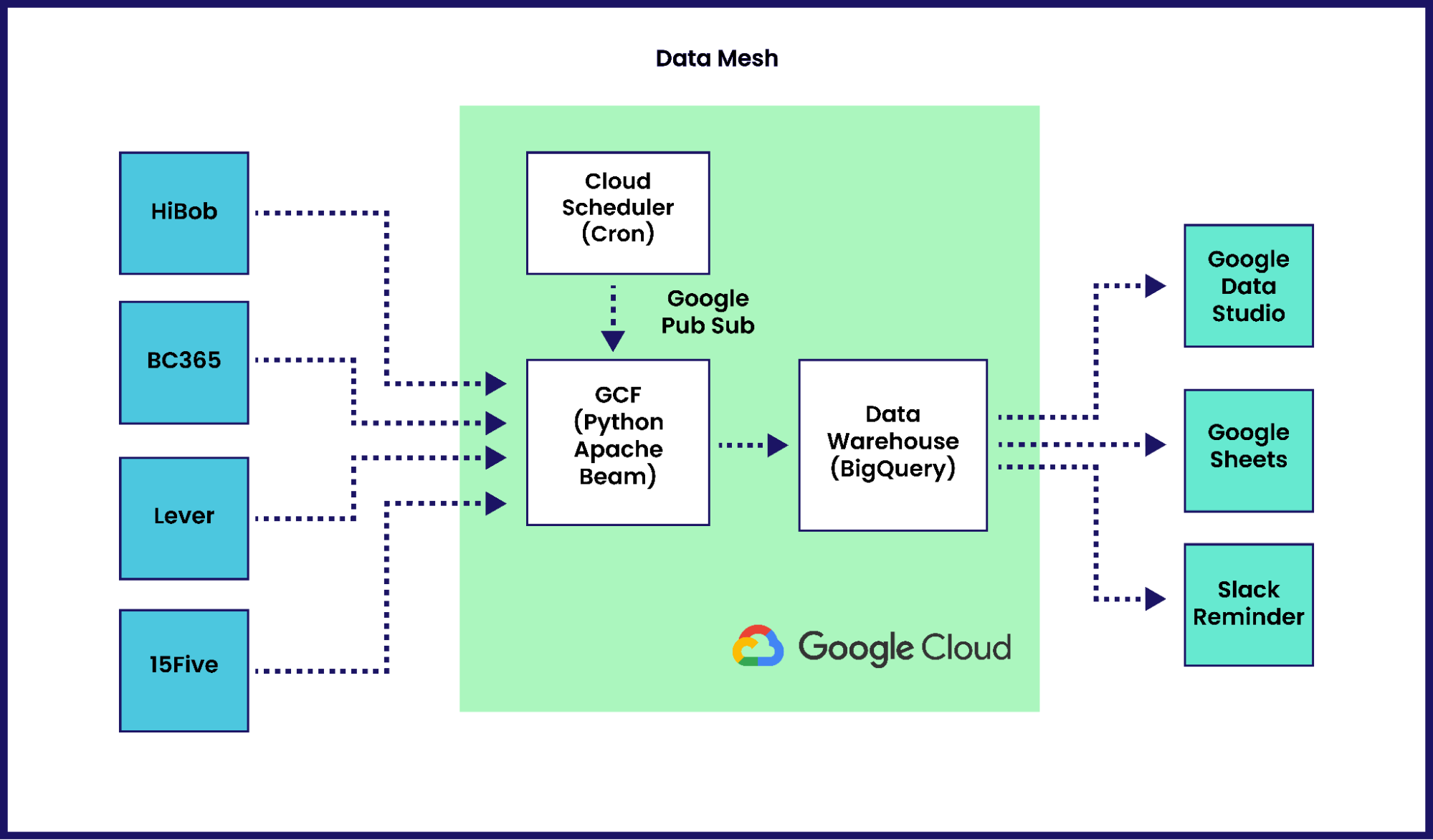
Diving into the implementation, Google BigQuery seemed to be exactly what was needed. It would allow for the migration of multiple sources of data to a single data warehouse, whilst being easy to connect the data from BigQuery to Google tools like Looker Studio and Google Sheets using custom BigQuery SQL scripts if needed for reporting.
BC365 exposes its data via REST web services which allowed for the creation of Python scripts to pull the data and inject it into BigQuery. Given the aforementioned use of multiple companies within BC365, this required a new field to be added to the data before injecting it into BigQuery, separating the different companies data but allowing for the migration of the same endpoints into a single table. This provided the ability to have a single table for something like timesheets even though people submitted their timesheets in different entities.
We chose Apache Beam to handle data ingestion, creating a custom Python library for it that pulls data from BC365. Whilst a lot of its features are not currently used, Beam still offered:
- A unified script that is able to scale
- Support for multiple back ends (Apache Spark, Apache Flink, Google Dataflow etc)
- A standardised open-source framework for ETL pipelines
Kubernetes vs Serverless
The next big question was whether to use Kubernetes or take a severless approach. We decided to go serverless and use Google Cloud Functions (GCFs). Although GCFs still have some restrictions—such as cold starts and time restrictions—they could still meet our requirements, and a huge advantage to using them is that it allows the team to trigger a pipeline using the Job Scheduler instead of running a Cronjob in Kubernetes.
It was also important to keep in mind the maintenance cost of any setup; a finance team maintaining Kubernetes Clusters didn’t seem optimal. By contrast, the Job Scheduler offers a user-friendly interface for any members of the team not familiar with a terminal to run the scripts manually if needed between the scheduled times. It also allows team members to update the data on live reports with the click of a button.
Using Google Cloud Platform to run the pipelines, store the data and generate all reporting allows for seamless integrations without data going through public networks between the scripts and the database. It also allows for pulling data into the various reporting dashboards without leaving Google Cloud’s domain of trust.
Reporting
Once all the data was stored it was possible to start creating reports. The reports needed to be as close to real time as possible, as well as GDPR friendly. Looker Studio has the advantage of being able to adjust display filters such as date whilst not needing to provide access to the BigQuery tables, thus allowing for reporting without a concern of providing access to confidential data. This is a big issue with Google Sheets as anybody that needs to refresh the data needs to have permissions on the BigQuery tables.
The approach has been very successful. Finance has clean, usable data that allows reporting to be provided to the whole organisation as needed. All of the data is in a single format and place, and any new questions that arise from business needs can be queried against this dataset. The other big advantages are that new data sources can be added with minimal effort, and the new system allows for reporting across multiple tools.
An unforeseen benefit of this work has been the ability to automatically alert team members via Slack when they need to submit timesheets for invoicing or revenue calculations, taking away some of the overhead from the finance team manually reaching out to people.
The biggest lesson learnt through this journey is how the merging of non-technical and technical skill sets can greatly enhance the performance of any team (not just engineering teams) and learning these skills is possible for anyone. Take a look at all of those manual tasks that you begrudgingly do and see if automation could be right for you.
