

If I bumped into Zuck’s avatar at the virtual water cooler I’d quit on the spot. But the recent name change at Facebook, Microsoft’s enthusiasm, Nvidia’s Omniverse and broader industry support mean we should at least peel back the lid on the “metaverse” to see what the fuss is about.
Spoiler alert: It’s not VR. Collaboration with your colleagues’ avatars may yet become a thing, but you’d be right to point to Microsoft’s Hololens or Meta’s AR glasses and say “We’ve seen this (train wreck) before”. Perhaps the seductive simplicity of the virtual world is an excuse to avoid the awkward realities of the physical.
But if, like me, you’re sceptical, there is still a powerful lesson in the metaverse and its avatars: There is a much better way to build enterprise apps. Apps that always stay in-sync with the real world. Avatars are digital twins of people, and if virtual Zuck doesn’t move in sync with real Zuck’s voice, that’s extra creepy. So, if we can make avatars move in-sync with humans, how come you can’t see your supply chain in real time? How come you can’t see the wedged load-balancer that’s bringing your site to its knees, and kick it (virtually, with your foot) to restart it? How come it didn’t get restarted automatically, then tell you? There’s no reason that the concepts and tech that make the metaverse work shouldn’t be applied to every enterprise product and process, and all infrastructure. After all, it’s all highly instrumented and controllable.
I aim to show you how your streams of events can be used to build and dynamically update digital twins of your “things” (instead of avatars) that analyze, learn and predict as data flows. These digital twins that learn can accelerate decisions from days to milliseconds. They can debug complex infrastructure problems, surface safety issues, anticipate problems and help organizations run more efficiently. And, like Zuck’s avatar, they always stay in-sync with the real world—an absolute requirement for the next level of automation. We can use them to build apps that decide, respond to the physical world, and then tell humans what they have done.
I’m going to dig into the architecture of an open source platform called Swim that lets you easily derive continuous intelligence from your event streams. The largest Swim application of which I’m aware analyzes over 4PB per day (10GB/s continuous) for a US mobile carrier, providing real-time insights into network performance for 150M devices. It uses only 40 servers, and delivers insights within 10ms.
Event Driven Analysis
Often architects think database-first—event data is spooled away on disk for later analysis. That’s a pattern we have to ditch, for many reasons:
- Organizations aren’t just dealing with big data—they are drowning in boundless data. Applications need to analyze, learn, predict and respond on-the-fly, because it’s usually not possible to go back later. So, we need an “analyze, react and then store” approach.
-
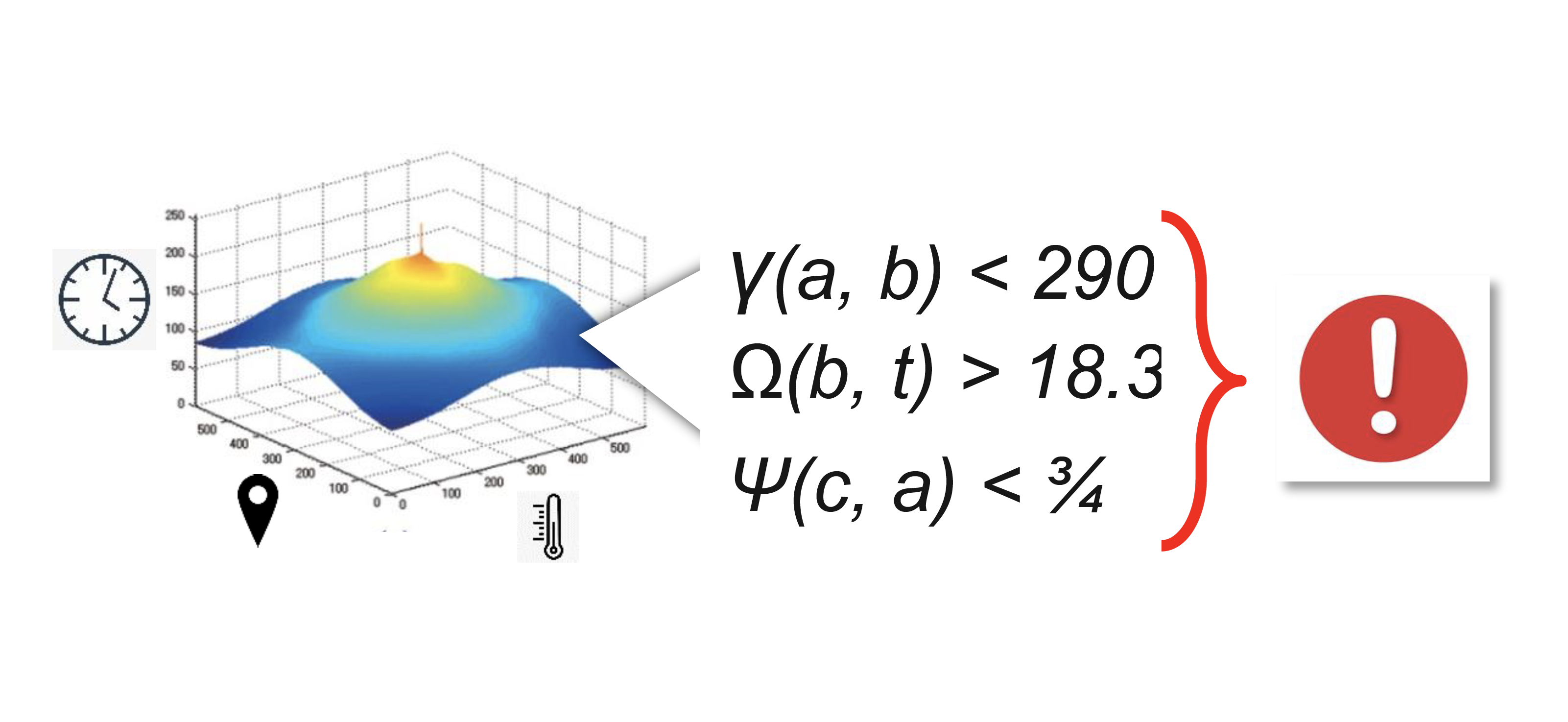
- These relationships between event sources—like “correlated”or “near”- must be re-evaluated on every new event, and because they may be fleeting, they can’t easily be captured in a database. Cascading dependencies (eg: if you move, you’re now near me; or computations based on independently changing variables, perhaps looking for correlation) are a major challenge for database oriented architectures because when a row changes, a materialized view based on a cross-column computation including other rows, is not automatically re-calculated by the database.
In a database, materialized views are only recomputed when they are viewed by a client (these are OLAP-style queries). But we may want a process to add water whenever the rising temperature in one tank is correlated (in time) with increased pressure in another. Databases don’t (can’t because really this is the domain of application logic) re-evaluate every materialized view or OLAP-style query whenever any row changes. So even in-memory databases fail here. Finally, relationships between data sources may be transient, probabilistic or even predicted (eg: A GPS event might be used to predict that A will be close to B within t, given its current velocity)
- These relationships between event sources—like “correlated”or “near”- must be re-evaluated on every new event, and because they may be fleeting, they can’t easily be captured in a database. Cascading dependencies (eg: if you move, you’re now near me; or computations based on independently changing variables, perhaps looking for correlation) are a major challenge for database oriented architectures because when a row changes, a materialized view based on a cross-column computation including other rows, is not automatically re-calculated by the database.
Databases trade off Consistency, Availability, and Partition tolerance (CAP) to deliver ACID (Atomic, Consistent, Isolated and Durable) transactions, but they don't consider timeliness as an element of correctness. For apps that have to stay in-sync, that’s a problem: “Hit the brakes!” is not helpful when an autonomous car is already in the intersection. Time is inescapable and an application that falls behind the real-world is a failure.
Database-first thinking leads to apps that can’t keep up, for one simple reason: accessing a database (whether local or “in the cloud”) is literally a million times slower than memory, so finding complex relationships between millions of entities is just too slow. Events are updates to the states of data sources, but they shouldn’t be treated like transactions. Keeping replicas of a distributed database in sync is useful for apps where many users compete to update shared state, for example in seat booking. But complex distributed quorums and locking protocols like Raft or Paxos are too expensive for updates to the temperature of a tank, measured 10 times per second.
A Solution: Digital Twins That Learn
Apps that stay in-sync with the real world have to continuously analyze boundless streams of events that can’t be paused. Thankfully, there is a well established pattern that is useful for “digital twins that learn”, namely the Actor Model. Languages like Erlang and Pony, as well as toolkits like Akka are well known examples. But they have a couple of major drawbacks: Actors execute in a single application address space, and use message passing to communicate.
At Swim we have enhanced the classical actor model to support distributed execution—actors can be widely distributed and actors and their APIs are simply addressed using the machinery of the web—URIs. Streaming actors let applications stay coherent—consistent and always in-sync with the world.
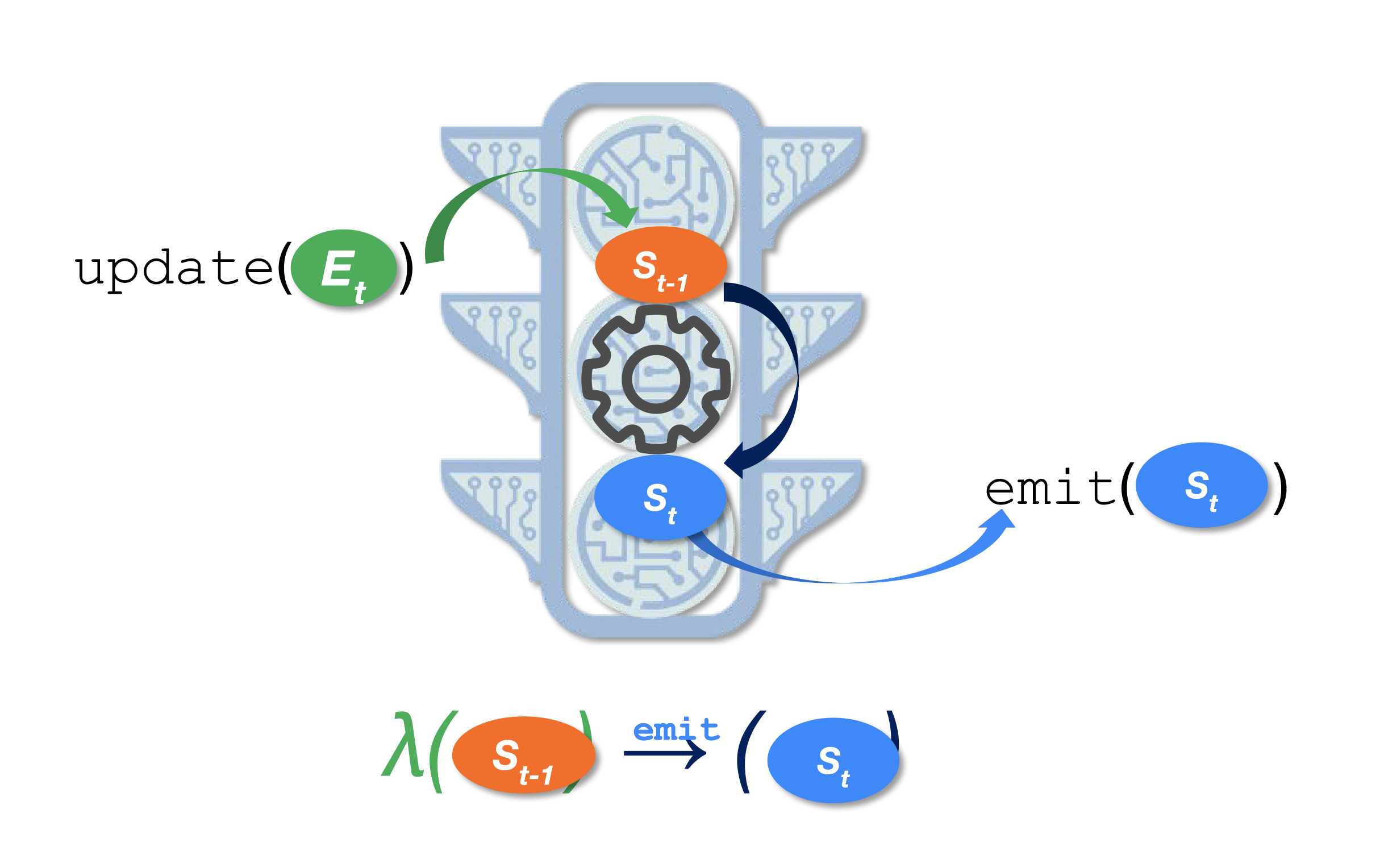
Streaming actors are like concurrent, stateful lambdas that receive events, compute and stream their results to other actors that link (subscribe) to their streaming APIs. They dynamically build a dataflow graph of linked actors that analyze, learn and predict as data flows.
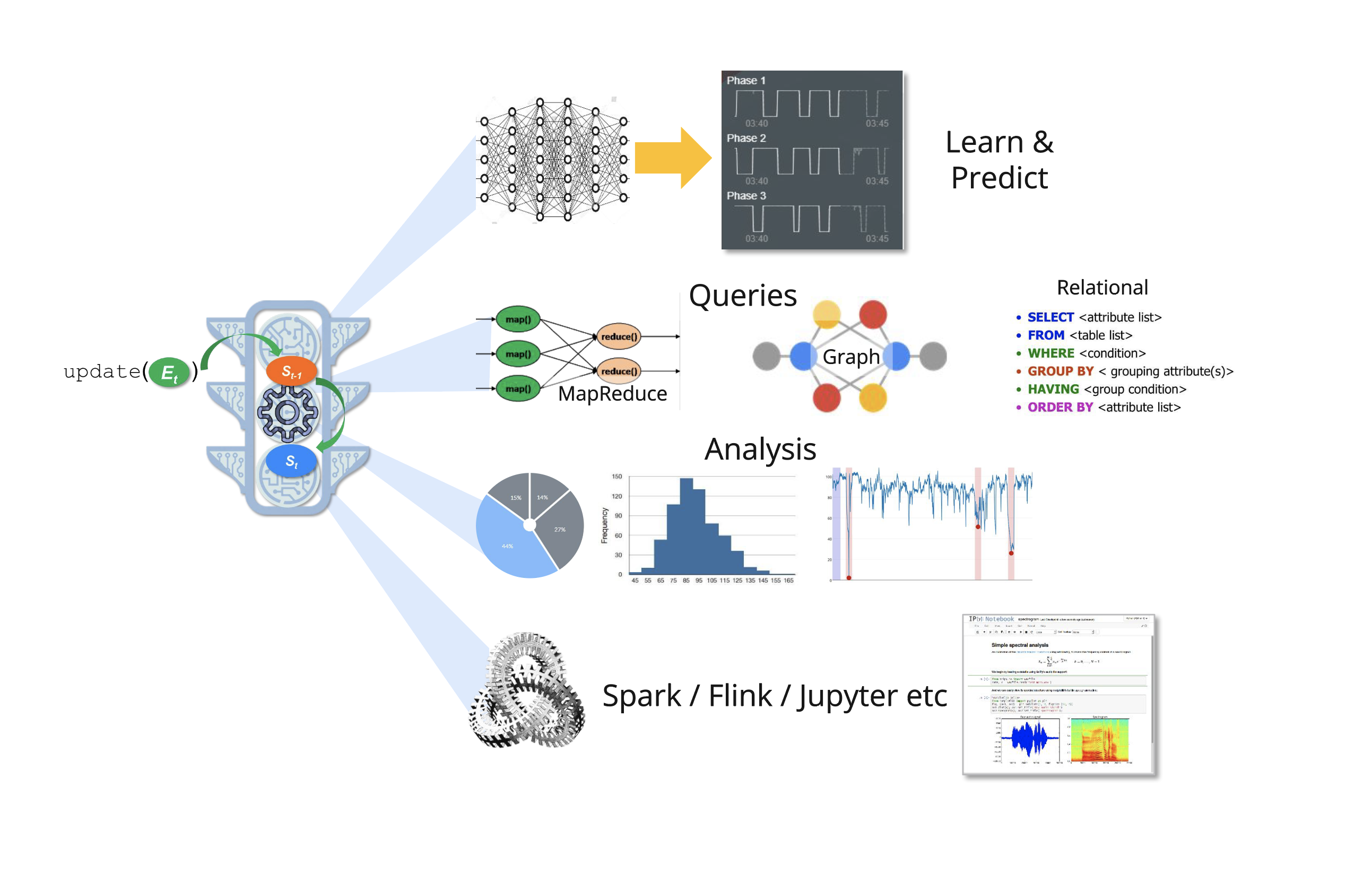
- Each streaming actor is either a stateful “digital twin” of a data source that atomically updates its own state when it receives an event, or a continuously current materialized view derived from the states of many other streaming actors.
- Each streaming actor continuously computes, using its own state and the states of other actors to which it is linked. It evaluates complex parametric functions to discover relationships between itself and other actors, like “near”, or “correlated”. Related actors dynamically link, building an in-memory dataflow graph of real-time dependencies.
- Because all actors are concurrent, they can compute whenever the state of an actor to which they are linked is modified (or at any other time, such as on a window boundary).
- Browser-based objects that render remote actors can subscribe to their streaming APIs to receive continuous updates that allow them to render real-time UIs. This therefore also puts every actor on the web, and allows browser based UIs to also update in sync with the real world.
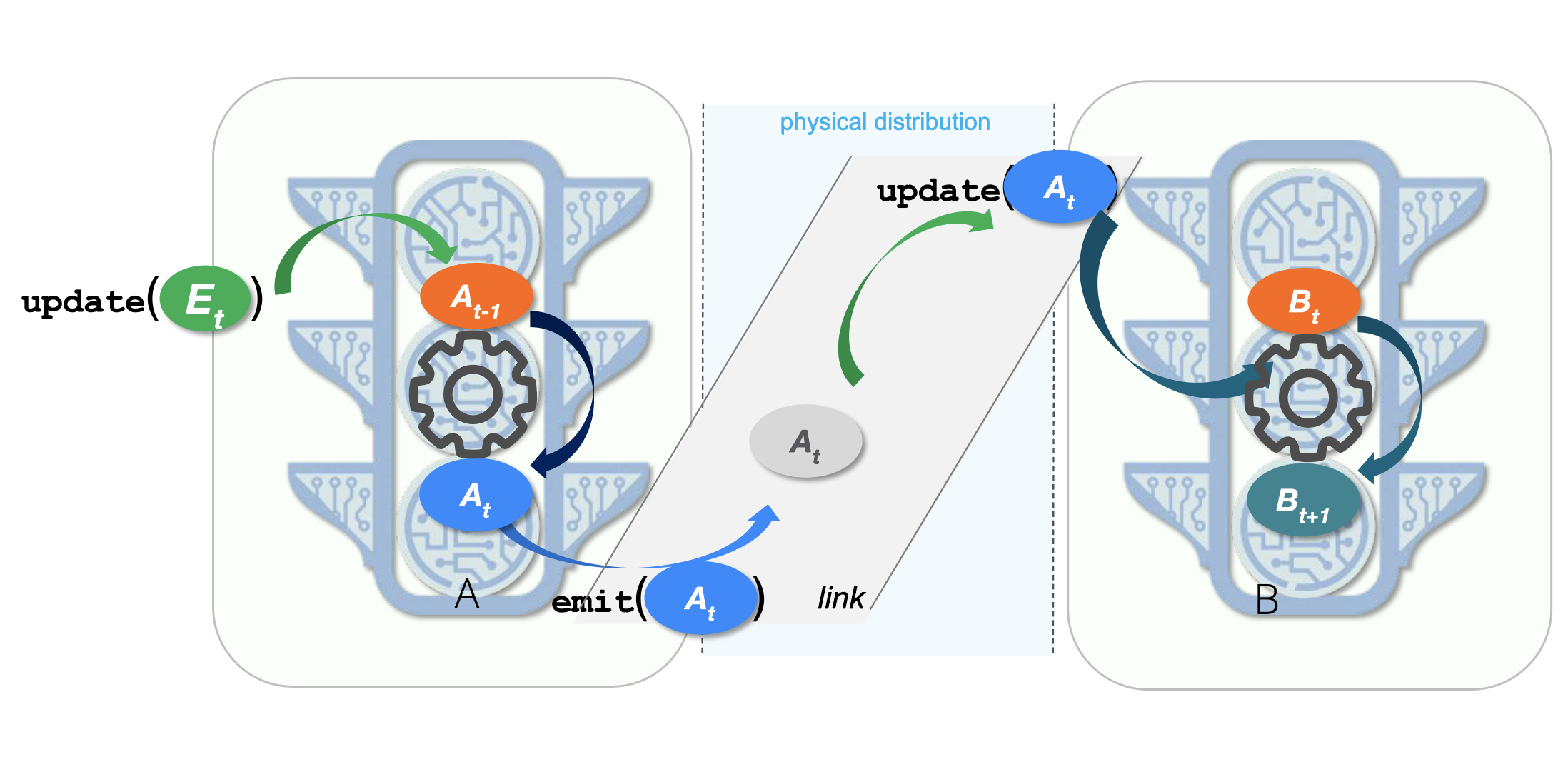
The runtime hides the complexity of application creation, distribution, execution, scaling, and resilience, while offering developers the benefits of the single address-space actor model of Erlang. Developers need care only about the application logic, not where it runs or how it scales.
The runtime assembles an application on-the-fly directly from streaming event data, creating a new actor for each source, and linking it into a dataflow graph of actors that together represent the application. A link is a subscription to an actor’s streaming API—a URI binding. When actor A links to an API offered by actor B, the application runtime records the link; whenever actor A changes its state, the runtime streams the changed state from A to B.
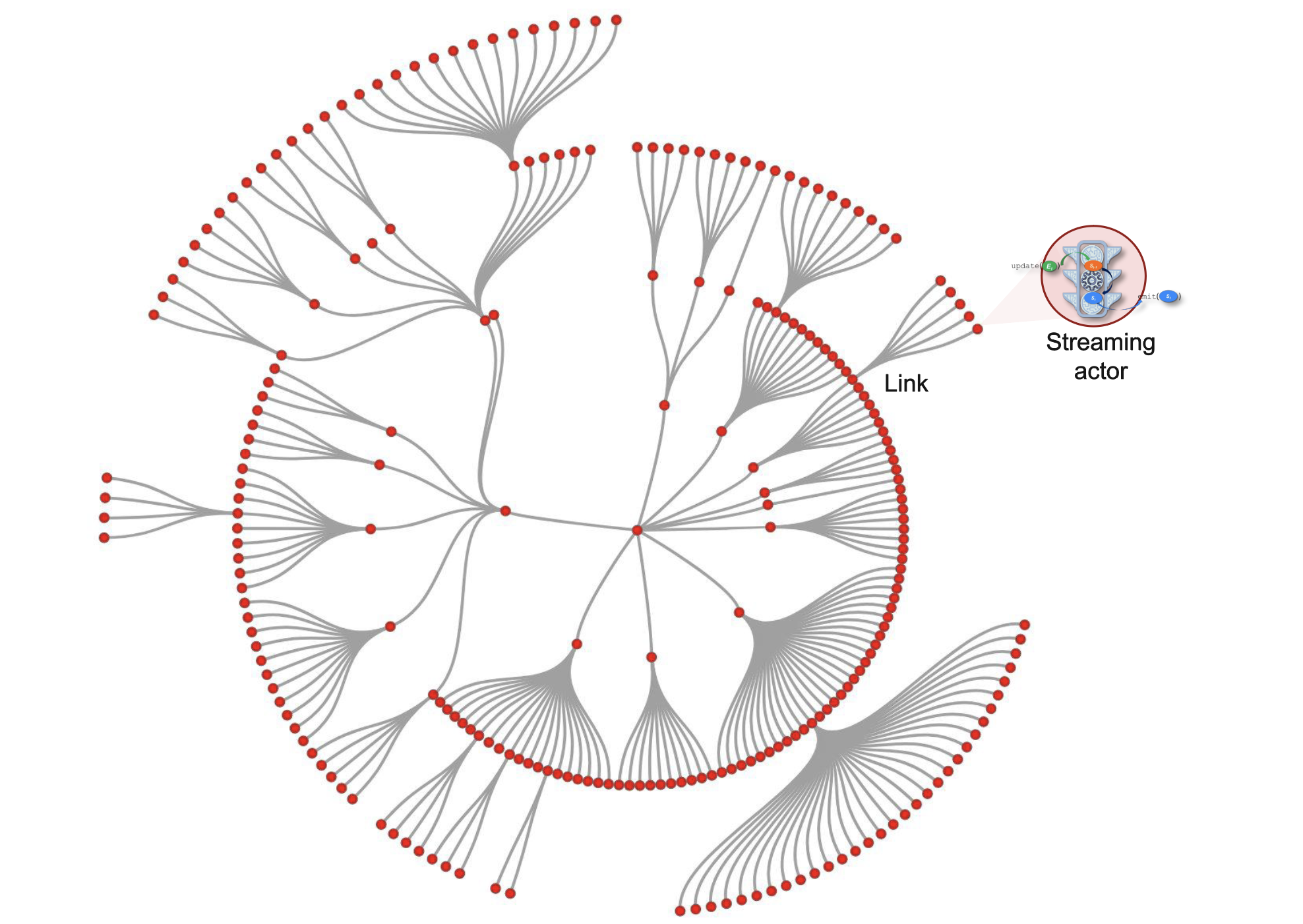
The magic of linking is that it builds a fluid, distributed, in-memory dataflow graph whose vertices are actors (running somewhere in the distributed application) that concurrently compute in a “local" context (meaning “in the same subgraph”), that often relates to a parametric relationship such as “near” or “correlated to”.
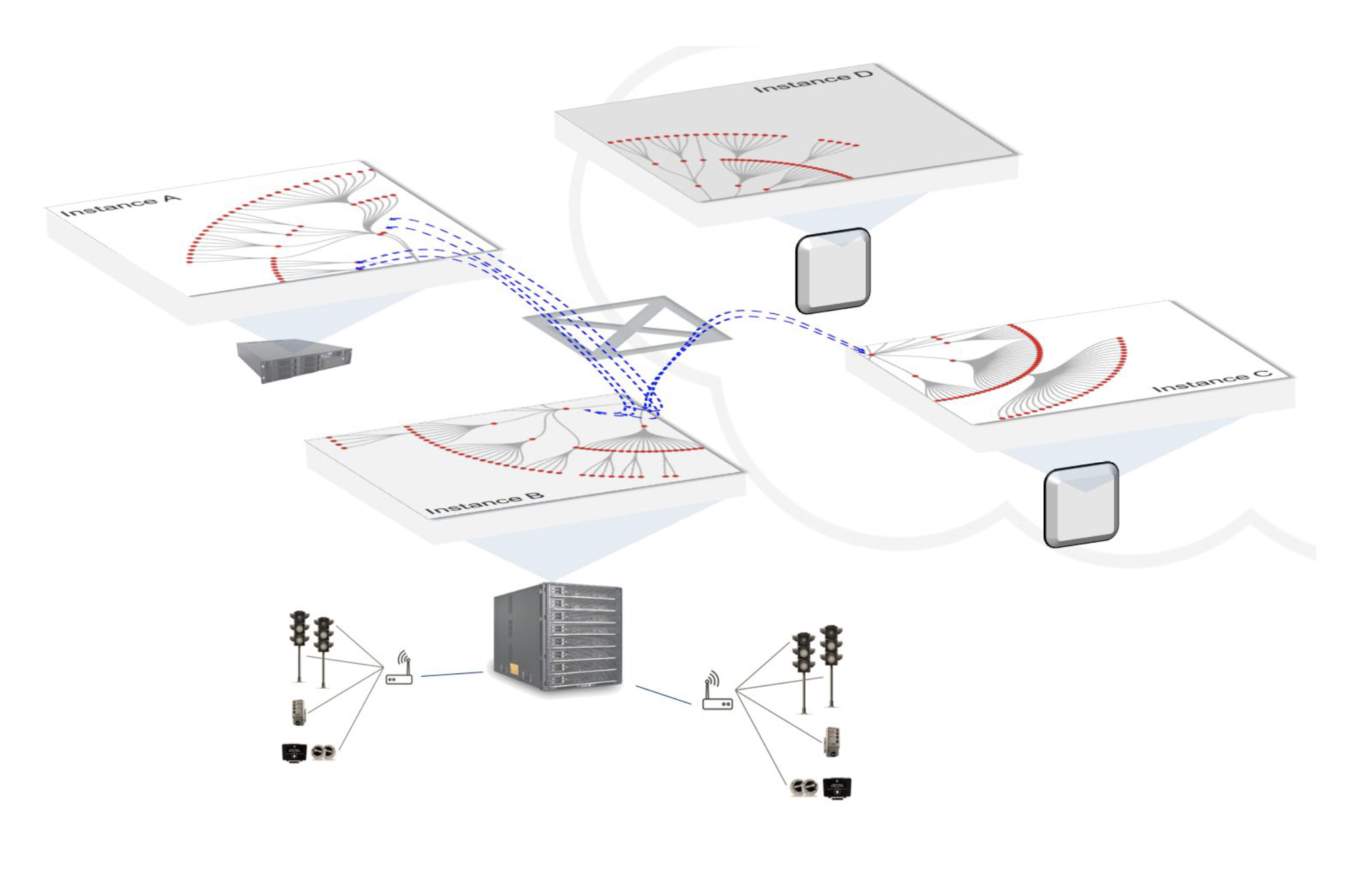
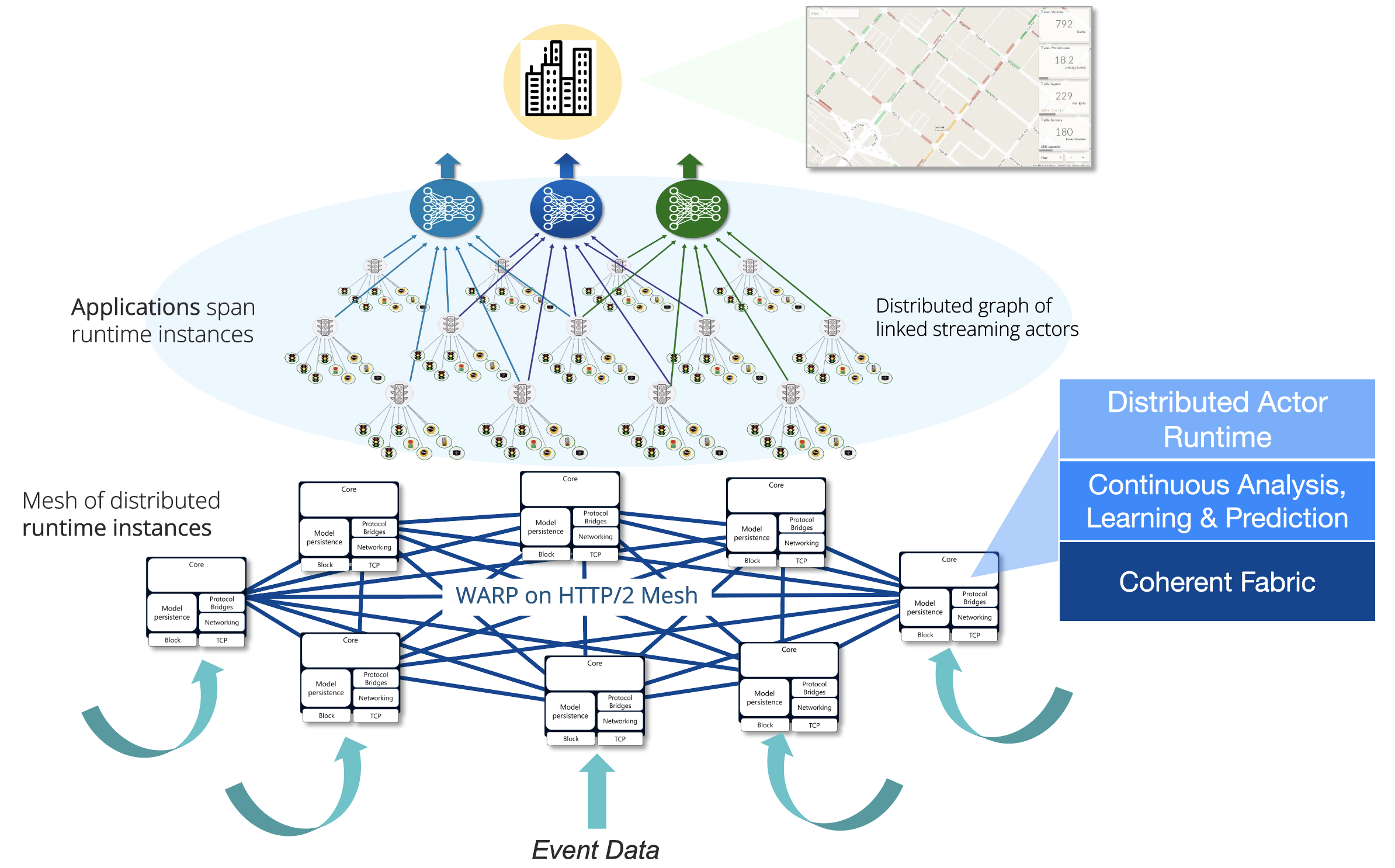
A Swim application is a thus distributed, in-memory dataflow graph, built from data, in which each vertex is a concurrent streaming actor that continuously computes on its inputs and emits a stream of state changes to subscribing actors that wish to be notified of changes. The graph itself—the set of actors—is distributed across runtime instances of the distributed application. Since streaming APIs are just URIs, an actor can run anywhere but is dynamically tracked by the runtime. In fact, actors can move in real-time to balance load or to nodes with the right resources, and their links still follow them.
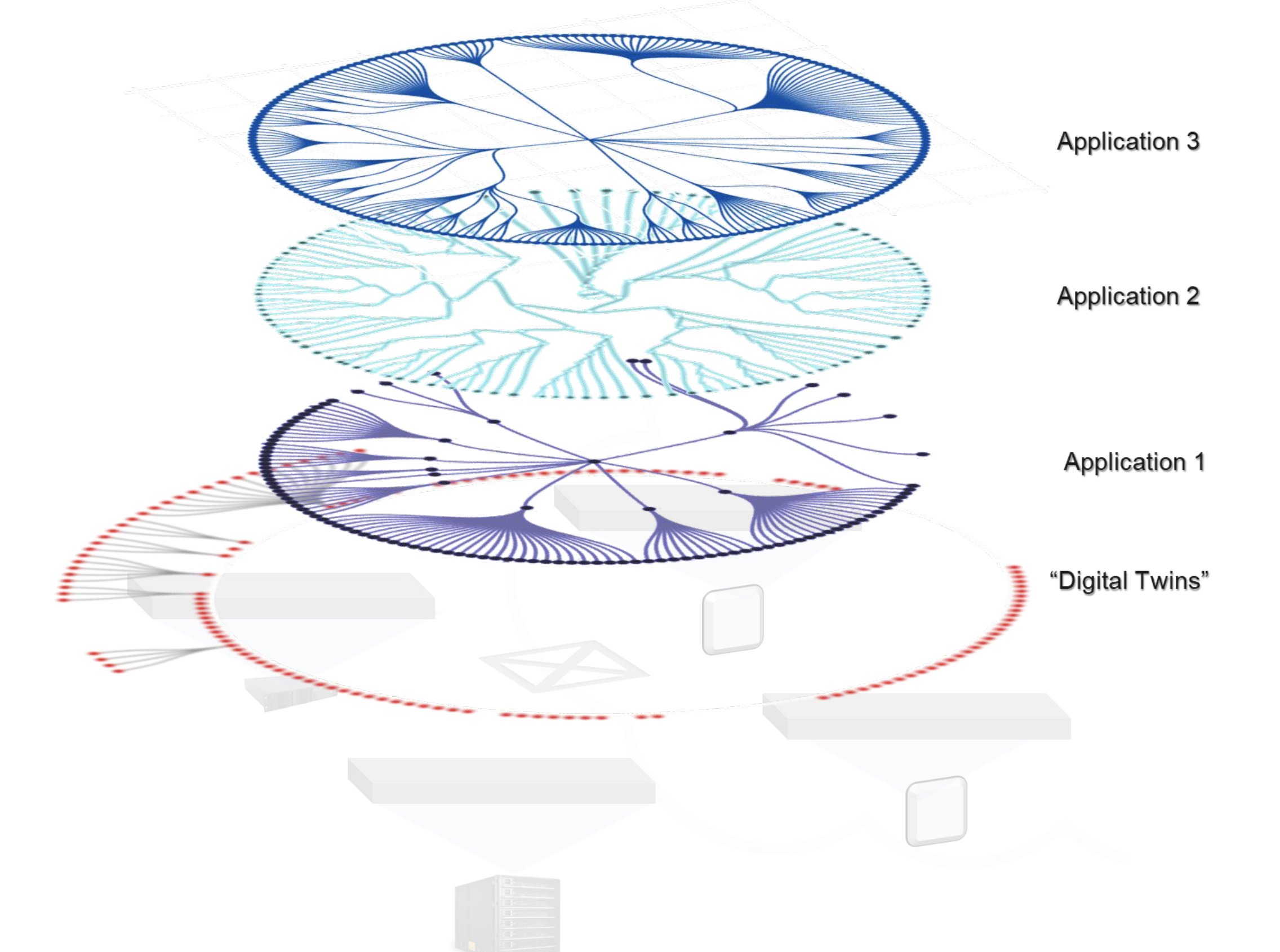
The runtime can host (run) many different applications concurrently. Each is a plane—a set of linked actors—that often share leaves of the graph, since these are typically stateful digital twins of event sources.
Distributed Execution
The dataflow graph is created and mapped onto available execution resources in a way that satisfies the constraints of both actors (leaves of the graph should be close to data sources, while complex materialized views that need lots of computational resources might run in the cloud) and the application overall—since it must stay in sync with the real-world.
The runtime dynamically creates and distributes streaming actors over available instances, preferentially placing actors in a “local” context that minimizes latency of input events to enable fast local analysis and responses—close to their data sources. This has an additional benefit under partitioning—geographically local analysis and response can continue when remote instances are cut off. Actors are periodically load-balanced and moved in real-time to runtime instances that can best suit their CPU, memory and other resource needs, such as GPUs.
Streaming actors combine state and code into an active, distributed, in-memory dataflow graph whose access latency is the speed of memory—often a million times faster than a database access, allowing applications to stay in-sync with the real-world. Actors enforce atomicity for their own state updates, but permit concurrent reads by other actors in the same runtime instance that need to use their state, and by the runtime—which streams state updates to remote instances.
Since ACIDity is now an actor-specific concern, this affects availability in an interesting way: Loss of an instance means that the distributed application dataflow graph loses some of its vertices—corresponding to the actors that were running on the lost instance. Thus the mapping of actors to runtime instances makes partitioning (and therefore availability and consistency) granular, actor-specific concerns. Each instance keeps a replica of the state of every remote actor to which a local actor is linked. Loss of a remote actor means that at some point the replica will become stale, offering an opportunity for a semantically useful local reaction.
By making availability a granular, actor-specific concern, the application can pursue the best strategies for resilience at many layers in the event of a failure. Actors offer strong safety and consistency in a local context (analyzing events close to data sources where accuracy and real-time responses are important), while ensuring strong eventual consistency under partitioning. The actor model eliminates transactional overhead and focuses on actor dependencies in the dataflow graph.
Swim runtime instances are all identical. They run on the Graal VM, and applications are typically written in Java. Each Swim runtime connects to all others in the deployment, building a complete mesh of HTTP/2 interconnected instances. Each instance supports capabilities for remote state synchronization, analysis of unbounded data, and offers a runtime for streaming actors, including comprehensive instrumentation for platform operation.
Building the Enterprise Metaverse
Zuck’s avatar has to move in time with real Zuck. Staying in time with the real world is vital. It’s crucial too for a self-driving car that has to avoid traffic snarl-ups, and for a pick-and-place assembly robot that’s drifting from accurate placement of chips on a motherboard. In distributed enterprise systems it is just not feasible to “store then analyze” events and automate the response.
The next frontier in enterprise computing is all about data-driven automation, so applications must analyze, learn, and predict on the fly—directly from streaming data. For accuracy, insights need to be computed from a dynamic model of the entire system. Parametric relationships between event sources call for continuous evaluation using a stateful, actor-based paradigm, to dynamically find relationships and evaluate relationships in time and space. Actor-based applications can assemble themselves from data and dynamically load-balance to optimize performance, simplifying operations. Stateful, distributed, in-memory actor-based applications are fast and efficient. Most importantly, they operate at the speed of memory, a million times faster than database apps, so they stay in-sync with the real world.