Implementing microservices holds many promises, be it faster time to market for new features, more scalable and less coupled architectures or enabling teams to apply the best technology to each individual problem.
But rolling out a microservice strategy in an organisation is a multidisciplinary exercise. On the surface, it looks like mostly architecture work, but in fact there is a lot more to it to make it successful. At the same time, new security challenges arise that have to be dealt with and might be difficult to tackle by traditional means.
More security related content is available on our security page.
The term “microservices” is quite buzzword-laden. So before we dig any deeper, instead of reciting some made-up definition off the Internet, I rather want to look at the properties that microservice implementations generally exhibit. As of this writing, these properties can be described as follows:
The individual services are small, and therefore there are many of them. They collaborate over the network - often “REST over HTTP”. Each service is possibly built with different technologies, by a single autonomous team that takes end-to-end responsibility for it. Those teams follow DevOps and Continuous Delivery principles using containers to deploy and run them.
As of January 2016, it is containers, maybe in 2 years we’ll all be using unikernels instead, who knows…
A question that also usually comes up is “how small is a single service?”. The common, but unsatisfying answer is “it depends”, a better one is: Small enough that a mapping between multiple services to a single team is still manageable for the team. Team size tends to be significantly less than 10 people, a popular metaphor and guideline is Amazon's “two pizza team”.
So in short:
many small services
talking over the network
built with different technologies
by autonomous teams with end-to-end responsibility
doing DevOps and Continuous Delivery
using containers
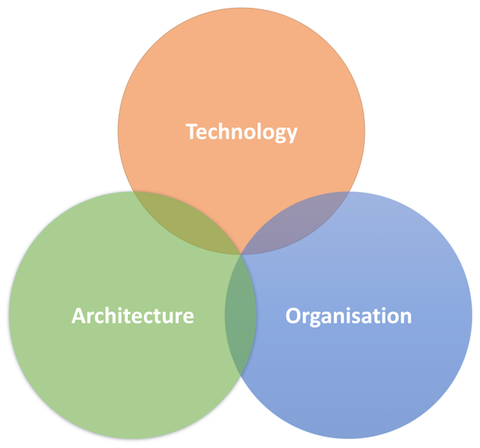
Now when we look at these properties more closely, we can easily see that they are not all about architecture. They are also about specific technology decisions and organisational issues:
“many small services talking over the network” clearly indicates architectural concerns, such as service boundaries, domain driven design or infrastructure and network architecture.
“built with different technologies” and “using containers” touches technology, like programming languages, frameworks, deployment and operations.
“by autonomous teams with end-to-end responsibility, doing DevOps and Continuous Delivery” sounds like organisational and cultural topics, such as development processes and practices, and how individual teams are organised and interact with the rest of the organisation.
Therefore, when we are looking at security, we also need to look at these 3 aspects: Architecture, Technology and Organisation.
Let's dissect each of those items to see how it impacts information security:
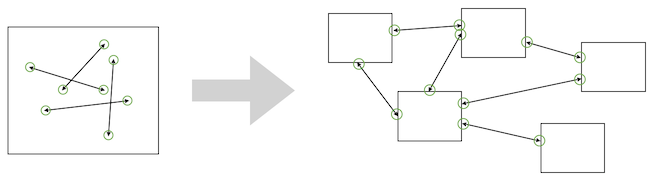
In a monolith, you have one single thing to secure - that’s manageable.
With microservices, the attack surface increases manifold. For each one, you need to take care of all the weaknesses they might expose. Be it flaws in their design, simple security related bugs, or plain old vulnerabilities in supporting libraries or their runtime environment. Also you need to think about security testing for each one of them.
In a monolithic architecture, in order to allow the different components of your application to collaborate, you just have method calls within the application's OS process.
With microservices, you are exposing internal APIs of the logical application over the network and need to ensure they can’t be called with malicious intent. That requires a lot more effort to secure compared to a monolithic design.
A simple example: an internal method returning a list of objects will usually return as many objects as there are to return - the list is technically just a pointer to the respective memory address, so no big deal. Doing the same in your microservice API without enforcing any limits will probably lead to a Denial-of-Service weakness as the service has to serialise and send a possibly huge number of objects.
A monolith uses a well known set of technologies, maybe not only one technology, because the front-end might be written in something else than the backend, but the number of technologies involved is small and your company has maybe even standardised on them and has vulnerability management in place.
Now with microservices, you can end up with a whole zoo of technologies. And even if you force some standardisation on what can be used, there still will be many different versions of the chosen technology stack around, because individual services will have different life-cycles. Some will have been created earlier than others with older versions of java, nodejs or PHP.
How do you keep track of all the vulnerabilities they might have? And how do you apply patches? Updating every service immediately when a new version comes out is not going to be practical with a large number of services.
In traditional approaches towards security, you have the concept of control gates:
Each step in a large software project involves a committee of security experts, that assess if a project can move forward and what measures in terms of risk management and treatment, security controls and security testing have to be taken. The project cannot move forward without that committee signing off that everything is “secure” (at least secure on paper).
Compare that to the microservice approach, which requires team autonomy and end-to-end responsibility.
How do you ensure the team does things like threat modelling and risk assessment? How and when are security experts involved?
Incidents like “Oh, by the way - we just released that new login service, can you please check if it’s safe” are not unheard of. Especially when the assumption of the development team is that the central security team is accountable for security, while their responsibility just covers the functional aspects: implementing business requirements of the stakeholders and putting the results in front of customers.
From a traditionalist stance, this might look more like anarchy than autonomy.
In your central security team, you might have highly skilled experts, who did spend years earning their CISSP and similar certifications.
You probably don’t have that expertise in your agile teams churning out microservices. Doing DevOps can mean that the Javascript developer is configuring servers now.
Furthermore, traditional security processes often deal with security requirements in software projects using an approach known as the “security sandwich”, as part of the aforementioned control gates: First, the security team specifies the security requirements up-front, then the development team gets to do the implementation, and finally the security team verifies that their requirements have actually been met - sometimes with the help of external penetration testers. Deviations from that are fed back to the development team, and need to be fixed before a final sign-off can happen.
In the worst case, Continuous Delivery can mean that new vulnerabilities are now delivered continuously. It often involves no final sign-off, sometimes not even any human intervention in the case of Continuous Deployment.
So a security team has to resort to fixing things up after the fact, like in a game of whack-a-mole.
Your monolith is probably nicely running on a hardened, well-isolated real host, be it a physical or virtual one. Even if virtual, virtualisation technology has been around for ages and has been in wide use for nearly as long. Your security engineers have made that host bullet proof as part of the security process (one of the gates…), and if there is a patch needed, it is thoroughly tested on a staging system - then on the next “Patch Tuesday” it is rolled out. Life is good.
In contrast, containers can be based on all kinds of different base images, each with their own patches to track. And while containers as a concept have been around for a while, their application in the real world for things like web apps hasn’t seen that much use outside of Google.
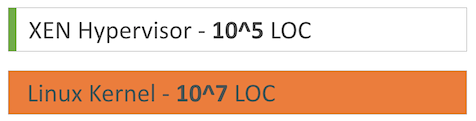
Also, various bugs were discovered in the past, that made breaking out of a container possible. This comes as little surprise, as the Docker daemon itself runs as root, with all containers sharing the same Linux Kernel. If we just compare the lines of code hypervisors like Xen have - a few hundred thousand - to that of the Linux Kernel - around ten million - it is evident that the risk of undiscovered bugs that allow a breakout to the host is just a lot higher with containers.
As you can see, naively jumping on the microservices band-wagon can put you into trouble. But it isn’t as dire as it might seem. The goal of this post was to set the scene and make it clear that the benefits from microservices, like faster time to market and more scalable architectures, don't come for free.
"whack-a-mole" via https://www.flickr.com/photos/jennycu/8195620894 (CC-BY 2.0)
{kind=link}
{kind=link}
{kind=link}
{kind=link}