This series of three blog posts will give readers an overview on why the Raft consensus algorithm is relevant and summarizes the functionality that makes it work. The 3 posts are divided as follows:
Assumptions
The Raft protocol is based on the same set of assumptions as classic Multi-Paxos:
Asynchronicity:
No upper bound on message delays or computation times and no global clock synchronization.
Unreliable Links:
Possibility of indefinite networks delays, packet loss, partitions, reordering, or duplication of messages.
Fail-Crash Failure Model:
Processes may crash, may eventually recover, and in that case rejoin the protocol. Byzantine failures cannot occur.
Ongaro and Ousterhout, the authors of the Raft paper, state that consensus is usually used in the context of replicated state machines. Raft does not apply the idea of consensus to agreeing to single values (like classic Paxos), but instead to the goal of finding agreement on the order with which operations are committed to a single replicated log.
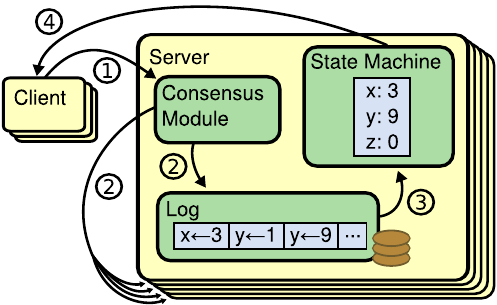
With the objective of implementability in mind, drawing out a protocol that tightly integrates the actual consensus within the common use-case of the replicated state machine makes a lot of sense. Within Raft, the authors draw a clear distinction between the parts of such a replicated state machine: The state machine, the replicated log, and the consensus module.
The clients interact with the replicated state machine through the consensus module, which – once a command has been committed to the log, that is agreed upon by consensus – guarantees that eventually the command will applied in the same order (the one specified in the leader’s log) on every live state machine.
This mimics real-world applications, as they are seen in systems implemented before the publishing of Raft – like ZooKeeper, Chubby, Google File System, or BigTable. Even though aforementioned frameworks do not use Raft, it has been proposed as an alternative for future projects, as the published theoretically grounded specification of the algorithm does not include only the consensus module itself:
Raft integrates consensus with the very common use case of the replicated state machine, giving the advantage that any guarantees proven theoretically will hold in the implementations, if the specification is closely followed. As described in part 1 of this blog series on Raft, it was shown that other consensus algorithm specifications suffered from poor implementability and possible loss of guarantees based on the large gap between theory and implementation practice.
Due to these lines of argumentation, newer implementations – like the one used within Hashicorp's Consul and Nomad – have already switched to Raft as theoretical grounding for their consensus applications.
A fundamental difference between Raft and Paxos as well as Viewstamped Replication, two of the main influences on the protocol, is that Raft implements strong leadership. Contrary to other protocols, who may defer leader election to an oracle (a PhD way of saying magic black box), Raft integrates leader election as an essential part of the consensus protocol. Once a leader has been elected, all decision-making within the protocol will then be driven only by the leader. Only one leader can exist at a single time and log entries can only flow from the leader to the followers.
Strong leadership extends classical leader-driven consensus by adding the following constraints:
To mitigate problems with clock synchronization in asynchronous systems, where the messages – through which clock synchronization may be negotiated – can have arbitrary delays, Raft uses a logical clock in the form of terms. Logical time uses the insight that no exact notion of time is needed to keep track of causality in a system. Each server has its own local view of time that is represented by its currentTerm. This currentTerm number increases monotonically over time, meaning that it can only go up.
Every communication in Raft includes an exchange and comparison of currentTerms. A term is only updated when a server (re-)starts an election or when the currentTerm of the party that a server communicates with is higher than its own, in which case the term get's updated with that higher value. Any communication attempt with a server of a higher term is always rejected and when a candidate or leader learns of a higher term than its own, it immediately returns to being a follower.
The client of the application makes requests only to and gets responses only from the leader server. This means that the replicated state machine service can only be available when a leader has been successfully elected and is alive.
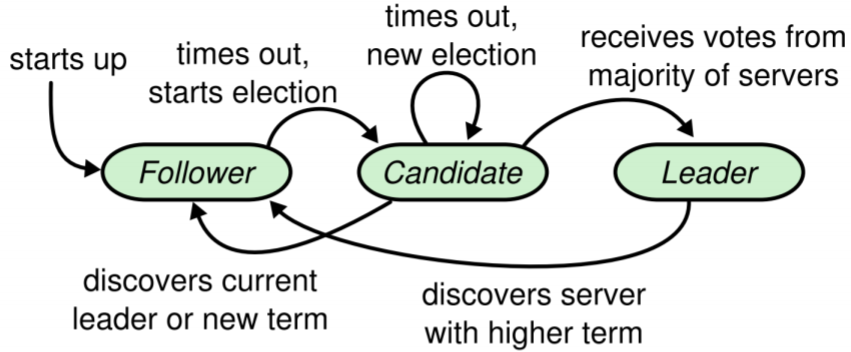
Each server participating in the protocol can only take one of the following roles at a time:
Follower:
Followers only respond to RPCs, but do not initiate any communication.
Candidate:
Candidates start a new election, incrementing the term, requesting a vote, and voting for themselves. Depending on the outcome of the election, become leader, follower (be outvoted or receive RPC from valid leader), or restart these steps (within a new term). Only a candidate with a log that contains all committed commands can become leader.
Leader:
The leader sends heartbeats (empty AppendEntries RPCs) to all followers, thereby preventing timeouts in idle periods. For every command from the client, append to local log and start replicating that log entry, in case of replication on at least a majority of the servers, commit, apply commited entry to its own leader state machine, and then return the result to the client. If logIndex is higher than the nextIndex of a follower, append all log entries at the follower using RPC, starting from the his nextIndex.
All of these roles have a randomized time-out, on the elapse of which all roles assume that the leader has crashed and convert to be candidates, triggering a new election and incrementing the current term.
Once a server is established as leader, it becomes available to serve the clients requests. These requests are commands that are to be committed to the replicated state machine. For every received command, the leader assigns a term and index to the command, which gives a unique identifier within the server’s logs, and appends the command to its own log.
If the leader is then able to replicate the command (through the AppendEntries RPC) across the logs of a strict majority of servers, the command is committed, applied to the leaders state machine, and the result of the operation returned to the client. Once a command is safe to be applied to all replicated state machines, that is when a leader replicates a command from its current term to a majority of servers, it as well as – implicitly – all of the leaders preceding entries are considered committed. (for the curious, see figure 8 in the original Raft paper for a detailed description and illustration why the term is so important)
The unidirectional flow of information from the leader to the followers and therefore the guarantee of identical ordering across all replicated logs on any participating server that is alive, lead to eventually consistent state across all replicated state machines: If a message gets delayed, lost, or a server is temporarily down and later comes back up, the follower will catch back up once he receives the next RPC from the leader. Once the leader becomes aware of the current state of that server through the RPC, it then appends all missing commands. It does so starting from the next expected index to the leader’s current log index, the latter being the last appended position on the leader log.
For every AppendEntries RPC performed on the follower, it performs a consistency check and rejects the new entry only if the logs match in their previous entry. This creates an inductive property: If a follower accepts a new entry from the leader, it checks the consistency the leader’s previous entry with its own, which must have been accepted because of the consistency of the previous entry and so on. Because of this inductive property, the replicated log is guaranteed to match the leader’s log up until that last accepted entry.
Raft assumes that the leader’s log is always correct. The cleanup of inconsistent replicated state happens during normal operation and the protocol is designed in such a way that normal operation (at least half of the servers alive) converges all the logs.
Continue with Part 3/3: Why the algorithm works even on edge cases, with an overview of the algorithm’s safety and liveness properties. This is then followed by the conclusion on the insights gained from looking at the Raft protocol.
In search of an understandable consensus algorithm. Ongaro, Diego, & Ousterhout (2014) USENIX Annual Technical Conference (USENIX ATC 14).
ARC: analysis of Raft consensus. Howard (2014). Technical Report UCAM-CL-TR-857.
Consensus in the Cloud: Paxos Systems Demystified Ailijiang, Charapko, & Demirbas (2016). The 25th International Conference on Computer Communication and Networks (ICCCN).
Paxos made live: an engineering perspective. Chandra, Griesemer, & Redstone (2007). Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing.
Official overview website of materials on and implementations of Raft
Video lecture on Raft: https://youtu.be/YbZ3zDzDnrw
Both of the figures were extracted from the original Raft PhD thesis, figure 1 in this document being figure 2.1 in the original and figure 2 being figure 3.3 in the original.
{kind=link}
{kind=link}